 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication-free Sampling and 4D Hybrid Parallelism for Scalable Mini-batch GNN Training
Apr 03, 2026Graph neural networks (GNNs) are widely used for learning on graph datasets derived from various real-world scenarios. Learning from extremely large graphs requires distributed training, and mini-batching with sampling is a popular approach for parallelizing GNN training. Existing distributed mini-batch approaches have significant performance bottlenecks due to expensive sampling methods and limited scaling when using data parallelism. In this work, we present ScaleGNN, a 4D parallel framework for scalable mini-batch GNN training that combines communication-free distributed sampling, 3D parallel matrix multiplication (PMM), and data parallelism. ScaleGNN introduces a uniform vertex sampling algorithm, enabling each process (GPU device) to construct its local mini-batch, i.e., subgraph partitions without any inter-process communication. 3D PMM enables scaling mini-batch training to much larger GPU counts than vanilla data parallelism with significantly lower communication overheads. We also present additional optimizations to overlap sampling with training, reduce communication overhead by sending data in lower precision, kernel fusion, and communication-computation overlap. We evaluate ScaleGNN on five graph datasets and demonstrate strong scaling up to 2048 GPUs on Perlmutter, 2048 GCDs on Frontier, and 1024 GPUs on Tuolumne. On Perlmutter, ScaleGNN achieves 3.5x end-to-end training speedup over the SOTA baseline on ogbn-products.
Optimizing Agentic Language Model Inference via Speculative Tool Calls
Dec 17, 2025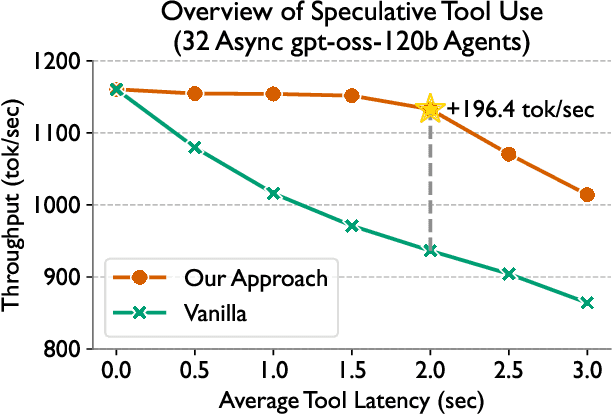
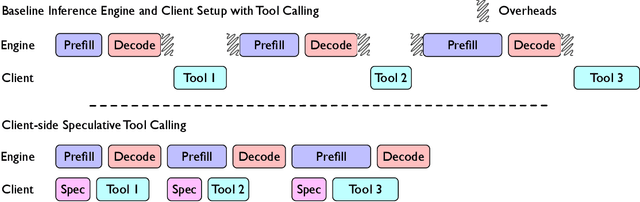
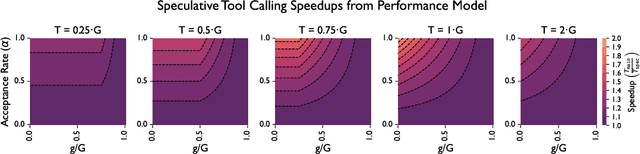
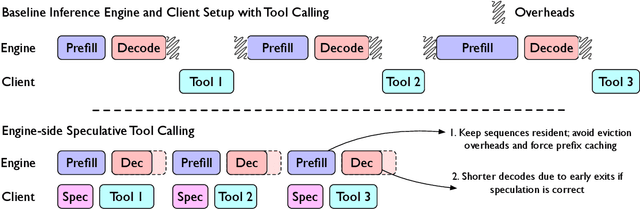
Language models (LMs) are becoming increasingly dependent on external tools. LM-based agentic frameworks frequently interact with their environment via such tools to search files, run code, call APIs, etc. Further, modern reasoning-based LMs use tools such as web search and Python code execution to enhance their reasoning capabilities. While tools greatly improve the capabilities of LMs, they also introduce performance bottlenecks during the inference process. In this paper, we introduce novel systems optimizations to address such performance bottlenecks by speculating tool calls and forcing sequences to remain resident in the inference engine to minimize overheads. Our optimizations lead to throughput improvements of several hundred tokens per second when hosting inference for LM agents. We provide a theoretical analysis of our algorithms to provide insights into speculation configurations that will yield the best performance. Further, we recommend a new "tool cache" API endpoint to enable LM providers to easily adopt these optimizations.
