 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemocratizing AI: Open-source Scalable LLM Training on GPU-based Supercomputers
Feb 12, 2025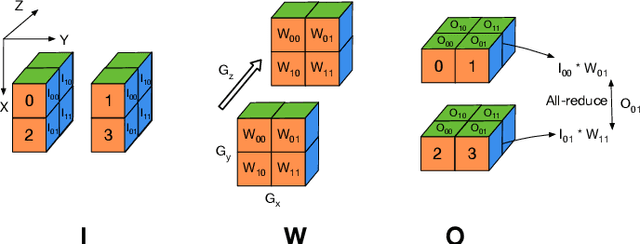
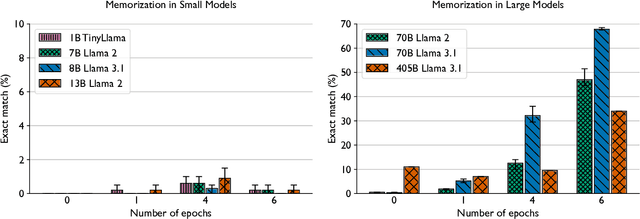
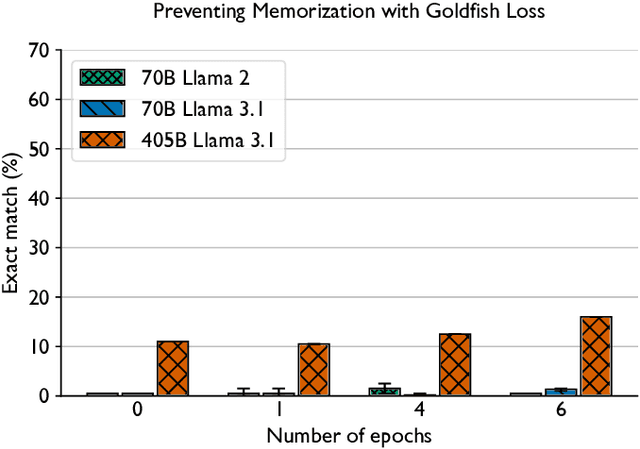
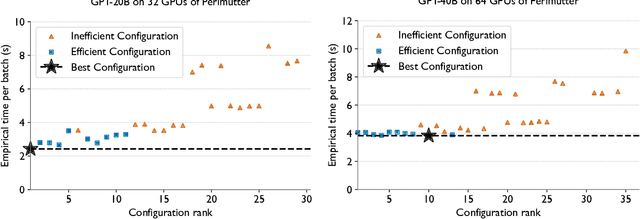
Training and fine-tuning large language models (LLMs) with hundreds of billions to trillions of parameters requires tens of thousands of GPUs, and a highly scalable software stack. In this work, we present a novel four-dimensional hybrid parallel algorithm implemented in a highly scalable, portable, open-source framework called AxoNN. We describe several performance optimizations in AxoNN to improve matrix multiply kernel performance, overlap non-blocking collectives with computation, and performance modeling to choose performance optimal configurations. These have resulted in unprecedented scaling and peak flop/s (bf16) for training of GPT-style transformer models on Perlmutter (620.1 Petaflop/s), Frontier (1.381 Exaflop/s) and Alps (1.423 Exaflop/s). While the abilities of LLMs improve with the number of trainable parameters, so do privacy and copyright risks caused by memorization of training data, which can cause disclosure of sensitive or private information at inference time. We highlight this side effect of scale through experiments that explore "catastrophic memorization", where models are sufficiently large to memorize training data in a single pass, and present an approach to prevent it. As part of this study, we demonstrate fine-tuning of a 405-billion parameter LLM using AxoNN on Frontier.
Exploiting Sparsity for Long Context Inference: Million Token Contexts on Commodity GPUs
Feb 10, 2025



