 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOET-X: Memory-efficient LLM Training by Scaling Orthogonal Transformation
Mar 05, 2026Efficient and stable training of large language models (LLMs) remains a core challenge in modern machine learning systems. To address this challenge, Reparameterized Orthogonal Equivalence Training (POET), a spectrum-preserving framework that optimizes each weight matrix through orthogonal equivalence transformation, has been proposed. Although POET provides strong training stability, its original implementation incurs high memory consumption and computational overhead due to intensive matrix multiplications. To overcome these limitations, we introduce POET-X, a scalable and memory-efficient variant that performs orthogonal equivalence transformations with significantly reduced computational cost. POET-X maintains the generalization and stability benefits of POET while achieving substantial improvements in throughput and memory efficiency. In our experiments, POET-X enables the pretraining of billion-parameter LLMs on a single Nvidia H100 GPU, and in contrast, standard optimizers such as AdamW run out of memory under the same settings.
Use What You Know: Causal Foundation Models with Partial Graphs
Feb 16, 2026Estimating causal quantities traditionally relies on bespoke estimators tailored to specific assumptions. Recently proposed Causal Foundation Models (CFMs) promise a more unified approach by amortising causal discovery and inference in a single step. However, in their current state, they do not allow for the incorporation of any domain knowledge, which can lead to suboptimal predictions. We bridge this gap by introducing methods to condition CFMs on causal information, such as the causal graph or more readily available ancestral information. When access to complete causal graph information is too strict a requirement, our approach also effectively leverages partial causal information. We systematically evaluate conditioning strategies and find that injecting learnable biases into the attention mechanism is the most effective method to utilise full and partial causal information. Our experiments show that this conditioning allows a general-purpose CFM to match the performance of specialised models trained on specific causal structures. Overall, our approach addresses a central hurdle on the path towards all-in-one causal foundation models: the capability to answer causal queries in a data-driven manner while effectively leveraging any amount of domain expertise.
Position: Capability Control Should be a Separate Goal From Alignment
Feb 05, 2026Foundation models are trained on broad data distributions, yielding generalist capabilities that enable many downstream applications but also expand the space of potential misuse and failures. This position paper argues that capability control -- imposing restrictions on permissible model behavior -- should be treated as a distinct goal from alignment. While alignment is often context and preference-driven, capability control aims to impose hard operational limits on permissible behaviors, including under adversarial elicitation. We organize capability control mechanisms across the model lifecycle into three layers: (i) data-based control of the training distribution, (ii) learning-based control via weight- or representation-level interventions, and (iii) system-based control via post-deployment guardrails over inputs, outputs, and actions. Because each layer has characteristic failure modes when used in isolation, we advocate for a defense-in-depth approach that composes complementary controls across the full stack. We further outline key open challenges in achieving such control, including the dual-use nature of knowledge and compositional generalization.
A Matter of Interest: Understanding Interestingness of Math Problems in Humans and Language Models
Nov 11, 2025The evolution of mathematics has been guided in part by interestingness. From researchers choosing which problems to tackle next, to students deciding which ones to engage with, people's choices are often guided by judgments about how interesting or challenging problems are likely to be. As AI systems, such as LLMs, increasingly participate in mathematics with people -- whether for advanced research or education -- it becomes important to understand how well their judgments align with human ones. Our work examines this alignment through two empirical studies of human and LLM assessment of mathematical interestingness and difficulty, spanning a range of mathematical experience. We study two groups: participants from a crowdsourcing platform and International Math Olympiad competitors. We show that while many LLMs appear to broadly agree with human notions of interestingness, they mostly do not capture the distribution observed in human judgments. Moreover, most LLMs only somewhat align with why humans find certain math problems interesting, showing weak correlation with human-selected interestingness rationales. Together, our findings highlight both the promises and limitations of current LLMs in capturing human interestingness judgments for mathematical AI thought partnerships.
Wavelet-Induced Rotary Encodings: RoPE Meets Graphs
Sep 26, 2025We introduce WIRE: Wavelet-Induced Rotary Encodings. WIRE extends Rotary Position Encodings (RoPE), a popular algorithm in LLMs and ViTs, to graph-structured data. We demonstrate that WIRE is more general than RoPE, recovering the latter in the special case of grid graphs. WIRE also enjoys a host of desirable theoretical properties, including equivariance under node ordering permutation, compatibility with linear attention, and (under select assumptions) asymptotic dependence on graph resistive distance. We test WIRE on a range of synthetic and real-world tasks, including identifying monochromatic subgraphs, semantic segmentation of point clouds, and more standard graph benchmarks. We find it to be effective in settings where the underlying graph structure is important.
Graph Random Features for Scalable Gaussian Processes
Sep 03, 2025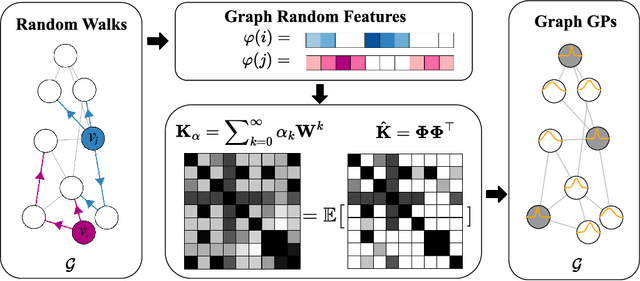

