 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Patients Really Ask: Exploring the Effect of False Assumptions in Patient Information Seeking
Jan 22, 2026Patients are increasingly using large language models (LLMs) to seek answers to their healthcare-related questions. However, benchmarking efforts in LLMs for question answering often focus on medical exam questions, which differ significantly in style and content from the questions patients actually raise in real life. To bridge this gap, we sourced data from Google's People Also Ask feature by querying the top 200 prescribed medications in the United States, curating a dataset of medical questions people commonly ask. A considerable portion of the collected questions contains incorrect assumptions and dangerous intentions. We demonstrate that the emergence of these corrupted questions is not uniformly random and depends heavily on the degree of incorrectness in the history of questions that led to their appearance. Current LLMs that perform strongly on other benchmarks struggle to identify incorrect assumptions in everyday questions.
MedRedFlag: Investigating how LLMs Redirect Misconceptions in Real-World Health Communication
Jan 14, 2026Real-world health questions from patients often unintentionally embed false assumptions or premises. In such cases, safe medical communication typically involves redirection: addressing the implicit misconception and then responding to the underlying patient context, rather than the original question. While large language models (LLMs) are increasingly being used by lay users for medical advice, they have not yet been tested for this crucial competency. Therefore, in this work, we investigate how LLMs react to false premises embedded within real-world health questions. We develop a semi-automated pipeline to curate MedRedFlag, a dataset of 1100+ questions sourced from Reddit that require redirection. We then systematically compare responses from state-of-the-art LLMs to those from clinicians. Our analysis reveals that LLMs often fail to redirect problematic questions, even when the problematic premise is detected, and provide answers that could lead to suboptimal medical decision making. Our benchmark and results reveal a novel and substantial gap in how LLMs perform under the conditions of real-world health communication, highlighting critical safety concerns for patient-facing medical AI systems. Code and dataset are available at https://github.com/srsambara-1/MedRedFlag.
On Benchmarking Human-Like Intelligence in Machines
Feb 27, 2025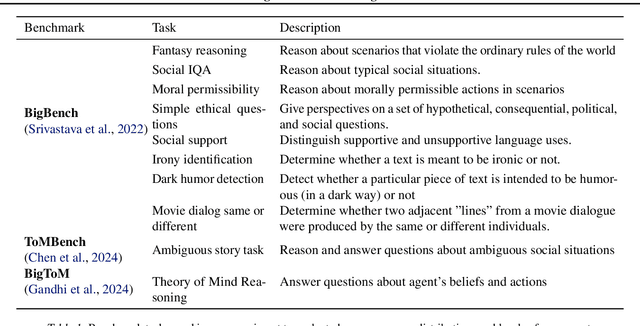
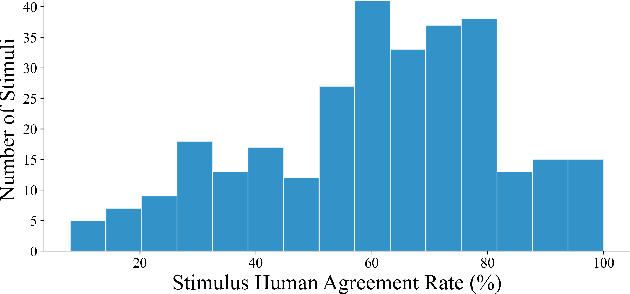
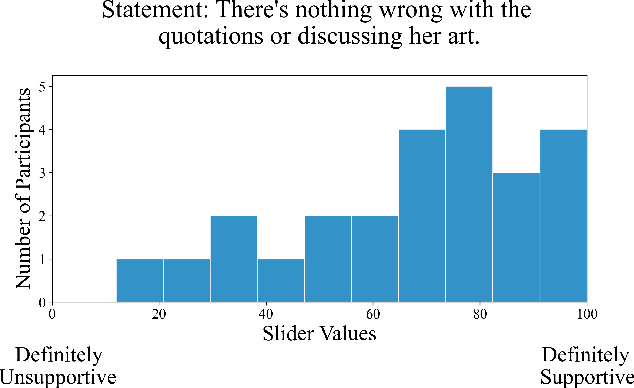
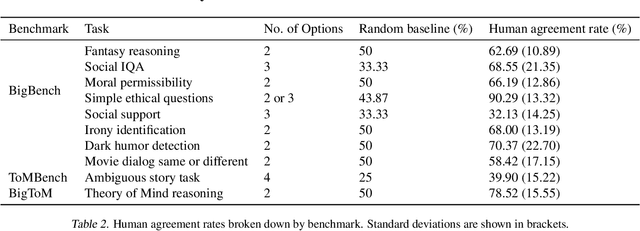
Recent benchmark studies have claimed that AI has approached or even surpassed human-level performances on various cognitive tasks. However, this position paper argues that current AI evaluation paradigms are insufficient for assessing human-like cognitive capabilities. We identify a set of key shortcomings: a lack of human-validated labels, inadequate representation of human response variability and uncertainty, and reliance on simplified and ecologically-invalid tasks. We support our claims by conducting a human evaluation study on ten existing AI benchmarks, suggesting significant biases and flaws in task and label designs. To address these limitations, we propose five concrete recommendations for developing future benchmarks that will enable more rigorous and meaningful evaluations of human-like cognitive capacities in AI with various implications for such AI applications.
