 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiveBench: A Challenging, Contamination-Free LLM Benchmark
Jun 27, 2024



Test set contamination, wherein test data from a benchmark ends up in a newer model's training set, is a well-documented obstacle for fair LLM evaluation and can quickly render benchmarks obsolete. To mitigate this, many recent benchmarks crowdsource new prompts and evaluations from human or LLM judges; however, these can introduce significant biases, and break down when scoring hard questions. In this work, we introduce a new benchmark for LLMs designed to be immune to both test set contamination and the pitfalls of LLM judging and human crowdsourcing. We release LiveBench, the first benchmark that (1) contains frequently-updated questions from recent information sources, (2) scores answers automatically according to objective ground-truth values, and (3) contains a wide variety of challenging tasks, spanning math, coding, reasoning, language, instruction following, and data analysis. To achieve this, LiveBench contains questions that are based on recently-released math competitions, arXiv papers, news articles, and datasets, and it contains harder, contamination-free versions of tasks from previous benchmarks such as Big-Bench Hard, AMPS, and IFEval. We evaluate many prominent closed-source models, as well as dozens of open-source models ranging from 0.5B to 110B in size. LiveBench is difficult, with top models achieving below 65% accuracy. We release all questions, code, and model answers. Questions will be added and updated on a monthly basis, and we will release new tasks and harder versions of tasks over time so that LiveBench can distinguish between the capabilities of LLMs as they improve in the future. We welcome community engagement and collaboration for expanding the benchmark tasks and models.
Large Language Models Must Be Taught to Know What They Don't Know
Jun 12, 2024



When using large language models (LLMs) in high-stakes applications, we need to know when we can trust their predictions. Some works argue that prompting high-performance LLMs is sufficient to produce calibrated uncertainties, while others introduce sampling methods that can be prohibitively expensive. In this work, we first argue that prompting on its own is insufficient to achieve good calibration and then show that fine-tuning on a small dataset of correct and incorrect answers can create an uncertainty estimate with good generalization and small computational overhead. We show that a thousand graded examples are sufficient to outperform baseline methods and that training through the features of a model is necessary for good performance and tractable for large open-source models when using LoRA. We also investigate the mechanisms that enable reliable LLM uncertainty estimation, finding that many models can be used as general-purpose uncertainty estimators, applicable not just to their own uncertainties but also the uncertainty of other models. Lastly, we show that uncertainty estimates inform human use of LLMs in human-AI collaborative settings through a user study.
Smaug: Fixing Failure Modes of Preference Optimisation with DPO-Positive
Feb 20, 2024



Direct Preference Optimisation (DPO) is effective at significantly improving the performance of large language models (LLMs) on downstream tasks such as reasoning, summarisation, and alignment. Using pairs of preferred and dispreferred data, DPO models the \textit{relative} probability of picking one response over another. In this work, first we show theoretically that the standard DPO loss can lead to a \textit{reduction} of the model's likelihood of the preferred examples, as long as the relative probability between the preferred and dispreferred classes increases. We then show empirically that this phenomenon occurs when fine-tuning LLMs on common datasets, especially datasets in which the edit distance between pairs of completions is low. Using these insights, we design DPO-Positive (DPOP), a new loss function and training procedure which avoids this failure mode. Surprisingly, we also find that DPOP significantly outperforms DPO across a wide variety of datasets and downstream tasks, including datasets with high edit distances between completions. By fine-tuning with DPOP, we create and release Smaug-34B and Smaug-72B, which achieve state-of-the-art open-source performance. Notably, Smaug-72B is nearly 2\% better than any other open-source model on the HuggingFace Open LLM Leaderboard and becomes the first open-source LLM to surpass an average accuracy of 80\%.
Data Contamination Through the Lens of Time
Oct 16, 2023Recent claims about the impressive abilities of large language models (LLMs) are often supported by evaluating publicly available benchmarks. Since LLMs train on wide swaths of the internet, this practice raises concerns of data contamination, i.e., evaluating on examples that are explicitly or implicitly included in the training data. Data contamination remains notoriously challenging to measure and mitigate, even with partial attempts like controlled experimentation of training data, canary strings, or embedding similarities. In this work, we conduct the first thorough longitudinal analysis of data contamination in LLMs by using the natural experiment of training cutoffs in GPT models to look at benchmarks released over time. Specifically, we consider two code/mathematical problem-solving datasets, Codeforces and Project Euler, and find statistically significant trends among LLM pass rate vs. GitHub popularity and release date that provide strong evidence of contamination. By open-sourcing our dataset, raw results, and evaluation framework, our work paves the way for rigorous analyses of data contamination in modern models. We conclude with a discussion of best practices and future steps for publicly releasing benchmarks in the age of LLMs that train on webscale data.
Giraffe: Adventures in Expanding Context Lengths in LLMs
Aug 21, 2023



