 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference-Time Scaling for Generalist Reward Modeling
Apr 03, 2025Reinforcement learning (RL) has been widely adopted in post-training for large language models (LLMs) at scale. Recently, the incentivization of reasoning capabilities in LLMs from RL indicates that $\textit{proper learning methods could enable effective inference-time scalability}$. A key challenge of RL is to obtain accurate reward signals for LLMs in various domains beyond verifiable questions or artificial rules. In this work, we investigate how to improve reward modeling (RM) with more inference compute for general queries, i.e. the $\textbf{inference-time scalability of generalist RM}$, and further, how to improve the effectiveness of performance-compute scaling with proper learning methods. For the RM approach, we adopt pointwise generative reward modeling (GRM) to enable flexibility for different input types and potential for inference-time scaling. For the learning method, we propose Self-Principled Critique Tuning (SPCT) to foster scalable reward generation behaviors in GRMs through online RL, to generate principles adaptively and critiques accurately, resulting in $\textbf{DeepSeek-GRM}$ models. Furthermore, for effective inference-time scaling, we use parallel sampling to expand compute usage, and introduce a meta RM to guide voting process for better scaling performance. Empirically, we show that SPCT significantly improves the quality and scalability of GRMs, outperforming existing methods and models in various RM benchmarks without severe biases, and could achieve better performance compared to training-time scaling. DeepSeek-GRM still meets challenges in some tasks, which we believe can be addressed by future efforts in generalist reward systems. The models will be released and open-sourced.
CodeI/O: Condensing Reasoning Patterns via Code Input-Output Prediction
Feb 12, 2025Reasoning is a fundamental capability of Large Language Models. While prior research predominantly focuses on enhancing narrow skills like math or code generation, improving performance on many other reasoning tasks remains challenging due to sparse and fragmented training data. To address this issue, we propose CodeI/O, a novel approach that systematically condenses diverse reasoning patterns inherently embedded in contextually-grounded codes, through transforming the original code into a code input-output prediction format. By training models to predict inputs/outputs given code and test cases entirely in natural language as Chain-of-Thought (CoT) rationales, we expose them to universal reasoning primitives -- like logic flow planning, state-space searching, decision tree traversal, and modular decomposition -- while decoupling structured reasoning from code-specific syntax and preserving procedural rigor. Experimental results demonstrate CodeI/O leads to consistent improvements across symbolic, scientific, logic, math & numerical, and commonsense reasoning tasks. By matching the existing ground-truth outputs or re-executing the code with predicted inputs, we can verify each prediction and further enhance the CoTs through multi-turn revision, resulting in CodeI/O++ and achieving higher performance. Our data and models are available at https://github.com/hkust-nlp/CodeIO.
DeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
Omni-MATH: A Universal Olympiad Level Mathematic Benchmark For Large Language Models
Oct 10, 2024
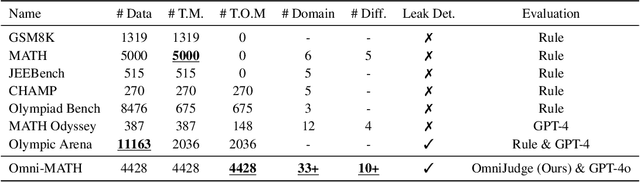

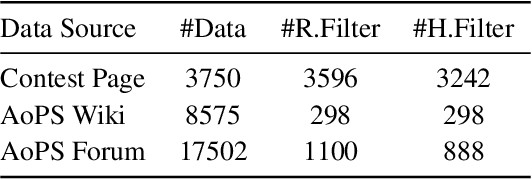
Recent advancements in large language models (LLMs) have led to significant breakthroughs in mathematical reasoning capabilities. However, existing benchmarks like GSM8K or MATH are now being solved with high accuracy (e.g., OpenAI o1 achieves 94.8% on MATH dataset), indicating their inadequacy for truly challenging these models. To bridge this gap, we propose a comprehensive and challenging benchmark specifically designed to assess LLMs' mathematical reasoning at the Olympiad level. Unlike existing Olympiad-related benchmarks, our dataset focuses exclusively on mathematics and comprises a vast collection of 4428 competition-level problems with rigorous human annotation. These problems are meticulously categorized into over 33 sub-domains and span more than 10 distinct difficulty levels, enabling a holistic assessment of model performance in Olympiad-mathematical reasoning. Furthermore, we conducted an in-depth analysis based on this benchmark. Our experimental results show that even the most advanced models, OpenAI o1-mini and OpenAI o1-preview, struggle with highly challenging Olympiad-level problems, with 60.54% and 52.55% accuracy, highlighting significant challenges in Olympiad-level mathematical reasoning.