LLM Inference Beyond a Single Node: From Bottlenecks to Mitigations with Fast All-Reduce Communication
Nov 13, 2025
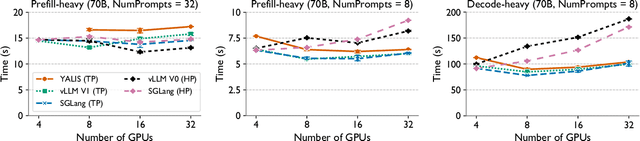

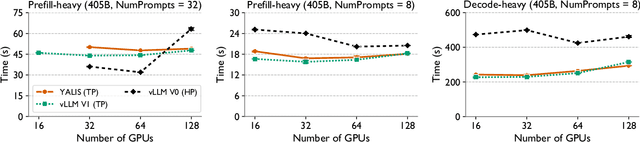
As large language models (LLMs) continue to grow in size, distributed inference has become increasingly important. Model-parallel strategies must now efficiently scale not only across multiple GPUs but also across multiple nodes. In this work, we present a detailed performance study of multi-node distributed inference using LLMs on GPU-based supercomputers. We conduct experiments with several state-of-the-art inference engines alongside YALIS, a research-oriented prototype engine designed for controlled experimentation. We analyze the strong-scaling behavior of different model-parallel schemes and identify key bottlenecks. Since all-reduce operations are a common performance bottleneck, we develop NVRAR, a hierarchical all-reduce algorithm based on recursive doubling with NVSHMEM. NVRAR achieves up to 1.9x-3.6x lower latency than NCCL for message sizes between 128 KB and 2 MB on HPE Slingshot and InfiniBand interconnects. Integrated into YALIS, NVRAR achieves up to a 1.72x reduction in end-to-end batch latency for the Llama 3.1 405B model in multi-node decode-heavy workloads using tensor parallelism.
Modeling Code: Is Text All You Need?
Jul 15, 2025Code LLMs have become extremely popular recently for modeling source code across a variety of tasks, such as generation, translation, and summarization. However, transformer-based models are limited in their capabilities to reason through structured, analytical properties of code, such as control and data flow. Previous work has explored the modeling of these properties with structured data and graph neural networks. However, these approaches lack the generative capabilities and scale of modern LLMs. In this work, we introduce a novel approach to combine the strengths of modeling both code as text and more structured forms.
Power Law Guided Dynamic Sifting for Efficient Attention
Jun 05, 2025Efficient inference on GPUs using large language models remains challenging due to memory bandwidth limitations, particularly during data transfers between High Bandwidth Memory (HBM) and SRAM in attention computations. Approximate attention methods address this issue by reducing computational and memory overhead but often rely on expensive top-$k$ operations, which perform poorly on GPUs. We propose SiftAttention, a novel approximate attention method that replaces the top-$k$ step with a computationally efficient element-wise filtering operation based on a threshold value. Our intuition for doing this is based on our empirical observation that the $\tau$-th quantile of attention scores follows a predictable power-law over sequential generation steps. Exploiting this insight, our approach dynamically estimates a threshold value per prompt at each generation step. Only attention scores above this threshold and their corresponding value vectors are loaded/used to compute the attention output, reducing data movement between HBM and SRAM. Our evaluation demonstrates that SiftAttention preserves model quality better than existing approximate attention methods while reducing memory bandwidth usage when loading value vectors.
Zero-Shot Vision Encoder Grafting via LLM Surrogates
May 28, 2025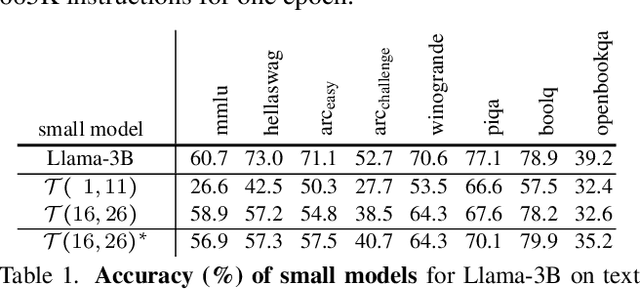
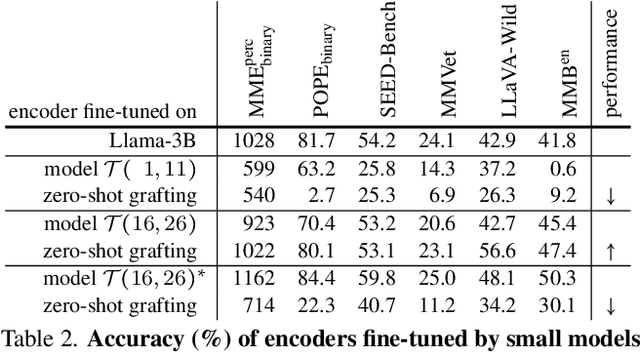
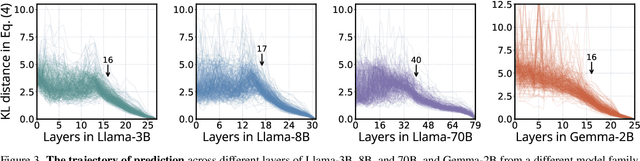

Vision language models (VLMs) typically pair a modestly sized vision encoder with a large language model (LLM), e.g., Llama-70B, making the decoder the primary computational burden during training. To reduce costs, a potential promising strategy is to first train the vision encoder using a small language model before transferring it to the large one. We construct small "surrogate models" that share the same embedding space and representation language as the large target LLM by directly inheriting its shallow layers. Vision encoders trained on the surrogate can then be directly transferred to the larger model, a process we call zero-shot grafting -- when plugged directly into the full-size target LLM, the grafted pair surpasses the encoder-surrogate pair and, on some benchmarks, even performs on par with full decoder training with the target LLM. Furthermore, our surrogate training approach reduces overall VLM training costs by ~45% when using Llama-70B as the decoder.