There is growing demand for performing inference with hundreds of thousands of input tokens on trained transformer models. Inference at this extreme scale demands significant computational resources, hindering the application of transformers at long contexts on commodity (i.e not data center scale) hardware. To address the inference time costs associated with running self-attention based transformer language models on long contexts and enable their adoption on widely available hardware, we propose a tunable mechanism that reduces the cost of the forward pass by attending to only the most relevant tokens at every generation step using a top-k selection mechanism. We showcase the efficiency gains afforded by our method by performing inference on context windows up to 1M tokens using approximately 16GB of GPU RAM. Our experiments reveal that models are capable of handling the sparsity induced by the reduced number of keys and values. By attending to less than 2% of input tokens, we achieve over 95% of model performance on common long context benchmarks (LM-Eval, AlpacaEval, and RULER).
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
Feb 07, 2025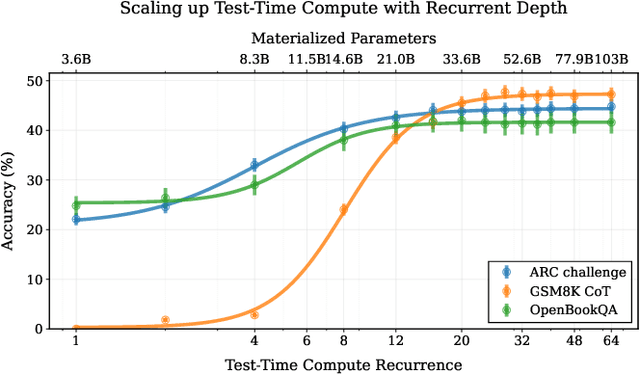
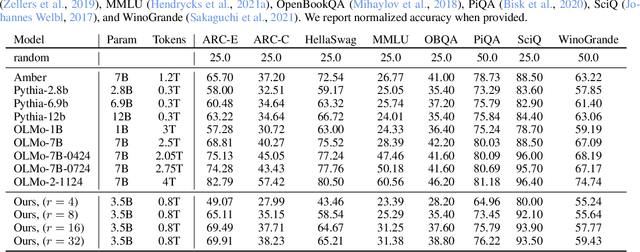
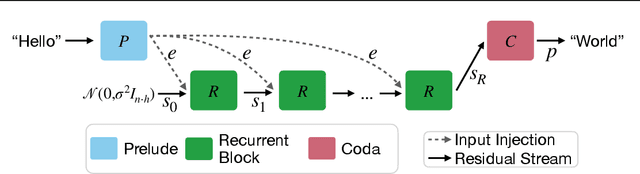
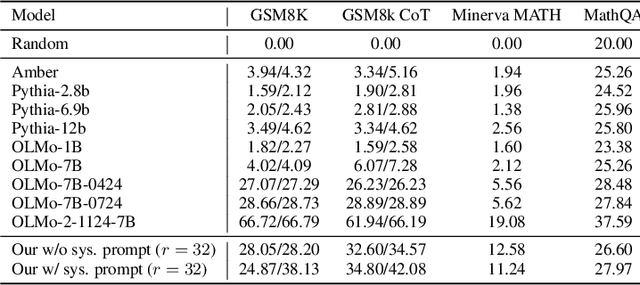
We study a novel language model architecture that is capable of scaling test-time computation by implicitly reasoning in latent space. Our model works by iterating a recurrent block, thereby unrolling to arbitrary depth at test-time. This stands in contrast to mainstream reasoning models that scale up compute by producing more tokens. Unlike approaches based on chain-of-thought, our approach does not require any specialized training data, can work with small context windows, and can capture types of reasoning that are not easily represented in words. We scale a proof-of-concept model to 3.5 billion parameters and 800 billion tokens. We show that the resulting model can improve its performance on reasoning benchmarks, sometimes dramatically, up to a computation load equivalent to 50 billion parameters.
Refusal Tokens: A Simple Way to Calibrate Refusals in Large Language Models
Dec 09, 2024



A key component of building safe and reliable language models is enabling the models to appropriately refuse to follow certain instructions or answer certain questions. We may want models to output refusal messages for various categories of user queries, for example, ill-posed questions, instructions for committing illegal acts, or queries which require information past the model's knowledge horizon. Engineering models that refuse to answer such questions is complicated by the fact that an individual may want their model to exhibit varying levels of sensitivity for refusing queries of various categories, and different users may want different refusal rates. The current default approach involves training multiple models with varying proportions of refusal messages from each category to achieve the desired refusal rates, which is computationally expensive and may require training a new model to accommodate each user's desired preference over refusal rates. To address these challenges, we propose refusal tokens, one such token for each refusal category or a single refusal token, which are prepended to the model's responses during training. We then show how to increase or decrease the probability of generating the refusal token for each category during inference to steer the model's refusal behavior. Refusal tokens enable controlling a single model's refusal rates without the need of any further fine-tuning, but only by selectively intervening during generation.
LiveBench: A Challenging, Contamination-Free LLM Benchmark
Jun 27, 2024



