 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying When Pruning Works via Representation Hierarchies
Mar 25, 2026Network pruning, which removes less important parameters or architectures, is often expected to improve efficiency while preserving performance. However, this expectation does not consistently hold across language tasks: pruned models can perform well on non-generative tasks but frequently fail in generative settings. To understand this discrepancy, we analyze network pruning from a representation-hierarchy perspective, decomposing the internal computation of language models into three sequential spaces: embedding (hidden representations), logit (pre-softmax outputs), and probability (post-softmax distributions). We find that representations in the embedding and logit spaces are largely robust to pruning-induced perturbations. However, the nonlinear transformation from logits to probabilities amplifies these deviations, which accumulate across time steps and lead to substantial degradation during generation. In contrast, the stability of the categorical-token probability subspace, together with the robustness of the embedding space, supports the effectiveness of pruning for non-generative tasks such as retrieval and multiple-choice selection. Our analysis disentangles the effects of pruning across tasks and provides practical guidance for its application. Code is available at https://github.com/CASE-Lab-UMD/Pruning-on-Representations
ThinkJEPA: Empowering Latent World Models with Large Vision-Language Reasoning Model
Mar 23, 2026Recent progress in latent world models (e.g., V-JEPA2) has shown promising capability in forecasting future world states from video observations. Nevertheless, dense prediction from a short observation window limits temporal context and can bias predictors toward local, low-level extrapolation, making it difficult to capture long-horizon semantics and reducing downstream utility. Vision--language models (VLMs), in contrast, provide strong semantic grounding and general knowledge by reasoning over uniformly sampled frames, but they are not ideal as standalone dense predictors due to compute-driven sparse sampling, a language-output bottleneck that compresses fine-grained interaction states into text-oriented representations, and a data-regime mismatch when adapting to small action-conditioned datasets. We propose a VLM-guided JEPA-style latent world modeling framework that combines dense-frame dynamics modeling with long-horizon semantic guidance via a dual-temporal pathway: a dense JEPA branch for fine-grained motion and interaction cues, and a uniformly sampled VLM \emph{thinker} branch with a larger temporal stride for knowledge-rich guidance. To transfer the VLM's progressive reasoning signals effectively, we introduce a hierarchical pyramid representation extraction module that aggregates multi-layer VLM representations into guidance features compatible with latent prediction. Experiments on hand-manipulation trajectory prediction show that our method outperforms both a strong VLM-only baseline and a JEPA-predictor baseline, and yields more robust long-horizon rollout behavior.
Making Large Language Models Efficient Dense Retrievers
Dec 23, 2025Recent work has shown that directly fine-tuning large language models (LLMs) for dense retrieval yields strong performance, but their substantial parameter counts make them computationally inefficient. While prior studies have revealed significant layer redundancy in LLMs for generative tasks, it remains unclear whether similar redundancy exists when these models are adapted for retrieval tasks, which require encoding entire sequences into fixed representations rather than generating tokens iteratively. To this end, we conduct a comprehensive analysis of layer redundancy in LLM-based dense retrievers. We find that, in contrast to generative settings, MLP layers are substantially more prunable, while attention layers remain critical for semantic aggregation. Building on this insight, we propose EffiR, a framework for developing efficient retrievers that performs large-scale MLP compression through a coarse-to-fine strategy (coarse-grained depth reduction followed by fine-grained width reduction), combined with retrieval-specific fine-tuning. Across diverse BEIR datasets and LLM backbones, EffiR achieves substantial reductions in model size and inference cost while preserving the performance of full-size models.