Plexus: Taming Billion-edge Graphs with 3D Parallel GNN Training
May 07, 2025Graph neural networks have emerged as a potent class of neural networks capable of leveraging the connectivity and structure of real-world graphs to learn intricate properties and relationships between nodes. Many real-world graphs exceed the memory capacity of a GPU due to their sheer size, and using GNNs on them requires techniques such as mini-batch sampling to scale. However, this can lead to reduced accuracy in some cases, and sampling and data transfer from the CPU to the GPU can also slow down training. On the other hand, distributed full-graph training suffers from high communication overhead and load imbalance due to the irregular structure of graphs. We propose Plexus, a three-dimensional (3D) parallel approach for full-graph training that tackles these issues and scales to billion-edge graphs. Additionally, we introduce optimizations such as a permutation scheme for load balancing, and a performance model to predict the optimal 3D configuration. We evaluate Plexus on several graph datasets and show scaling results for up to 2048 GPUs on Perlmutter, which is 33% of the machine, and 2048 GCDs on Frontier. Plexus achieves unprecedented speedups of 2.3x-12.5x over existing methods and a reduction in the time to solution by 5.2-8.7x on Perlmutter and 7-54.2x on Frontier.
The Big Send-off: High Performance Collectives on GPU-based Supercomputers
Apr 25, 2025We evaluate the current state of collective communication on GPU-based supercomputers for large language model (LLM) training at scale. Existing libraries such as RCCL and Cray-MPICH exhibit critical limitations on systems such as Frontier -- Cray-MPICH underutilizes network and compute resources, while RCCL suffers from severe scalability issues. To address these challenges, we introduce PCCL, a communication library with highly optimized implementations of all-gather and reduce-scatter operations tailored for distributed deep learning workloads. PCCL is designed to maximally utilize all available network and compute resources and to scale efficiently to thousands of GPUs. It achieves substantial performance improvements, delivering 6-33x speedups over RCCL and 28-70x over Cray-MPICH for all-gather on 2048 GCDs of Frontier. These gains translate directly to end-to-end performance: in large-scale GPT-3-style training, PCCL provides up to 60% and 40% speedups over RCCL for 7B and 13B parameter models, respectively.
Democratizing AI: Open-source Scalable LLM Training on GPU-based Supercomputers