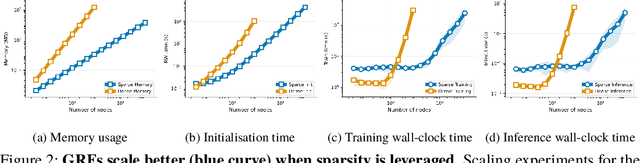

We study the application of graph random features (GRFs) - a recently introduced stochastic estimator of graph node kernels - to scalable Gaussian processes on discrete input spaces. We prove that (under mild assumptions) Bayesian inference with GRFs enjoys $O(N^{3/2})$ time complexity with respect to the number of nodes $N$, compared to $O(N^3)$ for exact kernels. Substantial wall-clock speedups and memory savings unlock Bayesian optimisation on graphs with over $10^6$ nodes on a single computer chip, whilst preserving competitive performance.
Unequal Uncertainty: Rethinking Algorithmic Interventions for Mitigating Discrimination from AI
Aug 11, 2025Uncertainty in artificial intelligence (AI) predictions poses urgent legal and ethical challenges for AI-assisted decision-making. We examine two algorithmic interventions that act as guardrails for human-AI collaboration: selective abstention, which withholds high-uncertainty predictions from human decision-makers, and selective friction, which delivers those predictions together with salient warnings or disclosures that slow the decision process. Research has shown that selective abstention based on uncertainty can inadvertently exacerbate disparities and disadvantage under-represented groups that disproportionately receive uncertain predictions. In this paper, we provide the first integrated socio-technical and legal analysis of uncertainty-based algorithmic interventions. Through two case studies, AI-assisted consumer credit decisions and AI-assisted content moderation, we demonstrate how the seemingly neutral use of uncertainty thresholds can trigger discriminatory impacts. We argue that, although both interventions pose risks of unlawful discrimination under UK law, selective frictions offer a promising pathway toward fairer and more accountable AI-assisted decision-making by preserving transparency and encouraging more cautious human judgment.
Orthogonal Finetuning Made Scalable
Jun 24, 2025Orthogonal finetuning (OFT) offers highly parameter-efficient adaptation while preventing catastrophic forgetting, but its high runtime and memory demands limit practical deployment. We identify the core computational bottleneck in OFT as its weight-centric implementation, which relies on costly matrix-matrix multiplications with cubic complexity. To overcome this, we propose OFTv2, an input-centric reformulation that instead uses matrix-vector multiplications (i.e., matrix-free computation), reducing the computational cost to quadratic. We further introduce the Cayley-Neumann parameterization, an efficient orthogonal parameterization that approximates the matrix inversion in Cayley transform via a truncated Neumann series. These modifications allow OFTv2 to achieve up to 10x faster training and 3x lower GPU memory usage without compromising performance. In addition, we extend OFTv2 to support finetuning quantized foundation models and show that it outperforms the popular QLoRA in training stability, efficiency, and memory usage.
Confidential Guardian: Cryptographically Prohibiting the Abuse of Model Abstention
May 29, 2025



Cautious predictions -- where a machine learning model abstains when uncertain -- are crucial for limiting harmful errors in safety-critical applications. In this work, we identify a novel threat: a dishonest institution can exploit these mechanisms to discriminate or unjustly deny services under the guise of uncertainty. We demonstrate the practicality of this threat by introducing an uncertainty-inducing attack called Mirage, which deliberately reduces confidence in targeted input regions, thereby covertly disadvantaging specific individuals. At the same time, Mirage maintains high predictive performance across all data points. To counter this threat, we propose Confidential Guardian, a framework that analyzes calibration metrics on a reference dataset to detect artificially suppressed confidence. Additionally, it employs zero-knowledge proofs of verified inference to ensure that reported confidence scores genuinely originate from the deployed model. This prevents the provider from fabricating arbitrary model confidence values while protecting the model's proprietary details. Our results confirm that Confidential Guardian effectively prevents the misuse of cautious predictions, providing verifiable assurances that abstention reflects genuine model uncertainty rather than malicious intent.
From Dormant to Deleted: Tamper-Resistant Unlearning Through Weight-Space Regularization
May 28, 2025Recent unlearning methods for LLMs are vulnerable to relearning attacks: knowledge believed-to-be-unlearned re-emerges by fine-tuning on a small set of (even seemingly-unrelated) examples. We study this phenomenon in a controlled setting for example-level unlearning in vision classifiers. We make the surprising discovery that forget-set accuracy can recover from around 50% post-unlearning to nearly 100% with fine-tuning on just the retain set -- i.e., zero examples of the forget set. We observe this effect across a wide variety of unlearning methods, whereas for a model retrained from scratch excluding the forget set (gold standard), the accuracy remains at 50%. We observe that resistance to relearning attacks can be predicted by weight-space properties, specifically, $L_2$-distance and linear mode connectivity between the original and the unlearned model. Leveraging this insight, we propose a new class of methods that achieve state-of-the-art resistance to relearning attacks.