 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastDSAC: Unlocking the Potential of Maximum Entropy RL in High-Dimensional Humanoid Control
Mar 13, 2026Scaling Maximum Entropy Reinforcement Learning (RL) to high-dimensional humanoid control remains a formidable challenge, as the ``curse of dimensionality'' induces severe exploration inefficiency and training instability in expansive action spaces. Consequently, recent high-throughput paradigms have largely converged on deterministic policy gradients combined with massive parallel simulation. We challenge this compromise with FastDSAC, a framework that effectively unlocks the potential of maximum entropy stochastic policies for complex continuous control. We introduce Dimension-wise Entropy Modulation (DEM) to dynamically redistribute the exploration budget and enforce diversity, alongside a continuous distributional critic tailored to ensure value fidelity and mitigate high-dimensional value overestimation. Extensive evaluations on HumanoidBench and other continuous control tasks demonstrate that rigorously designed stochastic policies can consistently match or outperform deterministic baselines, achieving notable gains of 180\% and 400\% on the challenging \textit{Basketball} and \textit{Balance Hard} tasks.
SonicBench: Dissecting the Physical Perception Bottleneck in Large Audio Language Models
Jan 16, 2026Large Audio Language Models (LALMs) excel at semantic and paralinguistic tasks, yet their ability to perceive the fundamental physical attributes of audio such as pitch, loudness, and spatial location remains under-explored. To bridge this gap, we introduce SonicBench, a psychophysically grounded benchmark that systematically evaluates 12 core physical attributes across five perceptual dimensions. Unlike previous datasets, SonicBench uses a controllable generation toolbox to construct stimuli for two complementary paradigms: recognition (absolute judgment) and comparison (relative judgment). This design allows us to probe not only sensory precision but also relational reasoning capabilities, a domain where humans typically exhibit greater proficiency. Our evaluation reveals a substantial deficiency in LALMs' foundational auditory understanding; most models perform near random guessing and, contrary to human patterns, fail to show the expected advantage on comparison tasks. Furthermore, explicit reasoning yields minimal gains. However, our linear probing analysis demonstrates crucially that frozen audio encoders do successfully capture these physical cues (accuracy at least 60%), suggesting that the primary bottleneck lies in the alignment and decoding stages, where models fail to leverage the sensory signals they have already captured.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
PricingLogic: Evaluating LLMs Reasoning on Complex Tourism Pricing Tasks
Oct 14, 2025
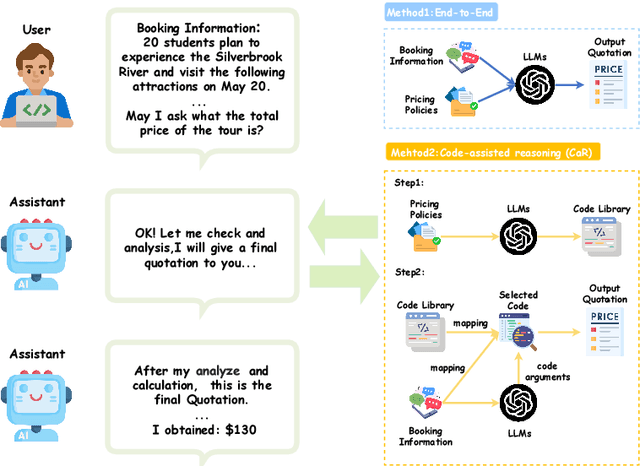


We present PricingLogic, the first benchmark that probes whether Large Language Models(LLMs) can reliably automate tourism-related prices when multiple, overlapping fare rules apply. Travel agencies are eager to offload this error-prone task onto AI systems; however, deploying LLMs without verified reliability could result in significant financial losses and erode customer trust. PricingLogic comprises 300 natural-language questions based on booking requests derived from 42 real-world pricing policies, spanning two levels of difficulty: (i) basic customer-type pricing and (ii)bundled-tour calculations involving interacting discounts. Evaluations of a line of LLMs reveal a steep performance drop on the harder tier,exposing systematic failures in rule interpretation and arithmetic reasoning.These results highlight that, despite their general capabilities, today's LLMs remain unreliable in revenue-critical applications without further safeguards or domain adaptation. Our code and dataset are available at https://github.com/EIT-NLP/PricingLogic.