Test set contamination, wherein test data from a benchmark ends up in a newer model's training set, is a well-documented obstacle for fair LLM evaluation and can quickly render benchmarks obsolete. To mitigate this, many recent benchmarks crowdsource new prompts and evaluations from human or LLM judges; however, these can introduce significant biases, and break down when scoring hard questions. In this work, we introduce a new benchmark for LLMs designed to be immune to both test set contamination and the pitfalls of LLM judging and human crowdsourcing. We release LiveBench, the first benchmark that (1) contains frequently-updated questions from recent information sources, (2) scores answers automatically according to objective ground-truth values, and (3) contains a wide variety of challenging tasks, spanning math, coding, reasoning, language, instruction following, and data analysis. To achieve this, LiveBench contains questions that are based on recently-released math competitions, arXiv papers, news articles, and datasets, and it contains harder, contamination-free versions of tasks from previous benchmarks such as Big-Bench Hard, AMPS, and IFEval. We evaluate many prominent closed-source models, as well as dozens of open-source models ranging from 0.5B to 110B in size. LiveBench is difficult, with top models achieving below 65% accuracy. We release all questions, code, and model answers. Questions will be added and updated on a monthly basis, and we will release new tasks and harder versions of tasks over time so that LiveBench can distinguish between the capabilities of LLMs as they improve in the future. We welcome community engagement and collaboration for expanding the benchmark tasks and models.
GenQA: Generating Millions of Instructions from a Handful of Prompts
Jun 14, 2024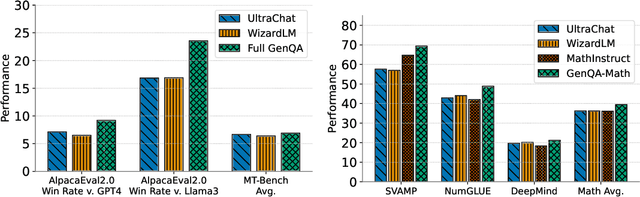
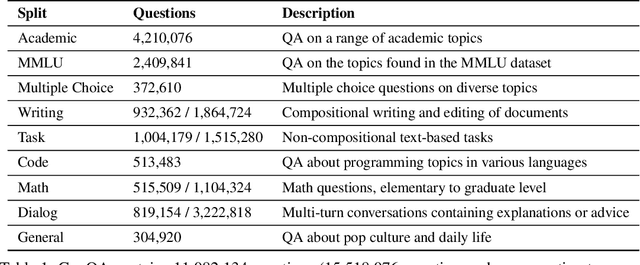
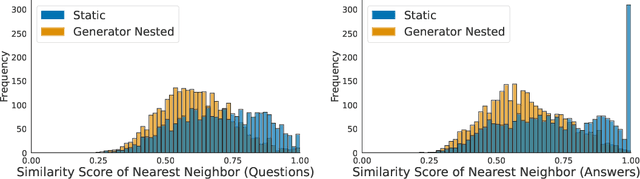
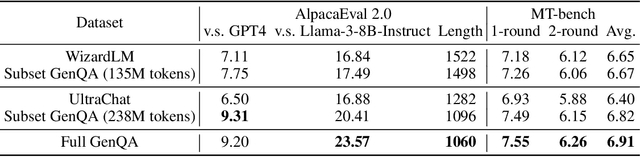
Most public instruction finetuning datasets are relatively small compared to the closed source datasets used to train industry models. To study questions about finetuning at scale, such as curricula and learning rate cooldown schedules, there is a need for industrial-scale datasets. However, this scale necessitates a data generation process that is almost entirely automated. In this work, we study methods for generating large instruction datasets from a single prompt. With little human oversight, we get LLMs to write diverse sets of instruction examples ranging from simple completion tasks to complex multi-turn dialogs across a variety of subject areas. When finetuning a Llama-3 8B base model, our dataset meets or exceeds both WizardLM and Ultrachat on both knowledge-intensive leaderboard tasks as well as conversational evaluations. We release our dataset, the "generator" prompts that created it, and our finetuned model checkpoints.
Be like a Goldfish, Don't Memorize! Mitigating Memorization in Generative LLMs
Jun 14, 2024



