 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillCraft: Can LLM Agents Learn to Use Tools Skillfully?
Feb 28, 2026Real-world tool-using agents operate over long-horizon workflows with recurring structure and diverse demands, where effective behavior requires not only invoking atomic tools but also abstracting, and reusing higher-level tool compositions. However, existing benchmarks mainly measure instance-level success under static tool sets, offering limited insight into agents' ability to acquire such reusable skills. We address this gap by introducing SkillCraft, a benchmark explicitly stress-test agent ability to form and reuse higher-level tool compositions, where we call Skills. SkillCraft features realistic, highly compositional tool-use scenarios with difficulty scaled along both quantitative and structural dimensions, designed to elicit skill abstraction and cross-task reuse. We further propose a lightweight evaluation protocol that enables agents to auto-compose atomic tools into executable Skills, cache and reuse them inside and across tasks, thereby improving efficiency while accumulating a persistent library of reusable skills. Evaluating state-of-the-art agents on SkillCraft, we observe substantial efficiency gains, with token usage reduced by up to 80% by skill saving and reuse. Moreover, success rate strongly correlates with tool composition ability at test time, underscoring compositional skill acquisition as a core capability.
Building Egocentric Procedural AI Assistant: Methods, Benchmarks, and Challenges
Nov 17, 2025Driven by recent advances in vision language models (VLMs) and egocentric perception research, we introduce the concept of an egocentric procedural AI assistant (EgoProceAssist) tailored to step-by-step support daily procedural tasks in a first-person view. In this work, we start by identifying three core tasks: egocentric procedural error detection, egocentric procedural learning, and egocentric procedural question answering. These tasks define the essential functions of EgoProceAssist within a new taxonomy. Specifically, our work encompasses a comprehensive review of current techniques, relevant datasets, and evaluation metrics across these three core areas. To clarify the gap between the proposed EgoProceAssist and existing VLM-based AI assistants, we introduce novel experiments and provide a comprehensive evaluation of representative VLM-based methods. Based on these findings and our technical analysis, we discuss the challenges ahead and suggest future research directions. Furthermore, an exhaustive list of this study is publicly available in an active repository that continuously collects the latest work: https://github.com/z1oong/Building-Egocentric-Procedural-AI-Assistant
The Tool Decathlon: Benchmarking Language Agents for Diverse, Realistic, and Long-Horizon Task Execution
Oct 29, 2025Real-world language agents must handle complex, multi-step workflows across diverse Apps. For instance, an agent may manage emails by coordinating with calendars and file systems, or monitor a production database to detect anomalies and generate reports following an operating manual. However, existing language agent benchmarks often focus on narrow domains or simplified tasks that lack the diversity, realism, and long-horizon complexity required to evaluate agents' real-world performance. To address this gap, we introduce the Tool Decathlon (dubbed as Toolathlon), a benchmark for language agents offering diverse Apps and tools, realistic environment setup, and reliable execution-based evaluation. Toolathlon spans 32 software applications and 604 tools, ranging from everyday platforms such as Google Calendar and Notion to professional ones like WooCommerce, Kubernetes, and BigQuery. Most of the tools are based on a high-quality set of Model Context Protocol (MCP) servers that we may have revised or implemented ourselves. Unlike prior works, which primarily ensure functional realism but offer limited environment state diversity, we provide realistic initial environment states from real software, such as Canvas courses with dozens of students or real financial spreadsheets. This benchmark includes 108 manually sourced or crafted tasks in total, requiring interacting with multiple Apps over around 20 turns on average to complete. Each task is strictly verifiable through dedicated evaluation scripts. Comprehensive evaluation of SOTA models highlights their significant shortcomings: the best-performing model, Claude-4.5-Sonnet, achieves only a 38.6% success rate with 20.2 tool calling turns on average, while the top open-weights model DeepSeek-V3.2-Exp reaches 20.1%. We expect Toolathlon to drive the development of more capable language agents for real-world, long-horizon task execution.
