 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Art of Building Verifiers for Computer Use Agents
Apr 05, 2026Verifying the success of computer use agent (CUA) trajectories is a critical challenge: without reliable verification, neither evaluation nor training signal can be trusted. In this paper, we present lessons learned from building a best-in-class verifier for web tasks we call the Universal Verifier. We design the Universal Verifier around four key principles: 1) constructing rubrics with meaningful, non-overlapping criteria to reduce noise; 2) separating process and outcome rewards that yield complementary signals, capturing cases where an agent follows the right steps but gets blocked or succeeds through an unexpected path; 3) distinguishing between controllable and uncontrollable failures scored via a cascading-error-free strategy for finer-grained failure understanding; and 4) a divide-and-conquer context management scheme that attends to all screenshots in a trajectory, improving reliability on longer task horizons. We validate these findings on CUAVerifierBench, a new set of CUA trajectories with both process and outcome human labels, showing that our Universal Verifier agrees with humans as often as humans agree with each other. We report a reduction in false positive rates to near zero compared to baselines like WebVoyager ($\geq$ 45\%) and WebJudge ($\geq$ 22\%). We emphasize that these gains stem from the cumulative effect of the design choices above. We also find that an auto-research agent achieves 70\% of expert quality in 5\% of the time, but fails to discover all strategies required to replicate the Universal Verifier. We open-source our Universal Verifier system along with CUAVerifierBench; available at https://github.com/microsoft/fara.
Seeing Through the PRISM: Compound & Controllable Restoration of Scientific Images
Mar 14, 2026Scientific and environmental imagery often suffer from complex mixtures of noise related to the sensor and the environment. Existing restoration methods typically remove one degradation at a time, leading to cascading artifacts, overcorrection, or loss of meaningful signal. In scientific applications, restoration must be able to simultaneously handle compound degradations while allowing experts to selectively remove subsets of distortions without erasing important features. To address these challenges, we present PRISM (Precision Restoration with Interpretable Separation of Mixtures). PRISM is a prompted conditional diffusion framework which combines compound-aware supervision over mixed degradations with a weighted contrastive disentanglement objective that aligns primitives and their mixtures in the latent space. This compositional geometry enables high-fidelity joint removal of overlapping distortions while also allowing flexible, targeted fixes through natural language prompts. Across microscopy, wildlife monitoring, remote sensing, and urban weather datasets, PRISM outperforms state-of-the-art baselines on complex compound degradations, including zero-shot mixtures not seen during training. Importantly, we show that selective restoration significantly improves downstream scientific accuracy in several domains over standard "black-box" restoration. These results establish PRISM as a generalizable and controllable framework for high-fidelity restoration in domains where scientific utility is a priority.
Understanding Electro-communication and Electro-sensing in Weakly Electric Fish using Multi-Agent Deep Reinforcement Learning
Nov 11, 2025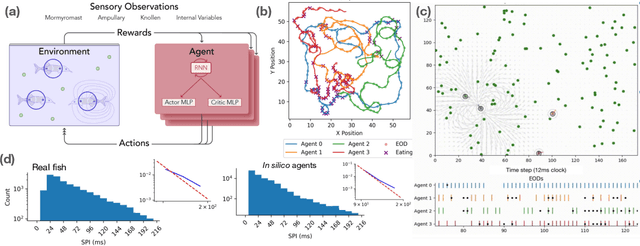
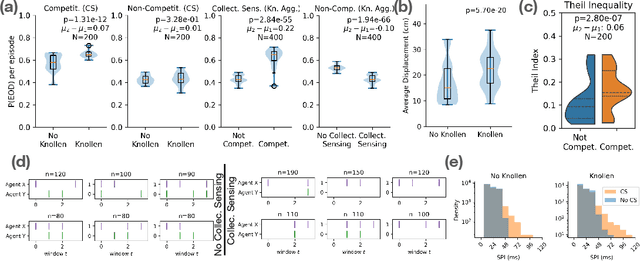
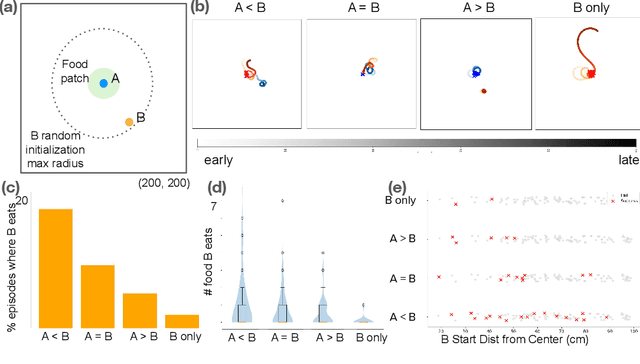
Weakly electric fish, like Gnathonemus petersii, use a remarkable electrical modality for active sensing and communication, but studying their rich electrosensing and electrocommunication behavior and associated neural activity in naturalistic settings remains experimentally challenging. Here, we present a novel biologically-inspired computational framework to study these behaviors, where recurrent neural network (RNN) based artificial agents trained via multi-agent reinforcement learning (MARL) learn to modulate their electric organ discharges (EODs) and movement patterns to collectively forage in virtual environments. Trained agents demonstrate several emergent features consistent with real fish collectives, including heavy tailed EOD interval distributions, environmental context dependent shifts in EOD interval distributions, and social interaction patterns like freeloading, where agents reduce their EOD rates while benefiting from neighboring agents' active sensing. A minimal two-fish assay further isolates the role of electro-communication, showing that access to conspecific EODs and relative dominance jointly shape foraging success. Notably, these behaviors emerge through evolution-inspired rewards for individual fitness and emergent inter-agent interactions, rather than through rewarding agents explicitly for social interactions. Our work has broad implications for the neuroethology of weakly electric fish, as well as other social, communicating animals in which extensive recordings from multiple individuals, and thus traditional data-driven modeling, are infeasible.