Dense Video Understanding with Gated Residual Tokenization
Sep 18, 2025High temporal resolution is essential for capturing fine-grained details in video understanding. However, current video large language models (VLLMs) and benchmarks mostly rely on low-frame-rate sampling, such as uniform sampling or keyframe selection, discarding dense temporal information. This compromise avoids the high cost of tokenizing every frame, which otherwise leads to redundant computation and linear token growth as video length increases. While this trade-off works for slowly changing content, it fails for tasks like lecture comprehension, where information appears in nearly every frame and requires precise temporal alignment. To address this gap, we introduce Dense Video Understanding (DVU), which enables high-FPS video comprehension by reducing both tokenization time and token overhead. Existing benchmarks are also limited, as their QA pairs focus on coarse content changes. We therefore propose DIVE (Dense Information Video Evaluation), the first benchmark designed for dense temporal reasoning. To make DVU practical, we present Gated Residual Tokenization (GRT), a two-stage framework: (1) Motion-Compensated Inter-Gated Tokenization uses pixel-level motion estimation to skip static regions during tokenization, achieving sub-linear growth in token count and compute. (2) Semantic-Scene Intra-Tokenization Merging fuses tokens across static regions within a scene, further reducing redundancy while preserving dynamic semantics. Experiments on DIVE show that GRT outperforms larger VLLM baselines and scales positively with FPS. These results highlight the importance of dense temporal information and demonstrate that GRT enables efficient, scalable high-FPS video understanding.
CoIn: Counting the Invisible Reasoning Tokens in Commercial Opaque LLM APIs
May 19, 2025As post-training techniques evolve, large language models (LLMs) are increasingly augmented with structured multi-step reasoning abilities, often optimized through reinforcement learning. These reasoning-enhanced models outperform standard LLMs on complex tasks and now underpin many commercial LLM APIs. However, to protect proprietary behavior and reduce verbosity, providers typically conceal the reasoning traces while returning only the final answer. This opacity introduces a critical transparency gap: users are billed for invisible reasoning tokens, which often account for the majority of the cost, yet have no means to verify their authenticity. This opens the door to token count inflation, where providers may overreport token usage or inject synthetic, low-effort tokens to inflate charges. To address this issue, we propose CoIn, a verification framework that audits both the quantity and semantic validity of hidden tokens. CoIn constructs a verifiable hash tree from token embedding fingerprints to check token counts, and uses embedding-based relevance matching to detect fabricated reasoning content. Experiments demonstrate that CoIn, when deployed as a trusted third-party auditor, can effectively detect token count inflation with a success rate reaching up to 94.7%, showing the strong ability to restore billing transparency in opaque LLM services. The dataset and code are available at https://github.com/CASE-Lab-UMD/LLM-Auditing-CoIn.
SymRTLO: Enhancing RTL Code Optimization with LLMs and Neuron-Inspired Symbolic Reasoning
Apr 14, 2025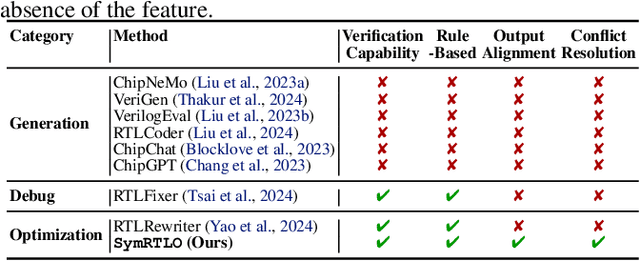
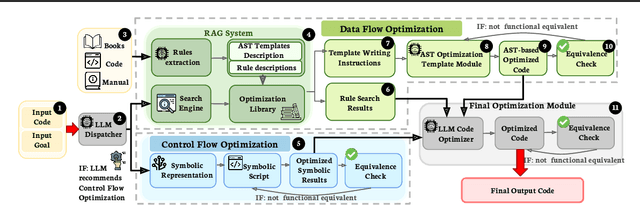

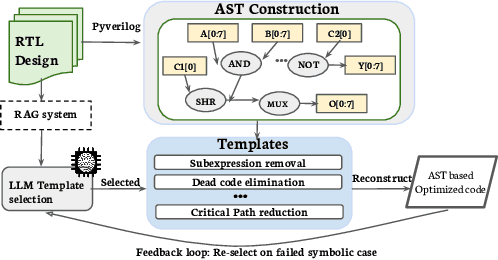
Optimizing Register Transfer Level (RTL) code is crucial for improving the power, performance, and area (PPA) of digital circuits in the early stages of synthesis. Manual rewriting, guided by synthesis feedback, can yield high-quality results but is time-consuming and error-prone. Most existing compiler-based approaches have difficulty handling complex design constraints. Large Language Model (LLM)-based methods have emerged as a promising alternative to address these challenges. However, LLM-based approaches often face difficulties in ensuring alignment between the generated code and the provided prompts. This paper presents SymRTLO, a novel neuron-symbolic RTL optimization framework that seamlessly integrates LLM-based code rewriting with symbolic reasoning techniques. Our method incorporates a retrieval-augmented generation (RAG) system of optimization rules and Abstract Syntax Tree (AST)-based templates, enabling LLM-based rewriting that maintains syntactic correctness while minimizing undesired circuit behaviors. A symbolic module is proposed for analyzing and optimizing finite state machine (FSM) logic, allowing fine-grained state merging and partial specification handling beyond the scope of pattern-based compilers. Furthermore, a fast verification pipeline, combining formal equivalence checks with test-driven validation, further reduces the complexity of verification. Experiments on the RTL-Rewriter benchmark with Synopsys Design Compiler and Yosys show that SymRTLO improves power, performance, and area (PPA) by up to 43.9%, 62.5%, and 51.1%, respectively, compared to the state-of-the-art methods.