CodeI/O: Condensing Reasoning Patterns via Code Input-Output Prediction
Feb 12, 2025Reasoning is a fundamental capability of Large Language Models. While prior research predominantly focuses on enhancing narrow skills like math or code generation, improving performance on many other reasoning tasks remains challenging due to sparse and fragmented training data. To address this issue, we propose CodeI/O, a novel approach that systematically condenses diverse reasoning patterns inherently embedded in contextually-grounded codes, through transforming the original code into a code input-output prediction format. By training models to predict inputs/outputs given code and test cases entirely in natural language as Chain-of-Thought (CoT) rationales, we expose them to universal reasoning primitives -- like logic flow planning, state-space searching, decision tree traversal, and modular decomposition -- while decoupling structured reasoning from code-specific syntax and preserving procedural rigor. Experimental results demonstrate CodeI/O leads to consistent improvements across symbolic, scientific, logic, math & numerical, and commonsense reasoning tasks. By matching the existing ground-truth outputs or re-executing the code with predicted inputs, we can verify each prediction and further enhance the CoTs through multi-turn revision, resulting in CodeI/O++ and achieving higher performance. Our data and models are available at https://github.com/hkust-nlp/CodeIO.
DeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
Diving into Self-Evolving Training for Multimodal Reasoning
Dec 23, 2024



Reasoning ability is essential for Large Multimodal Models (LMMs). In the absence of multimodal chain-of-thought annotated data, self-evolving training, where the model learns from its own outputs, has emerged as an effective and scalable approach for enhancing reasoning abilities. Despite its growing usage, a comprehensive understanding of self-evolving training, particularly in the context of multimodal reasoning, remains limited. In this paper, we delve into the intricacies of self-evolving training for multimodal reasoning, pinpointing three key factors: Training Method, Reward Model, and Prompt Variation. We systematically examine each factor and explore how various configurations affect the training's effectiveness. Our analysis leads to a set of best practices for each factor, aimed at optimizing multimodal reasoning. Furthermore, we explore the Self-Evolution Dynamics during training and the impact of automatic balancing mechanisms in boosting performance. After all the investigations, we present a final recipe for self-evolving training in multimodal reasoning, encapsulating these design choices into a framework we call MSTaR (Multimodal Self-evolving Training for Reasoning), which is universally effective for models with different sizes on various benchmarks, e.g., surpassing the pre-evolved model significantly on 5 multimodal reasoning benchmarks without using additional human annotations, as demonstrated on MiniCPM-V-2.5 (8B), Phi-3.5-Vision (4B) and InternVL2 (2B). We believe this study fills a significant gap in the understanding of self-evolving training for multimodal reasoning and offers a robust framework for future research. Our policy and reward models, as well as the collected data, is released to facilitate further investigation in multimodal reasoning.
Programming Every Example: Lifting Pre-training Data Quality like Experts at Scale