Modern large language models (LLMs) that rely on attention mechanisms are typically trained with fixed context lengths which enforce upper limits on the length of input sequences that they can handle at evaluation time. To use these models on sequences longer than the train-time context length, one might employ techniques from the growing family of context length extrapolation methods -- most of which focus on modifying the system of positional encodings used in the attention mechanism to indicate where tokens or activations are located in the input sequence. We conduct a wide survey of existing methods of context length extrapolation on a base LLaMA or LLaMA 2 model, and introduce some of our own design as well -- in particular, a new truncation strategy for modifying the basis for the position encoding. We test these methods using three new evaluation tasks (FreeFormQA, AlteredNumericQA, and LongChat-Lines) as well as perplexity, which we find to be less fine-grained as a measure of long context performance of LLMs. We release the three tasks publicly as datasets on HuggingFace. We discover that linear scaling is the best method for extending context length, and show that further gains can be achieved by using longer scales at evaluation time. We also discover promising extrapolation capabilities in the truncated basis. To support further research in this area, we release three new 13B parameter long-context models which we call Giraffe: 4k and 16k context models trained from base LLaMA-13B, and a 32k context model trained from base LLaMA2-13B. We also release the code to replicate our results.
Unsupervised Learning under Latent Label Shift
Jul 26, 2022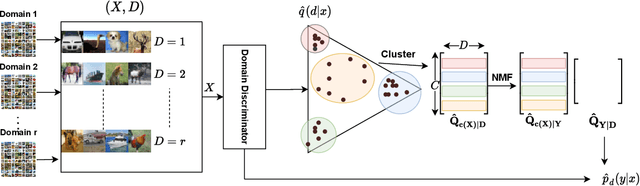
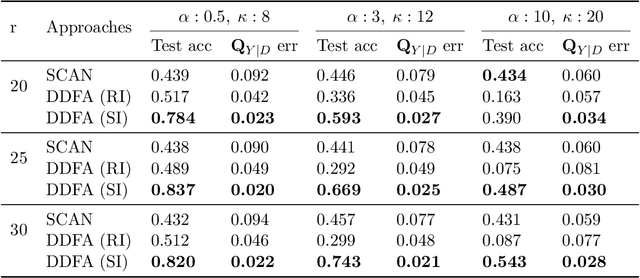
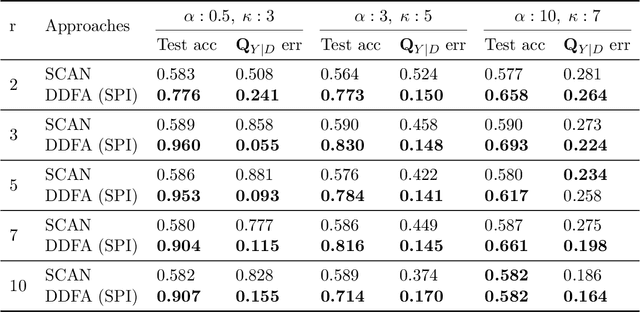
What sorts of structure might enable a learner to discover classes from unlabeled data? Traditional approaches rely on feature-space similarity and heroic assumptions on the data. In this paper, we introduce unsupervised learning under Latent Label Shift (LLS), where we have access to unlabeled data from multiple domains such that the label marginals $p_d(y)$ can shift across domains but the class conditionals $p(\mathbf{x}|y)$ do not. This work instantiates a new principle for identifying classes: elements that shift together group together. For finite input spaces, we establish an isomorphism between LLS and topic modeling: inputs correspond to words, domains to documents, and labels to topics. Addressing continuous data, we prove that when each label's support contains a separable region, analogous to an anchor word, oracle access to $p(d|\mathbf{x})$ suffices to identify $p_d(y)$ and $p_d(y|\mathbf{x})$ up to permutation. Thus motivated, we introduce a practical algorithm that leverages domain-discriminative models as follows: (i) push examples through domain discriminator $p(d|\mathbf{x})$; (ii) discretize the data by clustering examples in $p(d|\mathbf{x})$ space; (iii) perform non-negative matrix factorization on the discrete data; (iv) combine the recovered $p(y|d)$ with the discriminator outputs $p(d|\mathbf{x})$ to compute $p_d(y|x) \; \forall d$. With semi-synthetic experiments, we show that our algorithm can leverage domain information to improve state of the art unsupervised classification methods. We reveal a failure mode of standard unsupervised classification methods when feature-space similarity does not indicate true groupings, and show empirically that our method better handles this case. Our results establish a deep connection between distribution shift and topic modeling, opening promising lines for future work.