Feb 12, 2025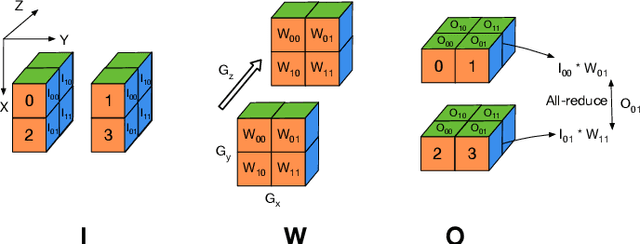
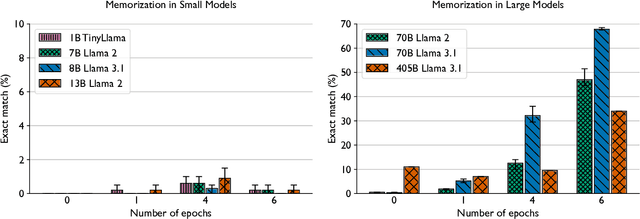
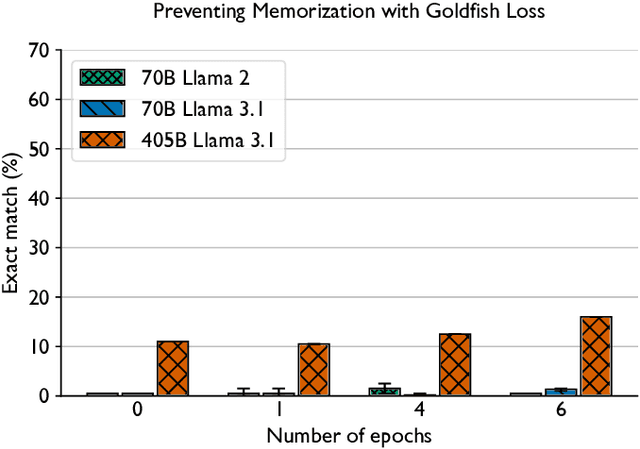
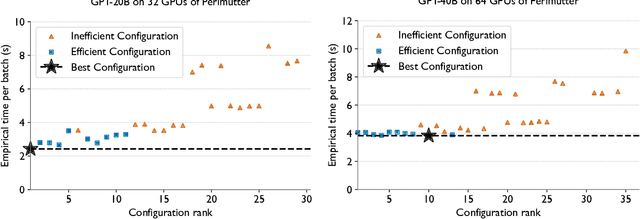
Training and fine-tuning large language models (LLMs) with hundreds of billions to trillions of parameters requires tens of thousands of GPUs, and a highly scalable software stack. In this work, we present a novel four-dimensional hybrid parallel algorithm implemented in a highly scalable, portable, open-source framework called AxoNN. We describe several performance optimizations in AxoNN to improve matrix multiply kernel performance, overlap non-blocking collectives with computation, and performance modeling to choose performance optimal configurations. These have resulted in unprecedented scaling and peak flop/s (bf16) for training of GPT-style transformer models on Perlmutter (620.1 Petaflop/s), Frontier (1.381 Exaflop/s) and Alps (1.423 Exaflop/s). While the abilities of LLMs improve with the number of trainable parameters, so do privacy and copyright risks caused by memorization of training data, which can cause disclosure of sensitive or private information at inference time. We highlight this side effect of scale through experiments that explore "catastrophic memorization", where models are sufficiently large to memorize training data in a single pass, and present an approach to prevent it. As part of this study, we demonstrate fine-tuning of a 405-billion parameter LLM using AxoNN on Frontier.
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
Feb 07, 2025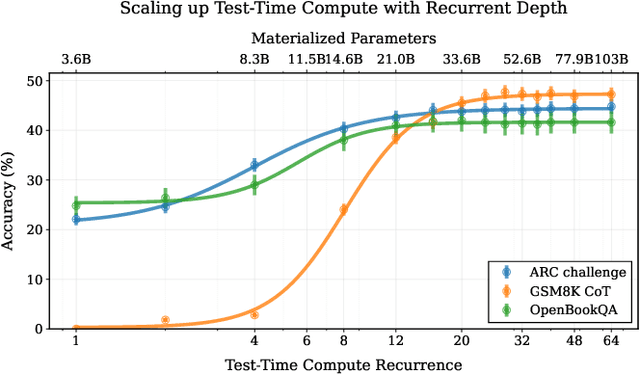
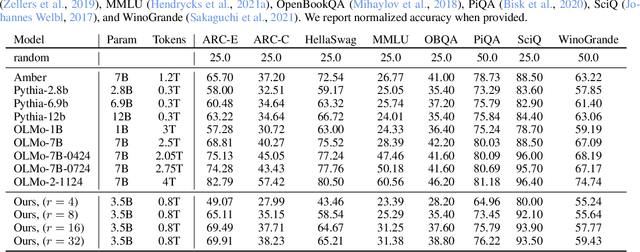
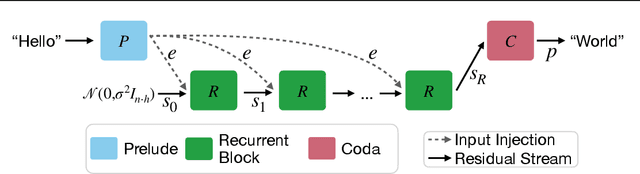
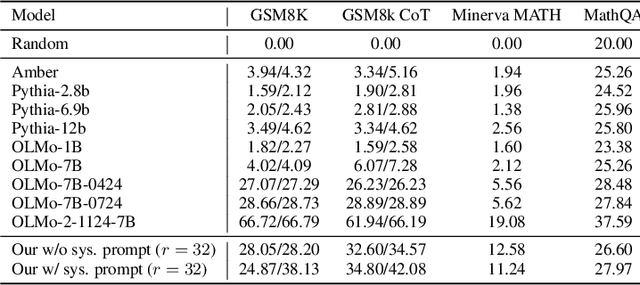
We study a novel language model architecture that is capable of scaling test-time computation by implicitly reasoning in latent space. Our model works by iterating a recurrent block, thereby unrolling to arbitrary depth at test-time. This stands in contrast to mainstream reasoning models that scale up compute by producing more tokens. Unlike approaches based on chain-of-thought, our approach does not require any specialized training data, can work with small context windows, and can capture types of reasoning that are not easily represented in words. We scale a proof-of-concept model to 3.5 billion parameters and 800 billion tokens. We show that the resulting model can improve its performance on reasoning benchmarks, sometimes dramatically, up to a computation load equivalent to 50 billion parameters.