Towards a Unified View of Preference Learning for Large Language Models: A Survey
Sep 04, 2024

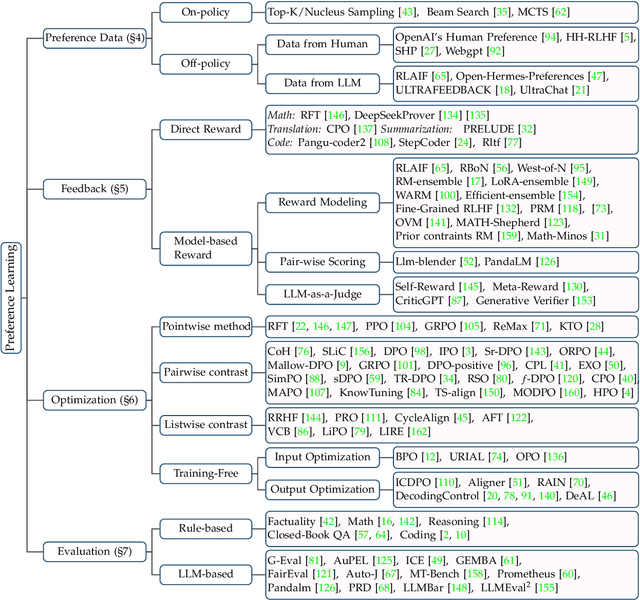
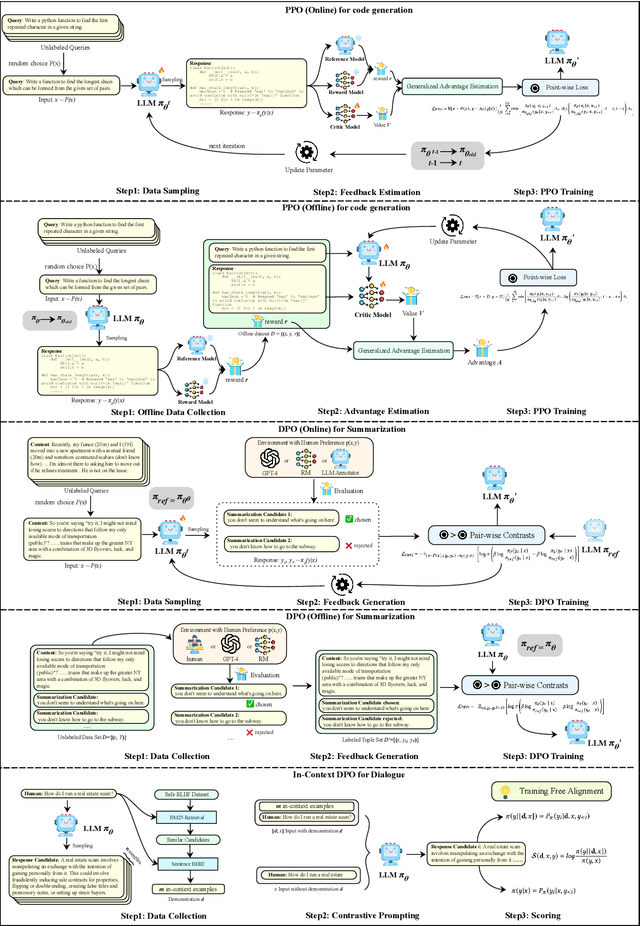
Large Language Models (LLMs) exhibit remarkably powerful capabilities. One of the crucial factors to achieve success is aligning the LLM's output with human preferences. This alignment process often requires only a small amount of data to efficiently enhance the LLM's performance. While effective, research in this area spans multiple domains, and the methods involved are relatively complex to understand. The relationships between different methods have been under-explored, limiting the development of the preference alignment. In light of this, we break down the existing popular alignment strategies into different components and provide a unified framework to study the current alignment strategies, thereby establishing connections among them. In this survey, we decompose all the strategies in preference learning into four components: model, data, feedback, and algorithm. This unified view offers an in-depth understanding of existing alignment algorithms and also opens up possibilities to synergize the strengths of different strategies. Furthermore, we present detailed working examples of prevalent existing algorithms to facilitate a comprehensive understanding for the readers. Finally, based on our unified perspective, we explore the challenges and future research directions for aligning large language models with human preferences.