Reasoning Beyond Language: A Comprehensive Survey on Latent Chain-of-Thought Reasoning
May 22, 2025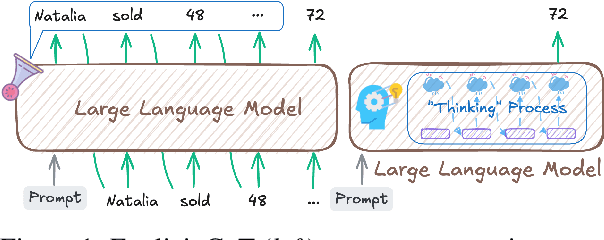

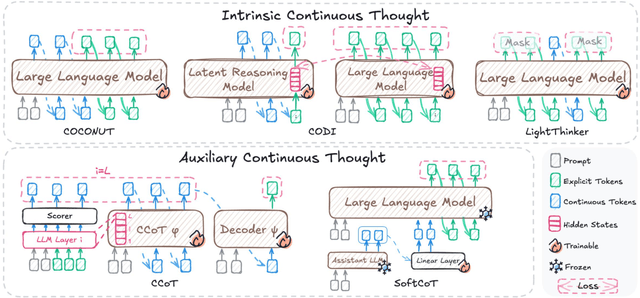
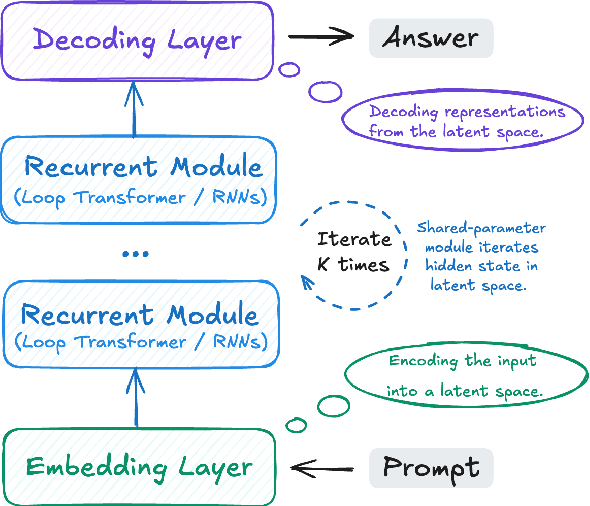
Large Language Models (LLMs) have achieved impressive performance on complex reasoning tasks with Chain-of-Thought (CoT) prompting. However, conventional CoT relies on reasoning steps explicitly verbalized in natural language, introducing inefficiencies and limiting its applicability to abstract reasoning. To address this, there has been growing research interest in latent CoT reasoning, where inference occurs within latent spaces. By decoupling reasoning from language, latent reasoning promises richer cognitive representations and more flexible, faster inference. Researchers have explored various directions in this promising field, including training methodologies, structural innovations, and internal reasoning mechanisms. This paper presents a comprehensive overview and analysis of this reasoning paradigm. We begin by proposing a unified taxonomy from four perspectives: token-wise strategies, internal mechanisms, analysis, and applications. We then provide in-depth discussions and comparative analyses of representative methods, highlighting their design patterns, strengths, and open challenges. We aim to provide a structured foundation for advancing this emerging direction in LLM reasoning. The relevant papers will be regularly updated at https://github.com/EIT-NLP/Awesome-Latent-CoT.
MA-ROESL: Motion-aware Rapid Reward Optimization for Efficient Robot Skill Learning from Single Videos
May 13, 2025Vision-language models (VLMs) have demonstrated excellent high-level planning capabilities, enabling locomotion skill learning from video demonstrations without the need for meticulous human-level reward design. However, the improper frame sampling method and low training efficiency of current methods remain a critical bottleneck, resulting in substantial computational overhead and time costs. To address this limitation, we propose Motion-aware Rapid Reward Optimization for Efficient Robot Skill Learning from Single Videos (MA-ROESL). MA-ROESL integrates a motion-aware frame selection method to implicitly enhance the quality of VLM-generated reward functions. It further employs a hybrid three-phase training pipeline that improves training efficiency via rapid reward optimization and derives the final policy through online fine-tuning. Experimental results demonstrate that MA-ROESL significantly enhances training efficiency while faithfully reproducing locomotion skills in both simulated and real-world settings, thereby underscoring its potential as a robust and scalable framework for efficient robot locomotion skill learning from video demonstrations.
