 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClawBench: Can AI Agents Complete Everyday Online Tasks?
Apr 09, 2026AI agents may be able to automate your inbox, but can they automate other routine aspects of your life? Everyday online tasks offer a realistic yet unsolved testbed for evaluating the next generation of AI agents. To this end, we introduce ClawBench, an evaluation framework of 153 simple tasks that people need to accomplish regularly in their lives and work, spanning 144 live platforms across 15 categories, from completing purchases and booking appointments to submitting job applications. These tasks require demanding capabilities beyond existing benchmarks, such as obtaining relevant information from user-provided documents, navigating multi-step workflows across diverse platforms, and write-heavy operations like filling in many detailed forms correctly. Unlike existing benchmarks that evaluate agents in offline sandboxes with static pages, ClawBench operates on production websites, preserving the full complexity, dynamic nature, and challenges of real-world web interaction. A lightweight interception layer captures and blocks only the final submission request, ensuring safe evaluation without real-world side effects. Our evaluations of 7 frontier models show that both proprietary and open-source models can complete only a small portion of these tasks. For example, Claude Sonnet 4.6 achieves only 33.3%. Progress on ClawBench brings us closer to AI agents that can function as reliable general-purpose assistants.
Digital Skin, Digital Bias: Uncovering Tone-Based Biases in LLMs and Emoji Embeddings
Apr 08, 2026Skin-toned emojis are crucial for fostering personal identity and social inclusion in online communication. As AI models, particularly Large Language Models (LLMs), increasingly mediate interactions on web platforms, the risk that these systems perpetuate societal biases through their representation of such symbols is a significant concern. This paper presents the first large-scale comparative study of bias in skin-toned emoji representations across two distinct model classes. We systematically evaluate dedicated emoji embedding models (emoji2vec, emoji-sw2v) against four modern LLMs (Llama, Gemma, Qwen, and Mistral). Our analysis first reveals a critical performance gap: while LLMs demonstrate robust support for skin tone modifiers, widely-used specialized emoji models exhibit severe deficiencies. More importantly, a multi-faceted investigation into semantic consistency, representational similarity, sentiment polarity, and core biases uncovers systemic disparities. We find evidence of skewed sentiment and inconsistent meanings associated with emojis across different skin tones, highlighting latent biases within these foundational models. Our findings underscore the urgent need for developers and platforms to audit and mitigate these representational harms, ensuring that AI's role on the web promotes genuine equity rather than reinforcing societal biases.
Beyond Global Similarity: Towards Fine-Grained, Multi-Condition Multimodal Retrieval
Mar 01, 2026Recent advances in multimodal large language models (MLLMs) have substantially expanded the capabilities of multimodal retrieval, enabling systems to align and retrieve information across visual and textual modalities. Yet, existing benchmarks largely focus on coarse-grained or single-condition alignment, overlooking real-world scenarios where user queries specify multiple interdependent constraints across modalities. To bridge this gap, we introduce MCMR (Multi-Conditional Multimodal Retrieval): a large-scale benchmark designed to evaluate fine-grained, multi-condition cross-modal retrieval under natural-language queries. MCMR spans five product domains: upper and bottom clothing, jewelry, shoes, and furniture. It also preserves rich long-form metadata essential for compositional matching. Each query integrates complementary visual and textual attributes, requiring models to jointly satisfy all specified conditions for relevance. We benchmark a diverse suite of MLLM-based multimodal retrievers and vision-language rerankers to assess their condition-aware reasoning abilities. Experimental results reveal: (i) distinct modality asymmetries across models; (ii) visual cues dominate early-rank precision, while textual metadata stabilizes long-tail ordering; and (iii) MLLM-based pointwise rerankers markedly improve fine-grained matching by explicitly verifying query-candidate consistency. Overall, MCMR establishes a challenging and diagnostic benchmark for advancing multimodal retrieval toward compositional, constraint-aware, and interpretable understanding. Our code and dataset is available at https://github.com/EIT-NLP/MCMR
LLM-based Semantic Search for Conversational Queries in E-commerce
Jan 23, 2026Conversational user queries are increasingly challenging traditional e-commerce platforms, whose search systems are typically optimized for keyword-based queries. We present an LLM-based semantic search framework that effectively captures user intent from conversational queries by combining domain-specific embeddings with structured filters. To address the challenge of limited labeled data, we generate synthetic data using LLMs to guide the fine-tuning of two models: an embedding model that positions semantically similar products close together in the representation space, and a generative model for converting natural language queries into structured constraints. By combining similarity-based retrieval with constraint-based filtering, our framework achieves strong precision and recall across various settings compared to baseline approaches on a real-world dataset.
Tools are under-documented: Simple Document Expansion Boosts Tool Retrieval
Oct 26, 2025Large Language Models (LLMs) have recently demonstrated strong capabilities in tool use, yet progress in tool retrieval remains hindered by incomplete and heterogeneous tool documentation. To address this challenge, we introduce Tool-DE, a new benchmark and framework that systematically enriches tool documentation with structured fields to enable more effective tool retrieval, together with two dedicated models, Tool-Embed and Tool-Rank. We design a scalable document expansion pipeline that leverages both open- and closed-source LLMs to generate, validate, and refine enriched tool profiles at low cost, producing large-scale corpora with 50k instances for embedding-based retrievers and 200k for rerankers. On top of this data, we develop two models specifically tailored for tool retrieval: Tool-Embed, a dense retriever, and Tool-Rank, an LLM-based reranker. Extensive experiments on ToolRet and Tool-DE demonstrate that document expansion substantially improves retrieval performance, with Tool-Embed and Tool-Rank achieving new state-of-the-art results on both benchmarks. We further analyze the contribution of individual fields to retrieval effectiveness, as well as the broader impact of document expansion on both training and evaluation. Overall, our findings highlight both the promise and limitations of LLM-driven document expansion, positioning Tool-DE, along with the proposed Tool-Embed and Tool-Rank, as a foundation for future research in tool retrieval.
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Jun 16, 2025