Let the Expert Stick to His Last: Expert-Specialized Fine-Tuning for Sparse Architectural Large Language Models
Jul 02, 2024
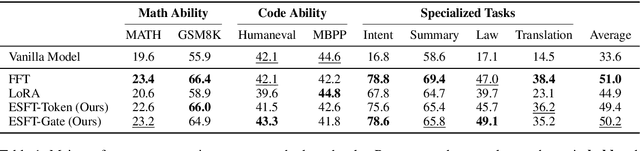
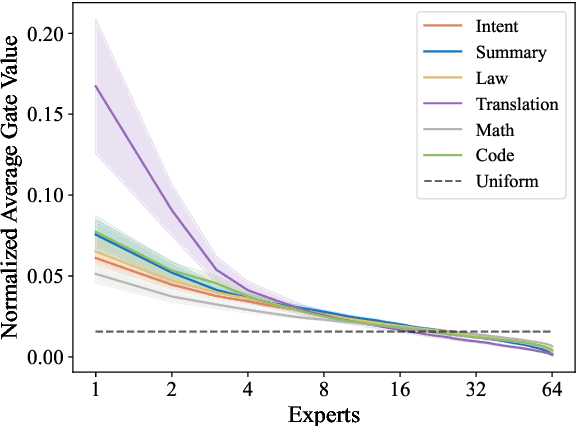

Parameter-efficient fine-tuning (PEFT) is crucial for customizing Large Language Models (LLMs) with constrained resources. Although there have been various PEFT methods for dense-architecture LLMs, PEFT for sparse-architecture LLMs is still underexplored. In this work, we study the PEFT method for LLMs with the Mixture-of-Experts (MoE) architecture and the contents of this work are mainly threefold: (1) We investigate the dispersion degree of the activated experts in customized tasks, and found that the routing distribution for a specific task tends to be highly concentrated, while the distribution of activated experts varies significantly across different tasks. (2) We propose Expert-Specialized Fine-Tuning, or ESFT, which tunes the experts most relevant to downstream tasks while freezing the other experts and modules; experimental results demonstrate that our method not only improves the tuning efficiency, but also matches or even surpasses the performance of full-parameter fine-tuning. (3) We further analyze the impact of the MoE architecture on expert-specialized fine-tuning. We find that MoE models with finer-grained experts are more advantageous in selecting the combination of experts that are most relevant to downstream tasks, thereby enhancing both the training efficiency and effectiveness.
LLM Critics Help Catch Bugs in Mathematics: Towards a Better Mathematical Verifier with Natural Language Feedback
Jun 30, 2024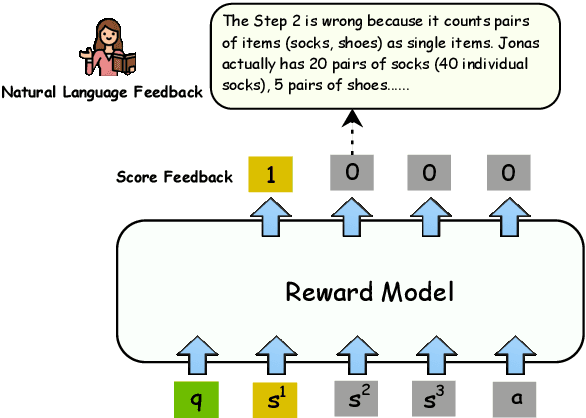
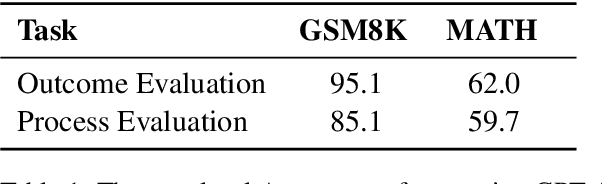
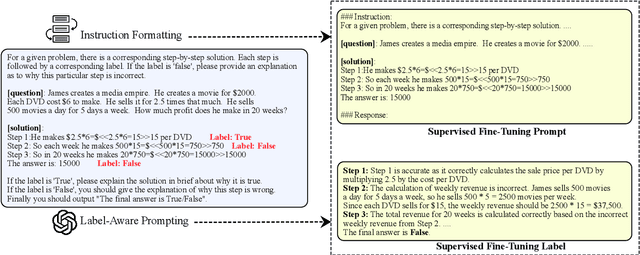

Mathematical verfier achieves success in mathematical reasoning tasks by validating the correctness of solutions. However, existing verifiers are trained with binary classification labels, which are not informative enough for the model to accurately assess the solutions. To mitigate the aforementioned insufficiency of binary labels, we introduce step-wise natural language feedbacks as rationale labels (i.e., the correctness of the current step and the explanations). In this paper, we propose \textbf{Math-Minos}, a natural language feedback enhanced verifier by constructing automatically-generated training data and a two-stage training paradigm for effective training and efficient inference. Our experiments reveal that a small set (30k) of natural language feedbacks can significantly boost the performance of the verifier by the accuracy of 1.6\% (86.6\% $\rightarrow$ 88.2\%) on GSM8K and 0.8\% (37.8\% $\rightarrow$ 38.6\%) on MATH. We have released our code and data for further exploration.