Large language models can memorize and repeat their training data, causing privacy and copyright risks. To mitigate memorization, we introduce a subtle modification to the next-token training objective that we call the goldfish loss. During training, a randomly sampled subset of tokens are excluded from the loss computation. These dropped tokens are not memorized by the model, which prevents verbatim reproduction of a complete chain of tokens from the training set. We run extensive experiments training billion-scale Llama-2 models, both pre-trained and trained from scratch, and demonstrate significant reductions in extractable memorization with little to no impact on downstream benchmarks.
Transformers Can Do Arithmetic with the Right Embeddings
May 27, 2024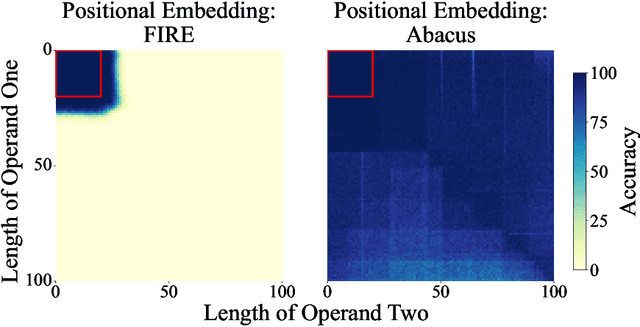
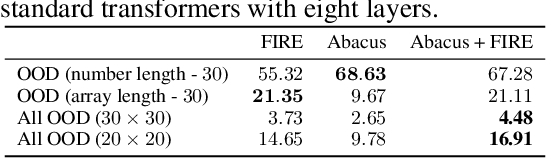

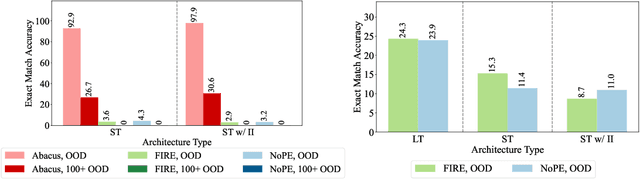
The poor performance of transformers on arithmetic tasks seems to stem in large part from their inability to keep track of the exact position of each digit inside of a large span of digits. We mend this problem by adding an embedding to each digit that encodes its position relative to the start of the number. In addition to the boost these embeddings provide on their own, we show that this fix enables architectural modifications such as input injection and recurrent layers to improve performance even further. With positions resolved, we can study the logical extrapolation ability of transformers. Can they solve arithmetic problems that are larger and more complex than those in their training data? We find that training on only 20 digit numbers with a single GPU for one day, we can reach state-of-the-art performance, achieving up to 99% accuracy on 100 digit addition problems. Finally, we show that these gains in numeracy also unlock improvements on other multi-step reasoning tasks including sorting and multiplication.
NEFTune: Noisy Embeddings Improve Instruction Finetuning
Oct 10, 2023



We show that language model finetuning can be improved, sometimes dramatically, with a simple augmentation. NEFTune adds noise to the embedding vectors during training. Standard finetuning of LLaMA-2-7B using Alpaca achieves 29.79% on AlpacaEval, which rises to 64.69% using noisy embeddings. NEFTune also improves over strong baselines on modern instruction datasets. Models trained with Evol-Instruct see a 10% improvement, with ShareGPT an 8% improvement, and with OpenPlatypus an 8% improvement. Even powerful models further refined with RLHF such as LLaMA-2-Chat benefit from additional training with NEFTune.
Baseline Defenses for Adversarial Attacks Against Aligned Language Models
Sep 04, 2023



As Large Language Models quickly become ubiquitous, it becomes critical to understand their security vulnerabilities. Recent work shows that text optimizers can produce jailbreaking prompts that bypass moderation and alignment. Drawing from the rich body of work on adversarial machine learning, we approach these attacks with three questions: What threat models are practically useful in this domain? How do baseline defense techniques perform in this new domain? How does LLM security differ from computer vision? We evaluate several baseline defense strategies against leading adversarial attacks on LLMs, discussing the various settings in which each is feasible and effective. Particularly, we look at three types of defenses: detection (perplexity based), input preprocessing (paraphrase and retokenization), and adversarial training. We discuss white-box and gray-box settings and discuss the robustness-performance trade-off for each of the defenses considered. We find that the weakness of existing discrete optimizers for text, combined with the relatively high costs of optimization, makes standard adaptive attacks more challenging for LLMs. Future research will be needed to uncover whether more powerful optimizers can be developed, or whether the strength of filtering and preprocessing defenses is greater in the LLMs domain than it has been in computer vision.