 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Training for Unified Tokenization and Latent Denoising
Mar 23, 2026Latent diffusion models (LDMs) enable high-fidelity synthesis by operating in learned latent spaces. However, training state-of-the-art LDMs requires complex staging: a tokenizer must be trained first, before the diffusion model can be trained in the frozen latent space. We propose UNITE - an autoencoder architecture for unified tokenization and latent diffusion. UNITE consists of a Generative Encoder that serves as both image tokenizer and latent generator via weight sharing. Our key insight is that tokenization and generation can be viewed as the same latent inference problem under different conditioning regimes: tokenization infers latents from fully observed images, whereas generation infers them from noise together with text or class conditioning. Motivated by this, we introduce a single-stage training procedure that jointly optimizes both tasks via two forward passes through the same Generative Encoder. The shared parameters enable gradients to jointly shape the latent space, encouraging a "common latent language". Across image and molecule modalities, UNITE achieves near state of the art performance without adversarial losses or pretrained encoders (e.g., DINO), reaching FID 2.12 and 1.73 for Base and Large models on ImageNet 256 x 256. We further analyze the Generative Encoder through the lenses of representation alignment and compression. These results show that single stage joint training of tokenization & generation from scratch is feasible.
Single-pass Adaptive Image Tokenization for Minimum Program Search
Jul 10, 2025According to Algorithmic Information Theory (AIT) -- Intelligent representations compress data into the shortest possible program that can reconstruct its content, exhibiting low Kolmogorov Complexity (KC). In contrast, most visual representation learning systems use fixed-length representations for all inputs, ignoring variations in complexity or familiarity. Recent adaptive tokenization methods address this by allocating variable-length representations but typically require test-time search over multiple encodings to find the most predictive one. Inspired by Kolmogorov Complexity principles, we propose a single-pass adaptive tokenizer, KARL, which predicts the appropriate number of tokens for an image in a single forward pass, halting once its approximate KC is reached. The token count serves as a proxy for the minimum description length. KARL's training procedure closely resembles the Upside-Down Reinforcement Learning paradigm, as it learns to conditionally predict token halting based on a desired reconstruction quality. KARL matches the performance of recent adaptive tokenizers while operating in a single pass. We present scaling laws for KARL, analyzing the role of encoder/decoder size, continuous vs. discrete tokenization and more. Additionally, we offer a conceptual study drawing an analogy between Adaptive Image Tokenization and Algorithmic Information Theory, examining the predicted image complexity (KC) across axes such as structure vs. noise and in- vs. out-of-distribution familiarity -- revealing alignment with human intuition.
Eval3D: Interpretable and Fine-grained Evaluation for 3D Generation
Apr 25, 2025Despite the unprecedented progress in the field of 3D generation, current systems still often fail to produce high-quality 3D assets that are visually appealing and geometrically and semantically consistent across multiple viewpoints. To effectively assess the quality of the generated 3D data, there is a need for a reliable 3D evaluation tool. Unfortunately, existing 3D evaluation metrics often overlook the geometric quality of generated assets or merely rely on black-box multimodal large language models for coarse assessment. In this paper, we introduce Eval3D, a fine-grained, interpretable evaluation tool that can faithfully evaluate the quality of generated 3D assets based on various distinct yet complementary criteria. Our key observation is that many desired properties of 3D generation, such as semantic and geometric consistency, can be effectively captured by measuring the consistency among various foundation models and tools. We thus leverage a diverse set of models and tools as probes to evaluate the inconsistency of generated 3D assets across different aspects. Compared to prior work, Eval3D provides pixel-wise measurement, enables accurate 3D spatial feedback, and aligns more closely with human judgments. We comprehensively evaluate existing 3D generation models using Eval3D and highlight the limitations and challenges of current models.
Adaptive Length Image Tokenization via Recurrent Allocation
Nov 04, 2024



Current vision systems typically assign fixed-length representations to images, regardless of the information content. This contrasts with human intelligence - and even large language models - which allocate varying representational capacities based on entropy, context and familiarity. Inspired by this, we propose an approach to learn variable-length token representations for 2D images. Our encoder-decoder architecture recursively processes 2D image tokens, distilling them into 1D latent tokens over multiple iterations of recurrent rollouts. Each iteration refines the 2D tokens, updates the existing 1D latent tokens, and adaptively increases representational capacity by adding new tokens. This enables compression of images into a variable number of tokens, ranging from 32 to 256. We validate our tokenizer using reconstruction loss and FID metrics, demonstrating that token count aligns with image entropy, familiarity and downstream task requirements. Recurrent token processing with increasing representational capacity in each iteration shows signs of token specialization, revealing potential for object / part discovery.