Understanding Epistemic Language with a Bayesian Theory of Mind
Aug 21, 2024


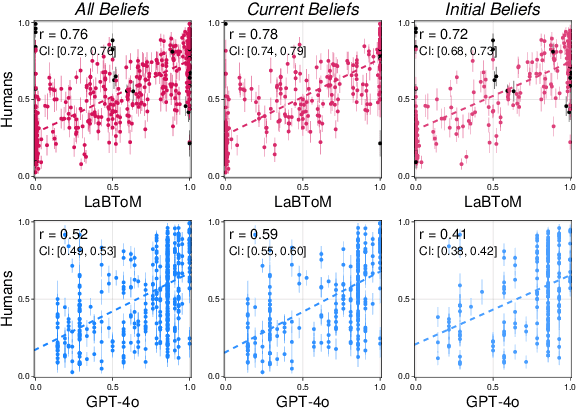
How do people understand and evaluate claims about others' beliefs, even though these beliefs cannot be directly observed? In this paper, we introduce a cognitive model of epistemic language interpretation, grounded in Bayesian inferences about other agents' goals, beliefs, and intentions: a language-augmented Bayesian theory-of-mind (LaBToM). By translating natural language into an epistemic ``language-of-thought'', then evaluating these translations against the inferences produced by inverting a probabilistic generative model of rational action and perception, LaBToM captures graded plausibility judgments about epistemic claims. We validate our model in an experiment where participants watch an agent navigate a maze to find keys hidden in boxes needed to reach their goal, then rate sentences about the agent's beliefs. In contrast with multimodal LLMs (GPT-4o, Gemini Pro) and ablated models, our model correlates highly with human judgments for a wide range of expressions, including modal language, uncertainty expressions, knowledge claims, likelihood comparisons, and attributions of false belief.
Building Machines that Learn and Think with People
Jul 22, 2024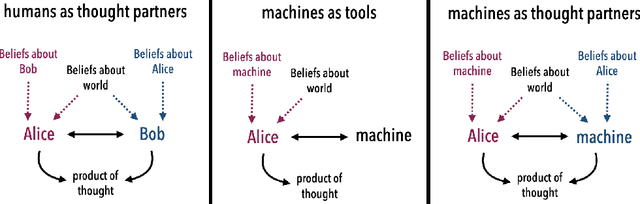
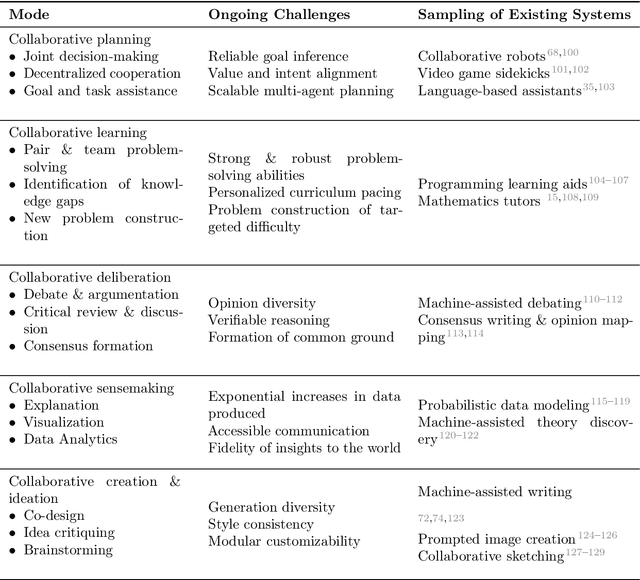
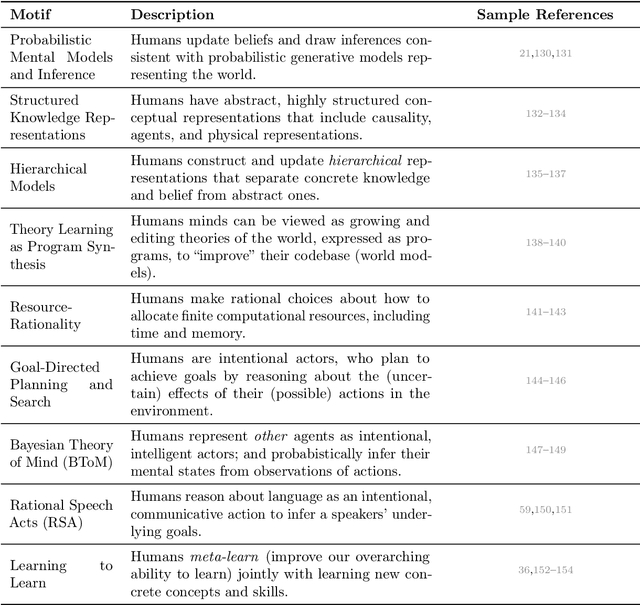
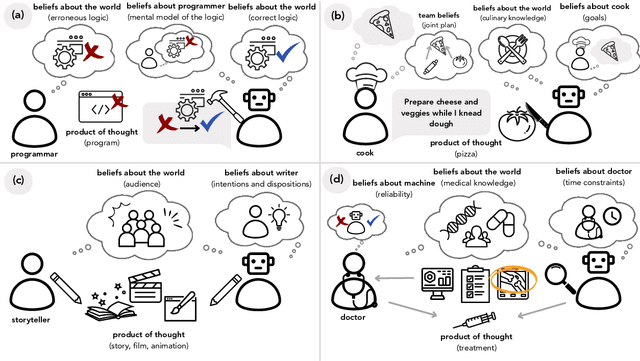
What do we want from machine intelligence? We envision machines that are not just tools for thought, but partners in thought: reasonable, insightful, knowledgeable, reliable, and trustworthy systems that think with us. Current artificial intelligence (AI) systems satisfy some of these criteria, some of the time. In this Perspective, we show how the science of collaborative cognition can be put to work to engineer systems that really can be called ``thought partners,'' systems built to meet our expectations and complement our limitations. We lay out several modes of collaborative thought in which humans and AI thought partners can engage and propose desiderata for human-compatible thought partnerships. Drawing on motifs from computational cognitive science, we motivate an alternative scaling path for the design of thought partners and ecosystems around their use through a Bayesian lens, whereby the partners we construct actively build and reason over models of the human and world.