Sep 25, 2024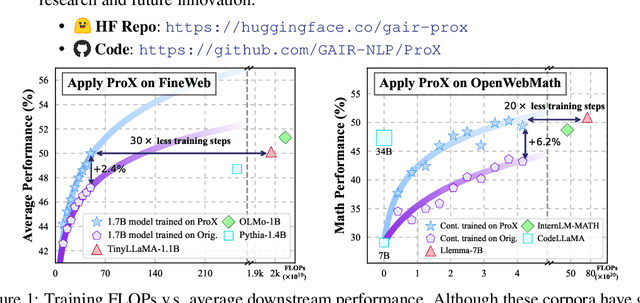

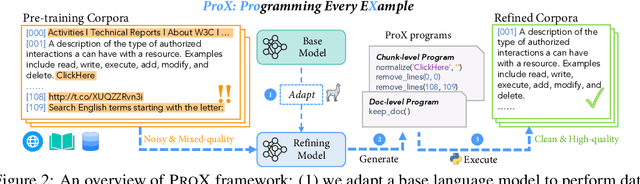
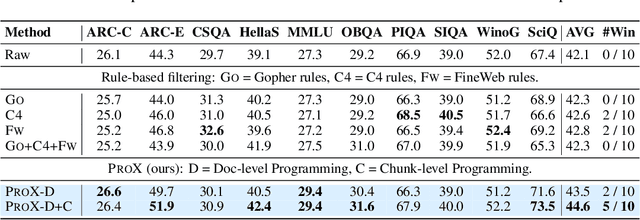
Large language model pre-training has traditionally relied on human experts to craft heuristics for improving the corpora quality, resulting in numerous rules developed to date. However, these rules lack the flexibility to address the unique characteristics of individual example effectively. Meanwhile, applying tailored rules to every example is impractical for human experts. In this paper, we demonstrate that even small language models, with as few as 0.3B parameters, can exhibit substantial data refining capabilities comparable to those of human experts. We introduce Programming Every Example (ProX), a novel framework that treats data refinement as a programming task, enabling models to refine corpora by generating and executing fine-grained operations, such as string normalization, for each individual example at scale. Experimental results show that models pre-trained on ProX-curated data outperform either original data or data filtered by other selection methods by more than 2% across various downstream benchmarks. Its effectiveness spans various model sizes and pre-training corpora, including C4, RedPajama-V2, and FineWeb. Furthermore, ProX exhibits significant potential in domain-specific continual pre-training: without domain specific design, models trained on OpenWebMath refined by ProX outperform human-crafted rule-based methods, improving average accuracy by 7.6% over Mistral-7B, with 14.6% for Llama-2-7B and 20.3% for CodeLlama-7B, all within 10B tokens to be comparable to models like Llemma-7B trained on 200B tokens. Further analysis highlights that ProX significantly saves training FLOPs, offering a promising path for efficient LLM pre-training.We are open-sourcing ProX with >100B corpus, models, and sharing all training and implementation details for reproducible research and future innovation. Code: https://github.com/GAIR-NLP/ProX
Reformatted Alignment
Feb 19, 2024The quality of finetuning data is crucial for aligning large language models (LLMs) with human values. Current methods to improve data quality are either labor-intensive or prone to factual errors caused by LLM hallucinations. This paper explores elevating the quality of existing instruction data to better align with human values, introducing a simple and effective approach named ReAlign, which reformats the responses of instruction data into a format that better aligns with pre-established criteria and the collated evidence. This approach minimizes human annotation, hallucination, and the difficulty in scaling, remaining orthogonal to existing alignment techniques. Experimentally, ReAlign significantly boosts the general alignment ability, math reasoning, factuality, and readability of the LLMs. Encouragingly, without introducing any additional data or advanced training techniques, and merely by reformatting the response, LLaMA-2-13B's mathematical reasoning ability on GSM8K can be improved from 46.77% to 56.63% in accuracy. Additionally, a mere 5% of ReAlign data yields a 67% boost in general alignment ability measured by the Alpaca dataset. This work highlights the need for further research into the science and mechanistic interpretability of LLMs. We have made the associated code and data publicly accessible to support future studies at https://github.com/GAIR-NLP/ReAlign.