A Vision Check-up for Language Models
Jan 03, 2024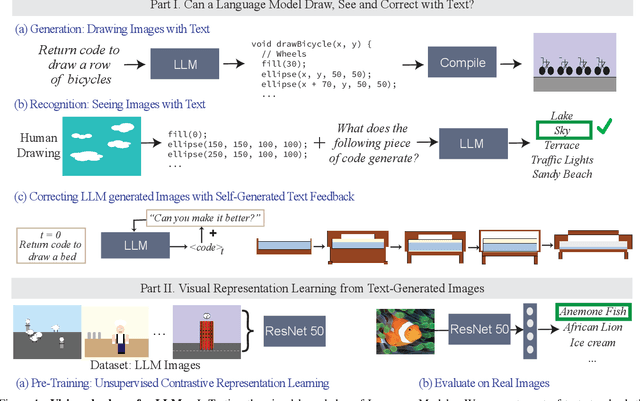
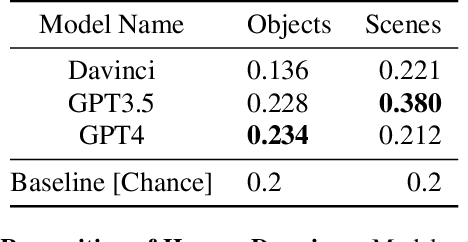

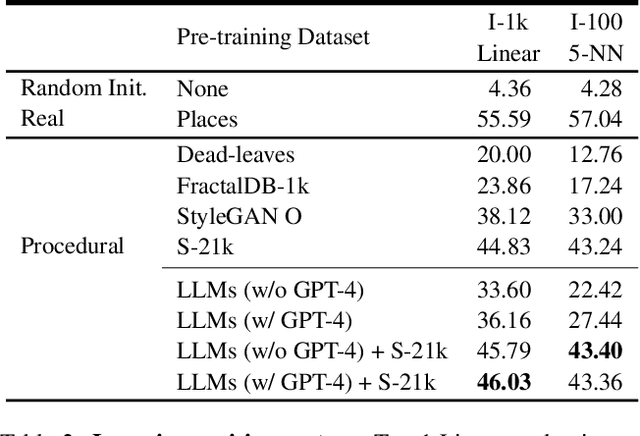
What does learning to model relationships between strings teach large language models (LLMs) about the visual world? We systematically evaluate LLMs' abilities to generate and recognize an assortment of visual concepts of increasing complexity and then demonstrate how a preliminary visual representation learning system can be trained using models of text. As language models lack the ability to consume or output visual information as pixels, we use code to represent images in our study. Although LLM-generated images do not look like natural images, results on image generation and the ability of models to correct these generated images indicate that precise modeling of strings can teach language models about numerous aspects of the visual world. Furthermore, experiments on self-supervised visual representation learning, utilizing images generated with text models, highlight the potential to train vision models capable of making semantic assessments of natural images using just LLMs.