Next-Latent Prediction Transformers Learn Compact World Models
Nov 08, 2025Transformers replace recurrence with a memory that grows with sequence length and self-attention that enables ad-hoc look ups over past tokens. Consequently, they lack an inherent incentive to compress history into compact latent states with consistent transition rules. This often leads to learning solutions that generalize poorly. We introduce Next-Latent Prediction (NextLat), which extends standard next-token training with self-supervised predictions in the latent space. Specifically, NextLat trains a transformer to learn latent representations that are predictive of its next latent state given the next output token. Theoretically, we show that these latents provably converge to belief states, compressed information of the history necessary to predict the future. This simple auxiliary objective also injects a recurrent inductive bias into transformers, while leaving their architecture, parallel training, and inference unchanged. NextLat effectively encourages the transformer to form compact internal world models with its own belief states and transition dynamics -- a crucial property absent in standard next-token prediction transformers. Empirically, across benchmarks targeting core sequence modeling competencies -- world modeling, reasoning, planning, and language modeling -- NextLat demonstrates significant gains over standard next-token training in downstream accuracy, representation compression, and lookahead planning. NextLat stands as a simple and efficient paradigm for shaping transformer representations toward stronger generalization.
Compress to Impress: Efficient LLM Adaptation Using a Single Gradient Step on 100 Samples
Oct 23, 2025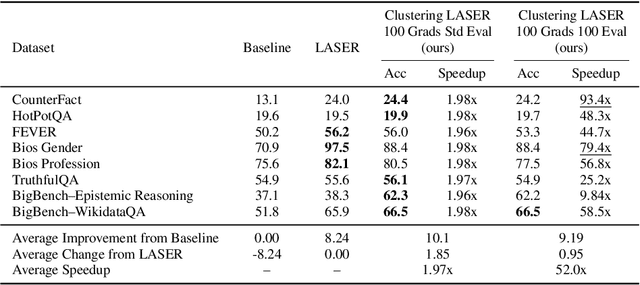
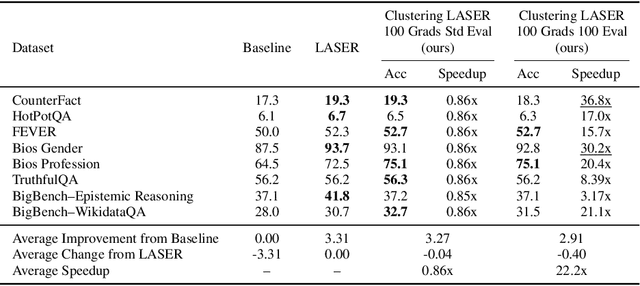
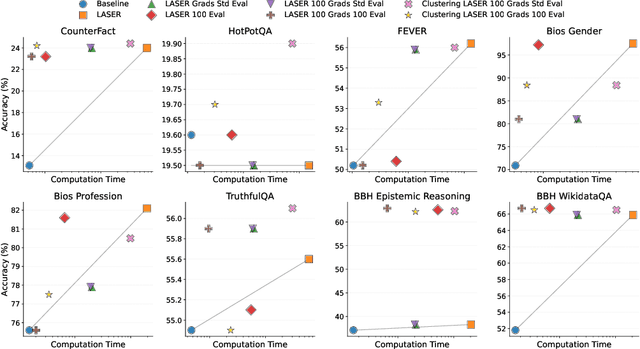
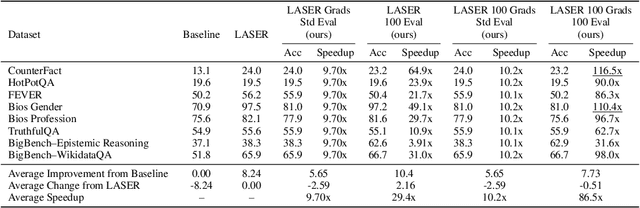
Recently, Sharma et al. suggested a method called Layer-SElective-Rank reduction (LASER) which demonstrated that pruning high-order components of carefully chosen LLM's weight matrices can boost downstream accuracy -- without any gradient-based fine-tuning. Yet LASER's exhaustive, per-matrix search (each requiring full-dataset forward passes) makes it impractical for rapid deployment. We demonstrate that this overhead can be removed and find that: (i) Only a small, carefully chosen subset of matrices needs to be inspected -- eliminating the layer-by-layer sweep, (ii) The gradient of each matrix's singular values pinpoints which matrices merit reduction, (iii) Increasing the factorization search space by allowing matrices rows to cluster around multiple subspaces and then decomposing each cluster separately further reduces overfitting on the original training data and further lifts accuracy by up to 24.6 percentage points, and finally, (iv) we discover that evaluating on just 100 samples rather than the full training data -- both for computing the indicative gradients and for measuring the final accuracy -- suffices to further reduce the search time; we explain that as adaptation to downstream tasks is dominated by prompting style, not dataset size. As a result, we show that combining these findings yields a fast and robust adaptation algorithm for downstream tasks. Overall, with a single gradient step on 100 examples and a quick scan of the top candidate layers and factorization techniques, we can adapt LLMs to new datasets -- entirely without fine-tuning.