People use fast, goal-directed simulation to reason about novel games
Jul 19, 2024We can evaluate features of problems and their potential solutions well before we can effectively solve them. When considering a game we have never played, for instance, we might infer whether it is likely to be challenging, fair, or fun simply from hearing the game rules, prior to deciding whether to invest time in learning the game or trying to play it well. Many studies of game play have focused on optimality and expertise, characterizing how people and computational models play based on moderate to extensive search and after playing a game dozens (if not thousands or millions) of times. Here, we study how people reason about a range of simple but novel connect-n style board games. We ask people to judge how fair and how fun the games are from very little experience: just thinking about the game for a minute or so, before they have ever actually played with anyone else, and we propose a resource-limited model that captures their judgments using only a small number of partial game simulations and almost no lookahead search.
Finding structure in logographic writing with library learning
May 11, 2024One hallmark of human language is its combinatoriality -- reusing a relatively small inventory of building blocks to create a far larger inventory of increasingly complex structures. In this paper, we explore the idea that combinatoriality in language reflects a human inductive bias toward representational efficiency in symbol systems. We develop a computational framework for discovering structure in a writing system. Built on top of state-of-the-art library learning and program synthesis techniques, our computational framework discovers known linguistic structures in the Chinese writing system and reveals how the system evolves towards simplification under pressures for representational efficiency. We demonstrate how a library learning approach, utilizing learned abstractions and compression, may help reveal the fundamental computational principles that underlie the creation of combinatorial structures in human cognition, and offer broader insights into the evolution of efficient communication systems.