Your Diffusion Model is Secretly a Zero-Shot Classifier
Mar 29, 2023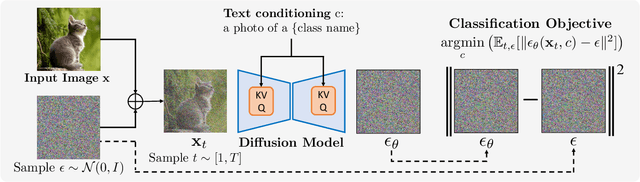

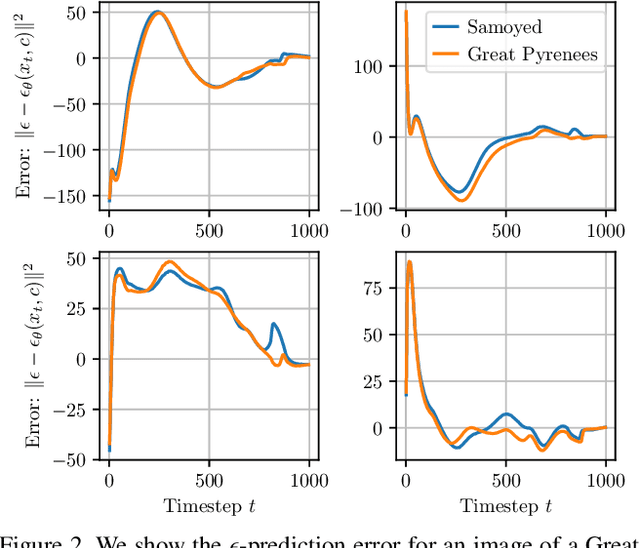
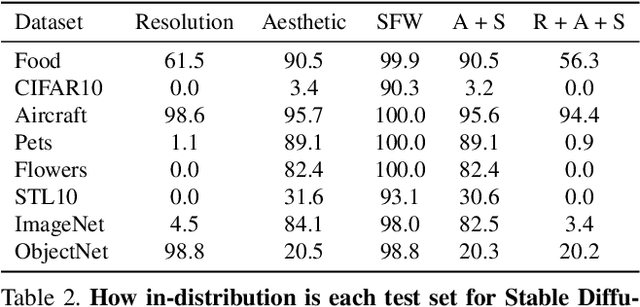
The recent wave of large-scale text-to-image diffusion models has dramatically increased our text-based image generation abilities. These models can generate realistic images for a staggering variety of prompts and exhibit impressive compositional generalization abilities. Almost all use cases thus far have solely focused on sampling; however, diffusion models can also provide conditional density estimates, which are useful for tasks beyond image generation. In this paper, we show that the density estimates from large-scale text-to-image diffusion models like Stable Diffusion can be leveraged to perform zero-shot classification without any additional training. Our generative approach to classification, which we call Diffusion Classifier, attains strong results on a variety of benchmarks and outperforms alternative methods of extracting knowledge from diffusion models. Although a gap remains between generative and discriminative approaches on zero-shot recognition tasks, we find that our diffusion-based approach has stronger multimodal relational reasoning abilities than competing discriminative approaches. Finally, we use Diffusion Classifier to extract standard classifiers from class-conditional diffusion models trained on ImageNet. Even though these models are trained with weak augmentations and no regularization, they approach the performance of SOTA discriminative classifiers. Overall, our results are a step toward using generative over discriminative models for downstream tasks. Results and visualizations at https://diffusion-classifier.github.io/
NeuralODF: Learning Omnidirectional Distance Fields for 3D Shape Representation
Jun 12, 2022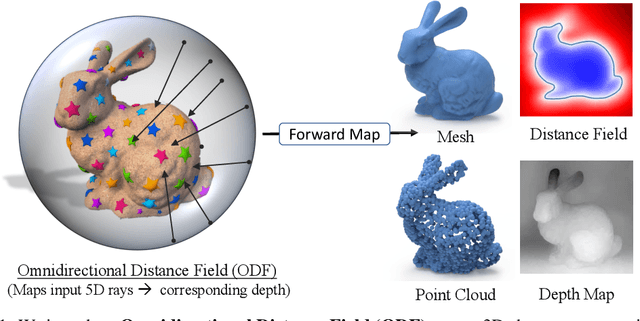

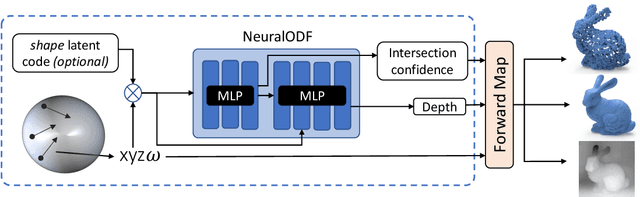
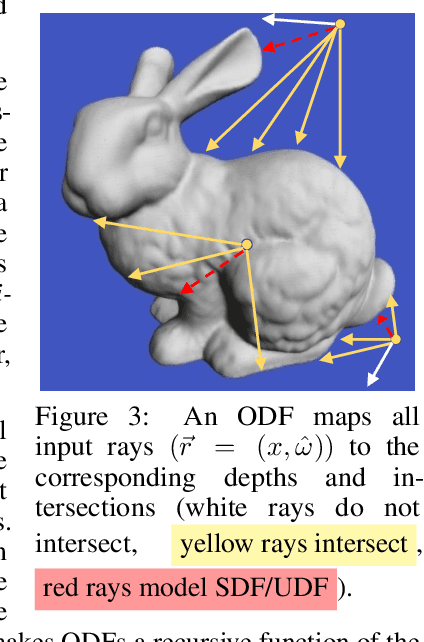
In visual computing, 3D geometry is represented in many different forms including meshes, point clouds, voxel grids, level sets, and depth images. Each representation is suited for different tasks thus making the transformation of one representation into another (forward map) an important and common problem. We propose Omnidirectional Distance Fields (ODFs), a new 3D shape representation that encodes geometry by storing the depth to the object's surface from any 3D position in any viewing direction. Since rays are the fundamental unit of an ODF, it can be used to easily transform to and from common 3D representations like meshes or point clouds. Different from level set methods that are limited to representing closed surfaces, ODFs are unsigned and can thus model open surfaces (e.g., garments). We demonstrate that ODFs can be effectively learned with a neural network (NeuralODF) despite the inherent discontinuities at occlusion boundaries. We also introduce efficient forward mapping algorithms for transforming ODFs to and from common 3D representations. Specifically, we introduce an efficient Jumping Cubes algorithm for generating meshes from ODFs. Experiments demonstrate that NeuralODF can learn to capture high-quality shape by overfitting to a single object, and also learn to generalize on common shape categories.