We introduce MiniMax-M1, the world's first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning attention mechanism. The model is developed based on our previous MiniMax-Text-01 model, which contains a total of 456 billion parameters with 45.9 billion parameters activated per token. The M1 model natively supports a context length of 1 million tokens, 8x the context size of DeepSeek R1. Furthermore, the lightning attention mechanism in MiniMax-M1 enables efficient scaling of test-time compute. These properties make M1 particularly suitable for complex tasks that require processing long inputs and thinking extensively. MiniMax-M1 is trained using large-scale reinforcement learning (RL) on diverse problems including sandbox-based, real-world software engineering environments. In addition to M1's inherent efficiency advantage for RL training, we propose CISPO, a novel RL algorithm to further enhance RL efficiency. CISPO clips importance sampling weights rather than token updates, outperforming other competitive RL variants. Combining hybrid-attention and CISPO enables MiniMax-M1's full RL training on 512 H800 GPUs to complete in only three weeks, with a rental cost of just $534,700. We release two versions of MiniMax-M1 models with 40K and 80K thinking budgets respectively, where the 40K model represents an intermediate phase of the 80K training. Experiments on standard benchmarks show that our models are comparable or superior to strong open-weight models such as the original DeepSeek-R1 and Qwen3-235B, with particular strengths in complex software engineering, tool utilization, and long-context tasks. We publicly release MiniMax-M1 at https://github.com/MiniMax-AI/MiniMax-M1.
Reasoning Beyond Language: A Comprehensive Survey on Latent Chain-of-Thought Reasoning
May 22, 2025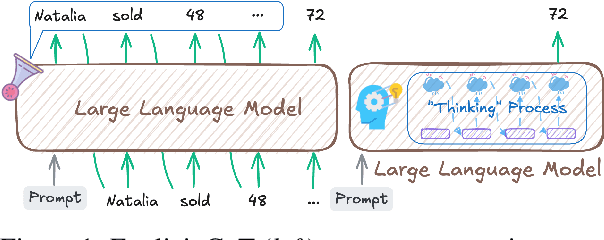