Capacity-Aware Inference: Mitigating the Straggler Effect in Mixture of Experts
Mar 07, 2025The Mixture of Experts (MoE) is an effective architecture for scaling large language models by leveraging sparse expert activation, optimizing the trade-off between performance and efficiency. However, under expert parallelism, MoE suffers from inference inefficiencies due to imbalanced token-to-expert assignment, where some experts are overloaded while others remain underutilized. This imbalance leads to poor resource utilization and increased latency, as the most burdened expert dictates the overall delay, a phenomenon we define as the \textbf{\textit{Straggler Effect}}. To mitigate this, we propose Capacity-Aware Inference, including two key techniques: (1) \textbf{\textit{Capacity-Aware Token Drop}}, which discards overloaded tokens to regulate the maximum latency of MoE, and (2) \textbf{\textit{Capacity-Aware Token Reroute}}, which reallocates overflowed tokens to underutilized experts, balancing the token distribution. These techniques collectively optimize both high-load and low-load expert utilization, leading to a more efficient MoE inference pipeline. Extensive experiments demonstrate the effectiveness of our methods, showing significant improvements in inference efficiency, e.g., 0.2\% average performance increase and a 1.94$\times$ inference speedup on Mixtral-8$\times$7B-Instruct.
Fair Diagnosis: Leveraging Causal Modeling to Mitigate Medical Bias
Dec 06, 2024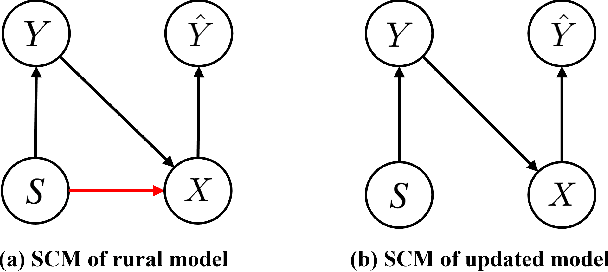
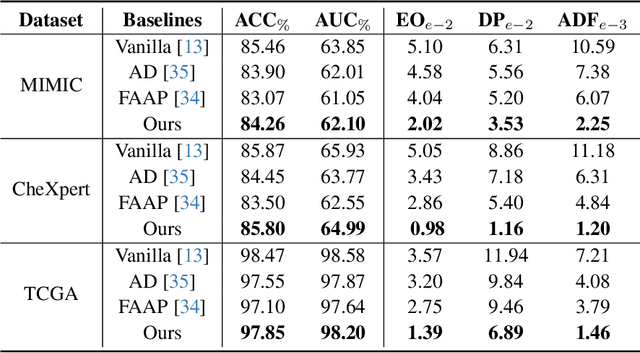
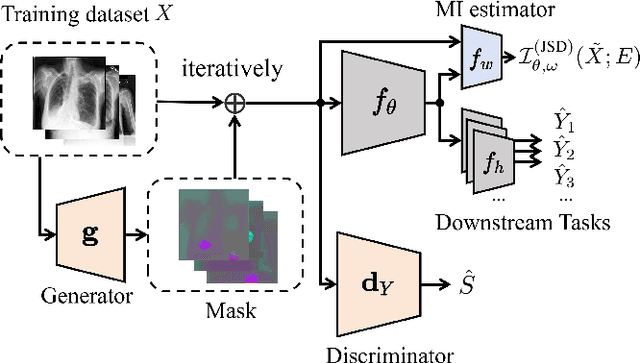
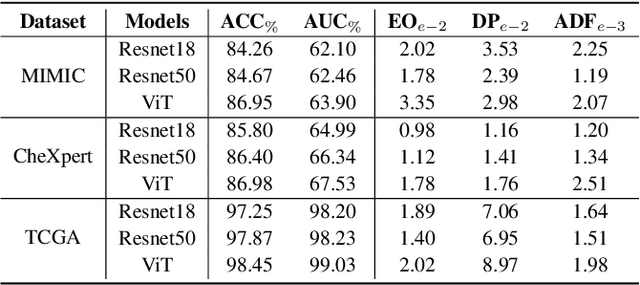
In medical image analysis, model predictions can be affected by sensitive attributes, such as race and gender, leading to fairness concerns and potential biases in diagnostic outcomes. To mitigate this, we present a causal modeling framework, which aims to reduce the impact of sensitive attributes on diagnostic predictions. Our approach introduces a novel fairness criterion, \textbf{Diagnosis Fairness}, and a unique fairness metric, leveraging path-specific fairness to control the influence of demographic attributes, ensuring that predictions are primarily informed by clinically relevant features rather than sensitive attributes. By incorporating adversarial perturbation masks, our framework directs the model to focus on critical image regions, suppressing bias-inducing information. Experimental results across multiple datasets demonstrate that our framework effectively reduces bias directly associated with sensitive attributes while preserving diagnostic accuracy. Our findings suggest that causal modeling can enhance both fairness and interpretability in AI-powered clinical decision support systems.