PRISM: Preference Refinement via Implicit Scene Modeling for 3D Vision-Language Preference-Based Reinforcement Learning
Mar 13, 2025



We propose PRISM, a novel framework designed to overcome the limitations of 2D-based Preference-Based Reinforcement Learning (PBRL) by unifying 3D point cloud modeling and future-aware preference refinement. At its core, PRISM adopts a 3D Point Cloud-Language Model (3D-PC-LLM) to mitigate occlusion and viewpoint biases, ensuring more stable and spatially consistent preference signals. Additionally, PRISM leverages Chain-of-Thought (CoT) reasoning to incorporate long-horizon considerations, thereby preventing the short-sighted feedback often seen in static preference comparisons. In contrast to conventional PBRL techniques, this integration of 3D perception and future-oriented reasoning leads to significant gains in preference agreement rates, faster policy convergence, and robust generalization across unseen robotic environments. Our empirical results, spanning tasks such as robotic manipulation and autonomous navigation, highlight PRISM's potential for real-world applications where precise spatial understanding and reliable long-term decision-making are critical. By bridging 3D geometric awareness with CoT-driven preference modeling, PRISM establishes a comprehensive foundation for scalable, human-aligned reinforcement learning.
Integrating Chain-of-Thought for Multimodal Alignment: A Study on 3D Vision-Language Learning
Mar 08, 2025


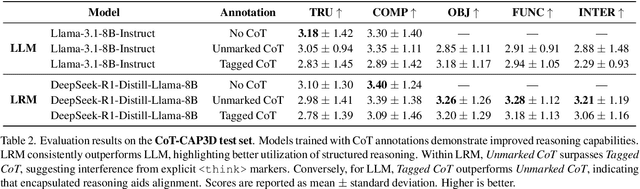
Chain-of-Thought (CoT) reasoning has proven effective in natural language tasks but remains underexplored in multimodal alignment. This study investigates its integration into 3D vision-language learning by embedding structured reasoning into alignment training. We introduce the 3D-CoT Benchmark, a dataset with hierarchical CoT annotations covering shape recognition, functional inference, and causal reasoning. Through controlled experiments, we compare CoT-structured and standard textual annotations across large reasoning models (LRMs) and large language models (LLMs). Our evaluation employs a dual-layer framework assessing both intermediate reasoning and final inference quality. Extensive experiments demonstrate that CoT significantly improves 3D semantic grounding, with LRMs leveraging CoT more effectively than LLMs. Furthermore, we highlight that annotation structure influences performance-explicit reasoning markers aid LLMs, while unmarked CoT better aligns with LRM inference patterns. Our analyses suggest that CoT is crucial for enhancing multimodal reasoning, with implications beyond 3D tasks.
Unveiling the Key Factors for Distilling Chain-of-Thought Reasoning
Feb 25, 2025



Large Language Models (LLMs) excel in reasoning tasks through Chain-of-Thought (CoT) prompting. However, CoT prompting greatly increases computational demands, which has prompted growing interest in distilling CoT capabilities into Small Language Models (SLMs). This study systematically examines the factors influencing CoT distillation, including the choice of granularity, format and teacher model. Through experiments involving four teacher models and seven student models across seven mathematical and commonsense reasoning datasets, we uncover three key findings: (1) Unlike LLMs, SLMs exhibit a non-monotonic relationship with granularity, with stronger models benefiting from finer-grained reasoning and weaker models performing better with simpler CoT supervision; (2) CoT format significantly impacts LLMs but has minimal effect on SLMs, likely due to their reliance on supervised fine-tuning rather than pretraining preferences; (3) Stronger teacher models do NOT always produce better student models, as diversity and complexity in CoT supervision can outweigh accuracy alone. These findings emphasize the need to tailor CoT strategies to specific student model, offering actionable insights for optimizing CoT distillation in SLMs. The code and datasets are available at https://github.com/EIT-NLP/Distilling-CoT-Reasoning.