The Reason behind Good or Bad: Towards a Better Mathematical Verifier with Natural Language Feedback
Jun 20, 2024Mathematical verfier achieves success in mathematical reasoning tasks by validating the correctness of solutions. However, existing verifiers are trained with binary classification labels, which are not informative enough for the model to accurately assess the solutions. To mitigate the aforementioned insufficiency of binary labels, we introduce step-wise natural language feedbacks as rationale labels (i.e., the correctness of the current step and the explanations). In this paper, we propose \textbf{Math-Minos}, a natural language feedback enhanced verifier by constructing automatically-generated training data and a two-stage training paradigm for effective training and efficient inference. Our experiments reveal that a small set (30k) of natural language feedbacks can significantly boost the performance of the verifier by the accuracy of 1.6\% (86.6\% $\rightarrow$ 88.2\%) on GSM8K and 0.8\% (37.8\% $\rightarrow$ 38.6\%) on MATH. We will release the code, data and model for reproduction soon.
DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence
Jun 17, 2024



We present DeepSeek-Coder-V2, an open-source Mixture-of-Experts (MoE) code language model that achieves performance comparable to GPT4-Turbo in code-specific tasks. Specifically, DeepSeek-Coder-V2 is further pre-trained from an intermediate checkpoint of DeepSeek-V2 with additional 6 trillion tokens. Through this continued pre-training, DeepSeek-Coder-V2 substantially enhances the coding and mathematical reasoning capabilities of DeepSeek-V2, while maintaining comparable performance in general language tasks. Compared to DeepSeek-Coder-33B, DeepSeek-Coder-V2 demonstrates significant advancements in various aspects of code-related tasks, as well as reasoning and general capabilities. Additionally, DeepSeek-Coder-V2 expands its support for programming languages from 86 to 338, while extending the context length from 16K to 128K. In standard benchmark evaluations, DeepSeek-Coder-V2 achieves superior performance compared to closed-source models such as GPT4-Turbo, Claude 3 Opus, and Gemini 1.5 Pro in coding and math benchmarks.
Multimodal ArXiv: A Dataset for Improving Scientific Comprehension of Large Vision-Language Models
Mar 04, 2024



Large vision-language models (LVLMs), exemplified by GPT-4V, excel across diverse tasks involving concrete images from natural scenes. However, their ability to interpret abstract figures, such as geometry shapes and scientific plots, remains limited due to a scarcity of training datasets in scientific domains. To fill this gap, we introduce Multimodal ArXiv, consisting of ArXivCap and ArXivQA, for enhancing LVLMs scientific comprehension. ArXivCap is a figure-caption dataset comprising 6.4M images and 3.9M captions sourced from 572K ArXiv papers spanning various scientific domains. Drawing from ArXivCap, we introduce ArXivQA, a question-answering dataset generated by prompting GPT-4V based on scientific figures. ArXivQA greatly enhances LVLMs' mathematical reasoning capabilities, achieving a 10.4% absolute accuracy gain on a multimodal mathematical reasoning benchmark. Furthermore, employing ArXivCap, we devise four vision-to-text tasks for benchmarking LVLMs. Evaluation results with state-of-the-art LVLMs underscore their struggle with the nuanced semantics of academic figures, with domain-specific training yielding substantial performance gains. Our error analysis uncovers misinterpretations of visual context, recognition errors, and the production of overly simplified captions by current LVLMs, shedding light on future improvements.