Towards counterfactual fairness thorough auxiliary variables
Dec 06, 2024The challenge of balancing fairness and predictive accuracy in machine learning models, especially when sensitive attributes such as race, gender, or age are considered, has motivated substantial research in recent years. Counterfactual fairness ensures that predictions remain consistent across counterfactual variations of sensitive attributes, which is a crucial concept in addressing societal biases. However, existing counterfactual fairness approaches usually overlook intrinsic information about sensitive features, limiting their ability to achieve fairness while simultaneously maintaining performance. To tackle this challenge, we introduce EXOgenous Causal reasoning (EXOC), a novel causal reasoning framework motivated by exogenous variables. It leverages auxiliary variables to uncover intrinsic properties that give rise to sensitive attributes. Our framework explicitly defines an auxiliary node and a control node that contribute to counterfactual fairness and control the information flow within the model. Our evaluation, conducted on synthetic and real-world datasets, validates EXOC's superiority, showing that it outperforms state-of-the-art approaches in achieving counterfactual fairness.
Router-Tuning: A Simple and Effective Approach for Enabling Dynamic-Depth in Transformers
Oct 17, 2024Traditional transformer models often allocate a fixed amount of computational resources to every input token, leading to inefficient and unnecessary computation. To address this, the Mixture of Depths (MoD) was introduced to dynamically adjust the computational depth by skipping less important layers. Despite its promise, current MoD approaches remain under-explored and face two main challenges: (1) \textit{high training costs due to the need to train the entire model along with the routers that determine which layers to skip}, and (2) \textit{the risk of performance degradation when important layers are bypassed}. In response to the first issue, we propose Router-Tuning, a method that fine-tunes only the router on a small dataset, drastically reducing the computational overhead associated with full model training. For the second challenge, we propose MindSkip, which deploys \textit{Attention with Dynamic Depths}. This method preserves the model's performance while significantly enhancing computational and memory efficiency. Extensive experiments demonstrate that our approach delivers competitive results while dramatically improving the computation efficiency, e.g., 21\% speedup and only a 0.2\% performance drop. The code is released at \url{https://github.com/CASE-Lab-UMD/Router-Tuning}.