Topologically-Aware Deformation Fields for Single-View 3D Reconstruction
May 21, 2022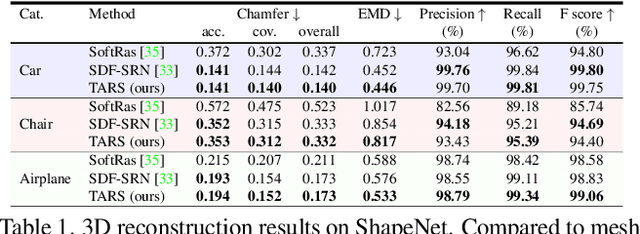
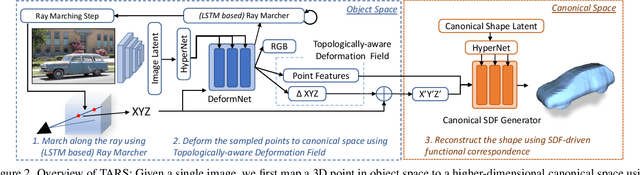

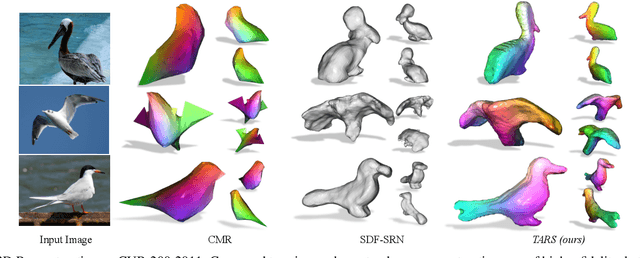
We present a framework for learning 3D object shapes and dense cross-object 3D correspondences from just an unaligned category-specific image collection. The 3D shapes are generated implicitly as deformations to a category-specific signed distance field and are learned in an unsupervised manner solely from unaligned image collections and their poses without any 3D supervision. Generally, image collections on the internet contain several intra-category geometric and topological variations, for example, different chairs can have different topologies, which makes the task of joint shape and correspondence estimation much more challenging. Because of this, prior works either focus on learning each 3D object shape individually without modeling cross-instance correspondences or perform joint shape and correspondence estimation on categories with minimal intra-category topological variations. We overcome these restrictions by learning a topologically-aware implicit deformation field that maps a 3D point in the object space to a higher dimensional point in the category-specific canonical space. At inference time, given a single image, we reconstruct the underlying 3D shape by first implicitly deforming each 3D point in the object space to the learned category-specific canonical space using the topologically-aware deformation field and then reconstructing the 3D shape as a canonical signed distance field. Both canonical shape and deformation field are learned end-to-end in an inverse-graphics fashion using a learned recurrent ray marcher (SRN) as a differentiable rendering module. Our approach, dubbed TARS, achieves state-of-the-art reconstruction fidelity on several datasets: ShapeNet, Pascal3D+, CUB, and Pix3D chairs. Result videos and code at https://shivamduggal4.github.io/tars-3D/
Secrets of 3D Implicit Object Shape Reconstruction in the Wild
Jan 18, 2021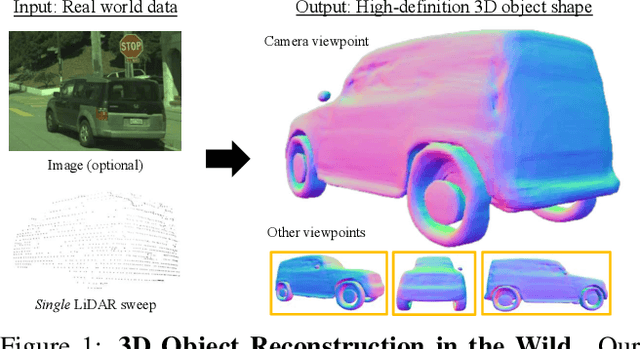
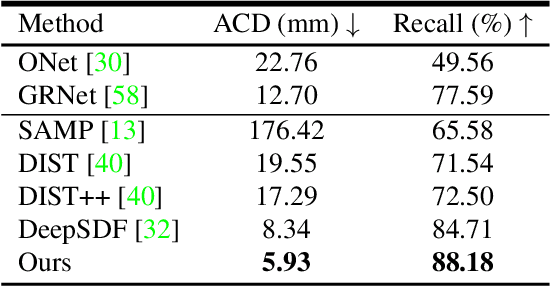

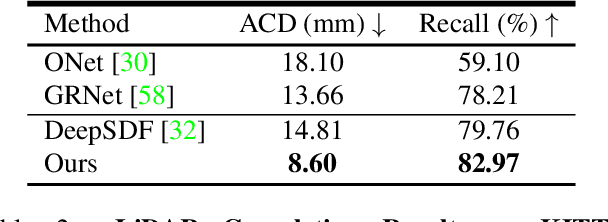