Grounding Language about Belief in a Bayesian Theory-of-Mind
Feb 16, 2024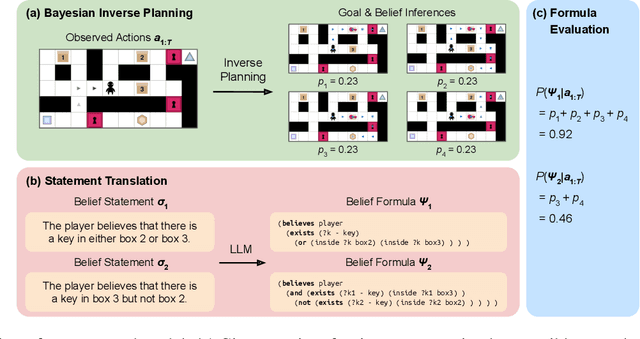


Despite the fact that beliefs are mental states that cannot be directly observed, humans talk about each others' beliefs on a regular basis, often using rich compositional language to describe what others think and know. What explains this capacity to interpret the hidden epistemic content of other minds? In this paper, we take a step towards an answer by grounding the semantics of belief statements in a Bayesian theory-of-mind: By modeling how humans jointly infer coherent sets of goals, beliefs, and plans that explain an agent's actions, then evaluating statements about the agent's beliefs against these inferences via epistemic logic, our framework provides a conceptual role semantics for belief, explaining the gradedness and compositionality of human belief attributions, as well as their intimate connection with goals and plans. We evaluate this framework by studying how humans attribute goals and beliefs while watching an agent solve a doors-and-keys gridworld puzzle that requires instrumental reasoning about hidden objects. In contrast to pure logical deduction, non-mentalizing baselines, and mentalizing that ignores the role of instrumental plans, our model provides a much better fit to human goal and belief attributions, demonstrating the importance of theory-of-mind for a semantics of belief.
Learning adaptive planning representations with natural language guidance
Dec 13, 2023



Effective planning in the real world requires not only world knowledge, but the ability to leverage that knowledge to build the right representation of the task at hand. Decades of hierarchical planning techniques have used domain-specific temporal action abstractions to support efficient and accurate planning, almost always relying on human priors and domain knowledge to decompose hard tasks into smaller subproblems appropriate for a goal or set of goals. This paper describes Ada (Action Domain Acquisition), a framework for automatically constructing task-specific planning representations using task-general background knowledge from language models (LMs). Starting with a general-purpose hierarchical planner and a low-level goal-conditioned policy, Ada interactively learns a library of planner-compatible high-level action abstractions and low-level controllers adapted to a particular domain of planning tasks. On two language-guided interactive planning benchmarks (Mini Minecraft and ALFRED Household Tasks), Ada strongly outperforms other approaches that use LMs for sequential decision-making, offering more accurate plans and better generalization to complex tasks.
LILO: Learning Interpretable Libraries by Compressing and Documenting Code
Oct 30, 2023



While large language models (LLMs) now excel at code generation, a key aspect of software development is the art of refactoring: consolidating code into libraries of reusable and readable programs. In this paper, we introduce LILO, a neurosymbolic framework that iteratively synthesizes, compresses, and documents code to build libraries tailored to particular problem domains. LILO combines LLM-guided program synthesis with recent algorithmic advances in automated refactoring from Stitch: a symbolic compression system that efficiently identifies optimal lambda abstractions across large code corpora. To make these abstractions interpretable, we introduce an auto-documentation (AutoDoc) procedure that infers natural language names and docstrings based on contextual examples of usage. In addition to improving human readability, we find that AutoDoc boosts performance by helping LILO's synthesizer to interpret and deploy learned abstractions. We evaluate LILO on three inductive program synthesis benchmarks for string editing, scene reasoning, and graphics composition. Compared to existing neural and symbolic methods - including the state-of-the-art library learning algorithm DreamCoder - LILO solves more complex tasks and learns richer libraries that are grounded in linguistic knowledge.