Dissecting Human and LLM Preferences
Feb 17, 2024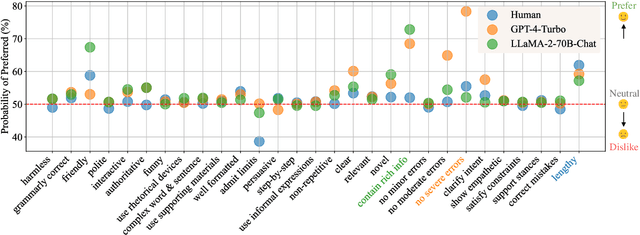

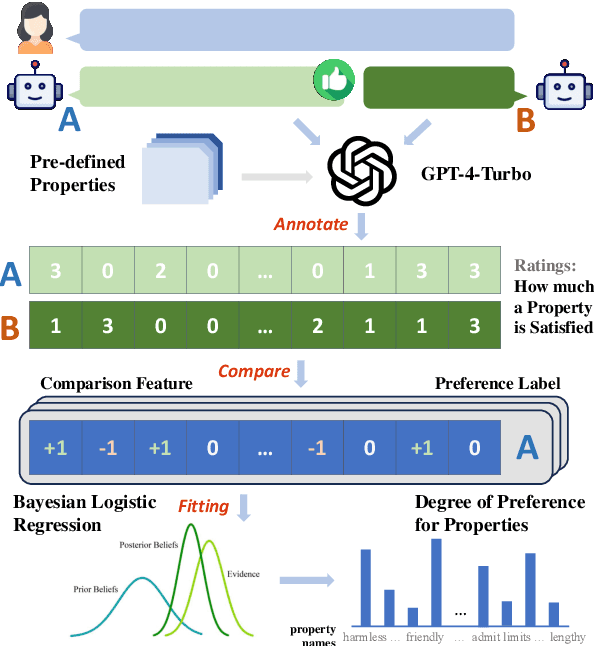
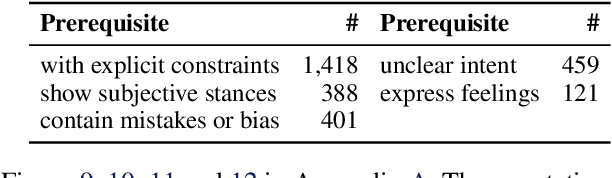
As a relative quality comparison of model responses, human and Large Language Model (LLM) preferences serve as common alignment goals in model fine-tuning and criteria in evaluation. Yet, these preferences merely reflect broad tendencies, resulting in less explainable and controllable models with potential safety risks. In this work, we dissect the preferences of human and 32 different LLMs to understand their quantitative composition, using annotations from real-world user-model conversations for a fine-grained, scenario-wise analysis. We find that humans are less sensitive to errors, favor responses that support their stances, and show clear dislike when models admit their limits. On the contrary, advanced LLMs like GPT-4-Turbo emphasize correctness, clarity, and harmlessness more. Additionally, LLMs of similar sizes tend to exhibit similar preferences, regardless of their training methods, and fine-tuning for alignment does not significantly alter the preferences of pretrained-only LLMs. Finally, we show that preference-based evaluation can be intentionally manipulated. In both training-free and training-based settings, aligning a model with the preferences of judges boosts scores, while injecting the least preferred properties lowers them. This results in notable score shifts: up to 0.59 on MT-Bench (1-10 scale) and 31.94 on AlpacaEval 2.0 (0-100 scale), highlighting the significant impact of this strategic adaptation. Interactive Demo: https://huggingface.co/spaces/GAIR/Preference-Dissection-Visualization Dataset: https://huggingface.co/datasets/GAIR/preference-dissection Code: https://github.com/GAIR-NLP/Preference-Dissection
Extending LLMs' Context Window with 100 Samples
Jan 13, 2024Large Language Models (LLMs) are known to have limited extrapolation ability beyond their pre-trained context window, constraining their application in downstream tasks with lengthy inputs. Recent studies have sought to extend LLMs' context window by modifying rotary position embedding (RoPE), a popular position encoding method adopted by well-known LLMs such as LLaMA, PaLM, and GPT-NeoX. However, prior works like Position Interpolation (PI) and YaRN are resource-intensive and lack comparative experiments to assess their applicability. In this work, we identify the inherent need for LLMs' attention entropy (i.e. the information entropy of attention scores) to maintain stability and introduce a novel extension to RoPE which combines adjusting RoPE's base frequency and scaling the attention logits to help LLMs efficiently adapt to a larger context window. We validate the superiority of our method in both fine-tuning performance and robustness across different context window sizes on various context-demanding tasks. Notably, our method extends the context window of LLaMA-2-7B-Chat to 16,384 with only 100 samples and 6 training steps, showcasing extraordinary efficiency. Finally, we also explore how data compositions and training curricula affect context window extension for specific downstream tasks, suggesting fine-tuning LLMs with lengthy conversations as a good starting point. We release our code and SFT data at https://github.com/GAIR-NLP/Entropy-ABF.