Reconstructing high-fidelity 3D objects from sparse, partial observation is of crucial importance for various applications in computer vision, robotics, and graphics. While recent neural implicit modeling methods show promising results on synthetic or dense datasets, they perform poorly on real-world data that is sparse and noisy. This paper analyzes the root cause of such deficient performance of a popular neural implicit model. We discover that the limitations are due to highly complicated objectives, lack of regularization, and poor initialization. To overcome these issues, we introduce two simple yet effective modifications: (i) a deep encoder that provides a better and more stable initialization for latent code optimization; and (ii) a deep discriminator that serves as a prior model to boost the fidelity of the shape. We evaluate our approach on two real-wold self-driving datasets and show superior performance over state-of-the-art 3D object reconstruction methods.
GeoSim: Photorealistic Image Simulation with Geometry-Aware Composition
Jan 16, 2021
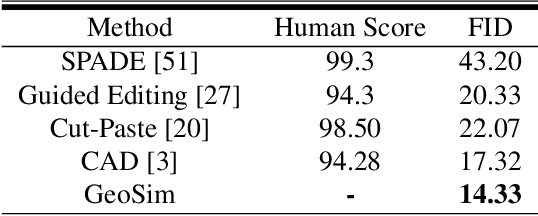
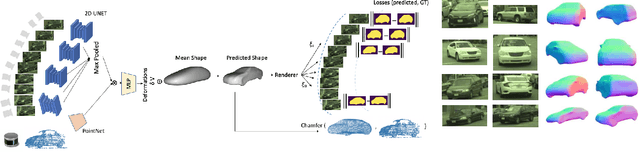

Scalable sensor simulation is an important yet challenging open problem for safety-critical domains such as self-driving. Current work in image simulation either fail to be photorealistic or do not model the 3D environment and the dynamic objects within, losing high-level control and physical realism. In this paper, we present GeoSim, a geometry-aware image composition process that synthesizes novel urban driving scenes by augmenting existing images with dynamic objects extracted from other scenes and rendered at novel poses. Towards this goal, we first build a diverse bank of 3D objects with both realistic geometry and appearance from sensor data. During simulation, we perform a novel geometry-aware simulation-by-composition procedure which 1) proposes plausible and realistic object placements into a given scene, 2) renders novel views of dynamic objects from the asset bank, and 3) composes and blends the rendered image segments. The resulting synthetic images are photorealistic, traffic-aware, and geometrically consistent, allowing image simulation to scale to complex use cases. We demonstrate two such important applications: long-range realistic video simulation across multiple camera sensors, and synthetic data generation for data augmentation on downstream segmentation tasks.