Instruction-Tuned LLMs Succeed in Document-Level MT Without Fine-Tuning -- But BLEU Turns a Blind Eye
Oct 29, 2024
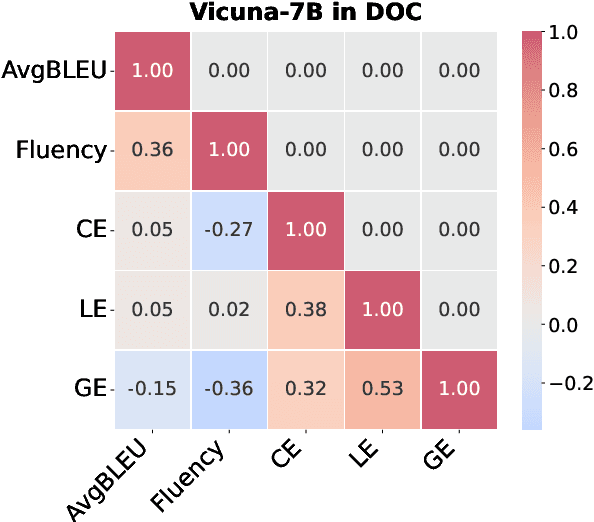
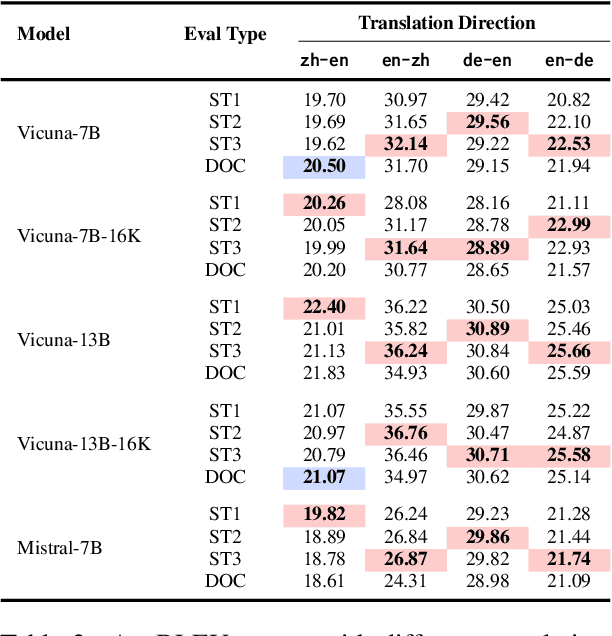
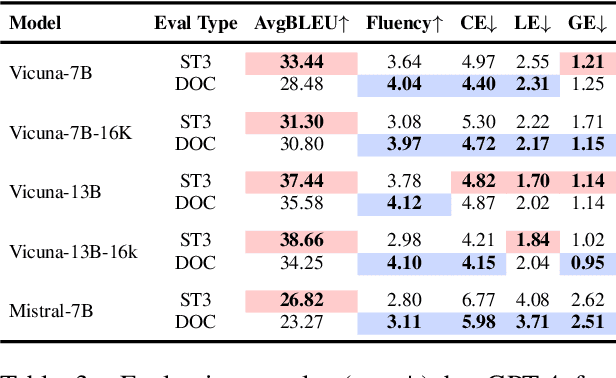
Large language models (LLMs) have excelled in various NLP tasks, including machine translation (MT), yet most studies focus on sentence-level translation. This work investigates the inherent capability of instruction-tuned LLMs for document-level translation (docMT). Unlike prior approaches that require specialized techniques, we evaluate LLMs by directly prompting them to translate entire documents in a single pass. Our results show that this method improves translation quality compared to translating sentences separately, even without document-level fine-tuning. However, this advantage is not reflected in BLEU scores, which often favor sentence-based translations. We propose using the LLM-as-a-judge paradigm for evaluation, where GPT-4 is used to assess document coherence, accuracy, and fluency in a more nuanced way than n-gram-based metrics. Overall, our work demonstrates that instruction-tuned LLMs can effectively leverage document context for translation. However, we caution against using BLEU scores for evaluating docMT, as they often provide misleading outcomes, failing to capture the quality of document-level translation. Code and data are available at https://github.com/EIT-NLP/BLEUless_DocMT