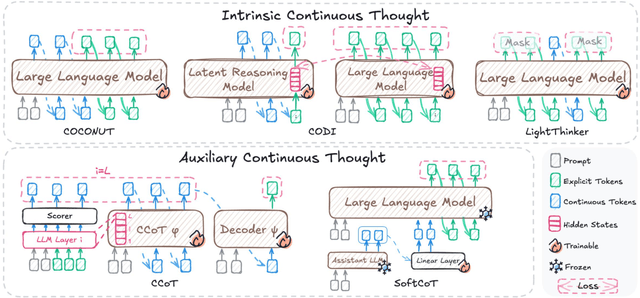
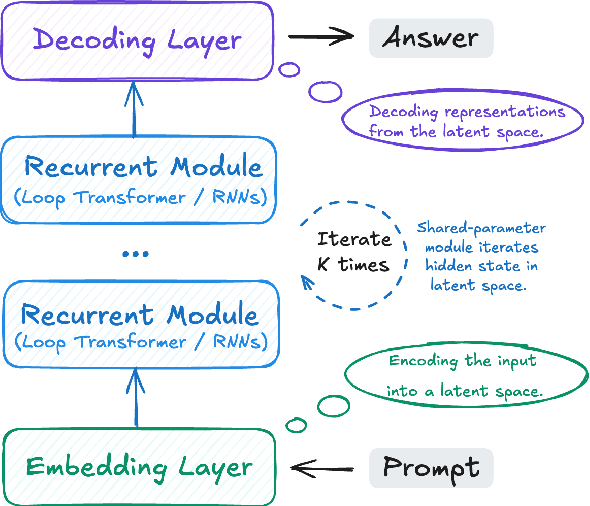
Large Language Models (LLMs) have achieved impressive performance on complex reasoning tasks with Chain-of-Thought (CoT) prompting. However, conventional CoT relies on reasoning steps explicitly verbalized in natural language, introducing inefficiencies and limiting its applicability to abstract reasoning. To address this, there has been growing research interest in latent CoT reasoning, where inference occurs within latent spaces. By decoupling reasoning from language, latent reasoning promises richer cognitive representations and more flexible, faster inference. Researchers have explored various directions in this promising field, including training methodologies, structural innovations, and internal reasoning mechanisms. This paper presents a comprehensive overview and analysis of this reasoning paradigm. We begin by proposing a unified taxonomy from four perspectives: token-wise strategies, internal mechanisms, analysis, and applications. We then provide in-depth discussions and comparative analyses of representative methods, highlighting their design patterns, strengths, and open challenges. We aim to provide a structured foundation for advancing this emerging direction in LLM reasoning. The relevant papers will be regularly updated at https://github.com/EIT-NLP/Awesome-Latent-CoT.
MultiConIR: Towards multi-condition Information Retrieval
Mar 11, 2025



In this paper, we introduce MultiConIR, the first benchmark designed to evaluate retrieval models in multi-condition scenarios. Unlike existing datasets that primarily focus on single-condition queries from search engines, MultiConIR captures real-world complexity by incorporating five diverse domains: books, movies, people, medical cases, and legal documents. We propose three tasks to systematically assess retrieval and reranking models on multi-condition robustness, monotonic relevance ranking, and query format sensitivity. Our findings reveal that existing retrieval and reranking models struggle with multi-condition retrieval, with rerankers suffering severe performance degradation as query complexity increases. We further investigate the performance gap between retrieval and reranking models, exploring potential reasons for these discrepancies, and analysis the impact of different pooling strategies on condition placement sensitivity. Finally, we highlight the strengths of GritLM and Nv-Embed, which demonstrate enhanced adaptability to multi-condition queries, offering insights for future retrieval models. The code and datasets are available at https://github.com/EIT-NLP/MultiConIR.
Fire-Flyer AI-HPC: A Cost-Effective Software-Hardware Co-Design for Deep Learning
Aug 26, 2024



The rapid progress in Deep Learning (DL) and Large Language Models (LLMs) has exponentially increased demands of computational power and bandwidth. This, combined with the high costs of faster computing chips and interconnects, has significantly inflated High Performance Computing (HPC) construction costs. To address these challenges, we introduce the Fire-Flyer AI-HPC architecture, a synergistic hardware-software co-design framework and its best practices. For DL training, we deployed the Fire-Flyer 2 with 10,000 PCIe A100 GPUs, achieved performance approximating the DGX-A100 while reducing costs by half and energy consumption by 40%. We specifically engineered HFReduce to accelerate allreduce communication and implemented numerous measures to keep our Computation-Storage Integrated Network congestion-free. Through our software stack, including HaiScale, 3FS, and HAI-Platform, we achieved substantial scalability by overlapping computation and communication. Our system-oriented experience from DL training provides valuable insights to drive future advancements in AI-HPC.
DeepSeek-Prover-V1.5: Harnessing Proof Assistant Feedback for Reinforcement Learning and Monte-Carlo Tree Search
Aug 15, 2024



We introduce DeepSeek-Prover-V1.5, an open-source language model designed for theorem proving in Lean 4, which enhances DeepSeek-Prover-V1 by optimizing both training and inference processes. Pre-trained on DeepSeekMath-Base with specialization in formal mathematical languages, the model undergoes supervised fine-tuning using an enhanced formal theorem proving dataset derived from DeepSeek-Prover-V1. Further refinement is achieved through reinforcement learning from proof assistant feedback (RLPAF). Beyond the single-pass whole-proof generation approach of DeepSeek-Prover-V1, we propose RMaxTS, a variant of Monte-Carlo tree search that employs an intrinsic-reward-driven exploration strategy to generate diverse proof paths. DeepSeek-Prover-V1.5 demonstrates significant improvements over DeepSeek-Prover-V1, achieving new state-of-the-art results on the test set of the high school level miniF2F benchmark ($63.5\%$) and the undergraduate level ProofNet benchmark ($25.3\%$).