What MLLMs Learn about When they Learn about Multimodal Reasoning: Perception, Reasoning, or their Integration?
Oct 02, 2025Multimodal reasoning models have recently shown promise on challenging domains such as olympiad-level geometry, yet their evaluation remains dominated by aggregate accuracy, a single score that obscures where and how models are improving. We introduce MathLens, a benchmark designed to disentangle the subskills of multimodal reasoning while preserving the complexity of textbook-style geometry problems. The benchmark separates performance into three components: Perception: extracting information from raw inputs, Reasoning: operating on available information, and Integration: selecting relevant perceptual evidence and applying it within reasoning. To support each test, we provide annotations: visual diagrams, textual descriptions to evaluate reasoning in isolation, controlled questions that require both modalities, and probes for fine-grained perceptual skills, all derived from symbolic specifications of the problems to ensure consistency and robustness. Our analysis reveals that different training approaches have uneven effects: First, reinforcement learning chiefly strengthens perception, especially when supported by textual supervision, while textual SFT indirectly improves perception through reflective reasoning. Second, reasoning improves only in tandem with perception. Third, integration remains the weakest capacity, with residual errors concentrated there once other skills advance. Finally, robustness diverges: RL improves consistency under diagram variation, whereas multimodal SFT reduces it through overfitting. We will release all data and experimental logs.
LoRA vs Full Fine-tuning: An Illusion of Equivalence
Oct 28, 2024



Fine-tuning is a crucial paradigm for adapting pre-trained large language models to downstream tasks. Recently, methods like Low-Rank Adaptation (LoRA) have been shown to match the performance of fully fine-tuned models on various tasks with an extreme reduction in the number of trainable parameters. Even in settings where both methods learn similarly accurate models, \emph{are their learned solutions really equivalent?} We study how different fine-tuning methods change pre-trained models by analyzing the model's weight matrices through the lens of their spectral properties. We find that full fine-tuning and LoRA yield weight matrices whose singular value decompositions exhibit very different structure; moreover, the fine-tuned models themselves show distinct generalization behaviors when tested outside the adaptation task's distribution. More specifically, we first show that the weight matrices trained with LoRA have new, high-ranking singular vectors, which we call \emph{intruder dimensions}. Intruder dimensions do not appear during full fine-tuning. Second, we show that LoRA models with intruder dimensions, despite achieving similar performance to full fine-tuning on the target task, become worse models of the pre-training distribution and adapt less robustly to multiple tasks sequentially. Higher-rank, rank-stabilized LoRA models closely mirror full fine-tuning, even when performing on par with lower-rank LoRA models on the same tasks. These results suggest that models updated with LoRA and full fine-tuning access different parts of parameter space, even when they perform equally on the fine-tuned distribution. We conclude by examining why intruder dimensions appear in LoRA fine-tuned models, why they are undesirable, and how their effects can be minimized.
Language-guided Skill Learning with Temporal Variational Inference
Feb 26, 2024



We present an algorithm for skill discovery from expert demonstrations. The algorithm first utilizes Large Language Models (LLMs) to propose an initial segmentation of the trajectories. Following that, a hierarchical variational inference framework incorporates the LLM-generated segmentation information to discover reusable skills by merging trajectory segments. To further control the trade-off between compression and reusability, we introduce a novel auxiliary objective based on the Minimum Description Length principle that helps guide this skill discovery process. Our results demonstrate that agents equipped with our method are able to discover skills that help accelerate learning and outperform baseline skill learning approaches on new long-horizon tasks in BabyAI, a grid world navigation environment, as well as ALFRED, a household simulation environment.
A Vision Check-up for Language Models
Jan 03, 2024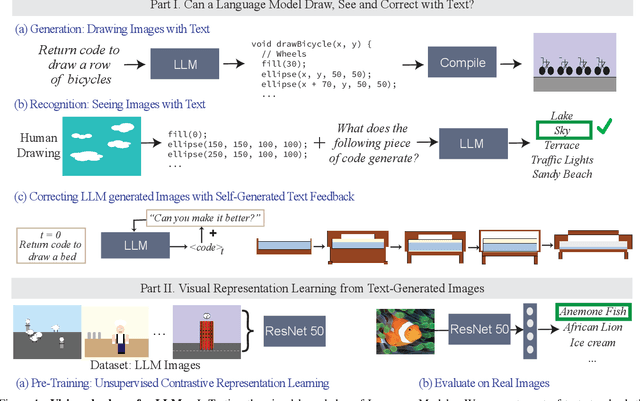
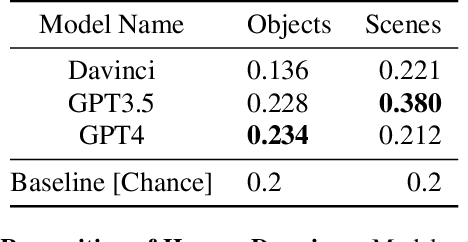

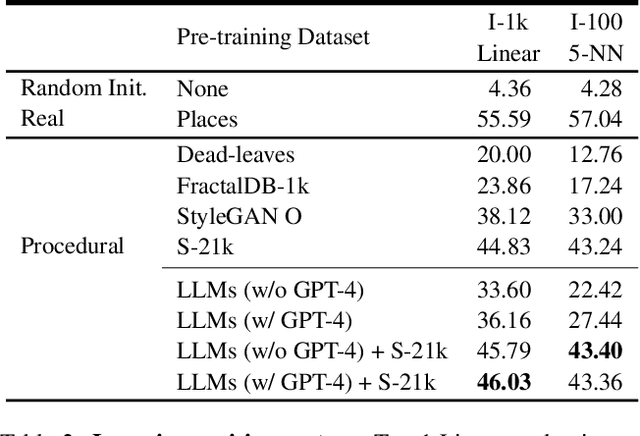
What does learning to model relationships between strings teach large language models (LLMs) about the visual world? We systematically evaluate LLMs' abilities to generate and recognize an assortment of visual concepts of increasing complexity and then demonstrate how a preliminary visual representation learning system can be trained using models of text. As language models lack the ability to consume or output visual information as pixels, we use code to represent images in our study. Although LLM-generated images do not look like natural images, results on image generation and the ability of models to correct these generated images indicate that precise modeling of strings can teach language models about numerous aspects of the visual world. Furthermore, experiments on self-supervised visual representation learning, utilizing images generated with text models, highlight the potential to train vision models capable of making semantic assessments of natural images using just LLMs.
The Truth is in There: Improving Reasoning in Language Models with Layer-Selective Rank Reduction
Dec 21, 2023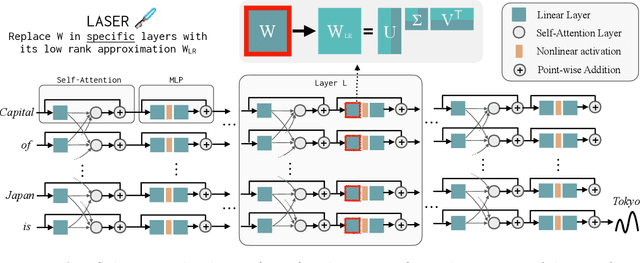



Transformer-based Large Language Models (LLMs) have become a fixture in modern machine learning. Correspondingly, significant resources are allocated towards research that aims to further advance this technology, typically resulting in models of increasing size that are trained on increasing amounts of data. This work, however, demonstrates the surprising result that it is often possible to significantly improve the performance of LLMs by selectively removing higher-order components of their weight matrices. This simple intervention, which we call LAyer-SElective Rank reduction (LASER), can be done on a model after training has completed, and requires no additional parameters or data. We show extensive experiments demonstrating the generality of this finding across language models and datasets, and provide in-depth analyses offering insights into both when LASER is effective and the mechanism by which it operates.