 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-to-Image Models Need Less from Text Encoders Than You Think
Jun 02, 2026Text-to-image models rely on text prompts as their primary interface to human intent. Prompts are encoded by a text encoder into embeddings that condition the image generation process. Beyond individual token meanings, text embeddings encode contextual information across the full prompt, such as compositionality and attribute binding. However, whether image models actually exploit this richer information remains underexplored. Here, we address the question: Which aspects of text representation are essential for image generation? We show that text-to-image diffusion transformer-based models commonly rely only on two relatively straightforward aspects of text representations: (i) the merging of adjacent tokens into a word representation, for words spanning multiple tokens, and (ii) word order, which is imprinted by the positional embedding of the text-encoder. To show this, we construct a new text embedding that encodes only individual word meanings and order but lacks any contextual information about the full prompt. We find that this bag of position-tagged words representation is sufficient to successfully guide image generation, achieving visual quality and text fidelity that are on par with full text embedding-guided generation. This demonstrates that, contrary to common belief, text-to-image models often do not use the rich information encoded in the text embedding beyond individual word meanings and word order. Instead, the decoding of complex linguistic structures is performed by the image model itself. Project webpage: https://nsping13.github.io/contextless-TTI/
Vision-Language Binding in In-Context Image Generation
May 23, 2026In-context image generation models such as FLUX.2 take a text prompt and an optional reference image as visual conditioning for the output. Internally, all three inputs -- text, reference image, and the noise tokens -- are concatenated and processed through a single attention stream, where all tokens can attend to one another. This leaves open how reference information flows through the model to produce the output image. We show that an implicit cross-modal binding emerges between the text tokens and the reference image: the text tokens absorb visual reference content during the forward pass, and that absorbed content causally influences the generated output. We surface this binding with three causal interventions on FLUX.2: T2I Lens, which decodes intermediate text-token activations through a text-to-image path; Attention Knockout, which severs specific attention edges; and I2I-to-I2I Patching, which copies text token activations between editing runs. Across 2,875 editing tasks on various images, including SUN397 and DreamBench++ datasets and images collected online, we observe a consistent division of labor: properties of the reference image, like color, style, and scene setting, are first written into the text tokens, which carry them to the generated image; pixel-exact properties like a specific face or instance identity bypass the text tokens and flow directly from reference to image through image-to-image attention. We further localize the reference-text binding to the padding tokens of the text sequence. These results show that text tokens in a multimodal DiT are not just prompt holders, but a structured channel for reference image content. More broadly, they suggest that even in unified-attention multimodal generative models, token modality structures how conditioning information is represented and routed across the network.
From Activation to Causality: Discovery of Causal Visual Representations in the Human Brain
May 22, 2026Identifying which brain regions represent a visual concept in the human brain is a central challenge in neuroscience. Existing approaches have localized coarse functional regions (e.g., faces, places) through activation maximization, identifying regions that activate strongly for a target concept relative to other concepts. Yet strong activation alone does not establish that a region represents the concept itself, as responses may instead be driven by correlated visual or semantic cues. We introduce BrainCause, an automated framework that combines generative and brain models to synthesize controlled stimuli and validate neural representations through targeted causal testing. Given a query specifying a concept of interest, our framework constructs targeted stimulus sets comprising concept images, counterfactual edits that remove the target concept while preserving other image content, and images with candidate correlated distractors. It then uses an image-to-fMRI encoding model to predict brain responses and searches for representations that respond specifically to the target concept over correlated alternatives. BrainCause returns validated candidate representations and proposes follow-up fMRI experiments to further test or extend its discoveries. Our approach successfully recovers known functional localizations and identifies new candidate representations across dozens of concepts, validated on both predicted and measured fMRI data. Critically, we show that without causal validation, a large fraction of localizations would be false positives, confirming that activation alone is insufficient evidence of representation.
The Dual Mechanisms of Spatial Reasoning in Vision-Language Models
Mar 23, 2026Many multimodal tasks, such as image captioning and visual question answering, require vision-language models (VLMs) to associate objects with their properties and spatial relations. Yet it remains unclear where and how such associations are computed within VLMs. In this work, we show that VLMs rely on two concurrent mechanisms to represent such associations. In the language model backbone, intermediate layers represent content-independent spatial relations on top of visual tokens corresponding to objects. However, this mechanism plays only a secondary role in shaping model predictions. Instead, the dominant source of spatial information originates in the vision encoder, whose representations encode the layout of objects and are directly exploited by the language model backbone. Notably, this spatial signal is distributed globally across visual tokens, extending beyond object regions into surrounding background areas. We show that enhancing these vision-derived spatial representations globally across all image tokens improves spatial reasoning performance on naturalistic images. Together, our results clarify how spatial association is computed within VLMs and highlight the central role of vision encoders in enabling spatial reasoning.
Pitfalls in Evaluating Interpretability Agents
Mar 20, 2026Automated interpretability systems aim to reduce the need for human labor and scale analysis to increasingly large models and diverse tasks. Recent efforts toward this goal leverage large language models (LLMs) at increasing levels of autonomy, ranging from fixed one-shot workflows to fully autonomous interpretability agents. This shift creates a corresponding need to scale evaluation approaches to keep pace with both the volume and complexity of generated explanations. We investigate this challenge in the context of automated circuit analysis -- explaining the roles of model components when performing specific tasks. To this end, we build an agentic system in which a research agent iteratively designs experiments and refines hypotheses. When evaluated against human expert explanations across six circuit analysis tasks in the literature, the system appears competitive. However, closer examination reveals several pitfalls of replication-based evaluation: human expert explanations can be subjective or incomplete, outcome-based comparisons obscure the research process, and LLM-based systems may reproduce published findings via memorization or informed guessing. To address some of these pitfalls, we propose an unsupervised intrinsic evaluation based on the functional interchangeability of model components. Our work demonstrates fundamental challenges in evaluating complex automated interpretability systems and reveals key limitations of replication-based evaluation.
Agents of Chaos
Feb 23, 2026We report an exploratory red-teaming study of autonomous language-model-powered agents deployed in a live laboratory environment with persistent memory, email accounts, Discord access, file systems, and shell execution. Over a two-week period, twenty AI researchers interacted with the agents under benign and adversarial conditions. Focusing on failures emerging from the integration of language models with autonomy, tool use, and multi-party communication, we document eleven representative case studies. Observed behaviors include unauthorized compliance with non-owners, disclosure of sensitive information, execution of destructive system-level actions, denial-of-service conditions, uncontrolled resource consumption, identity spoofing vulnerabilities, cross-agent propagation of unsafe practices, and partial system takeover. In several cases, agents reported task completion while the underlying system state contradicted those reports. We also report on some of the failed attempts. Our findings establish the existence of security-, privacy-, and governance-relevant vulnerabilities in realistic deployment settings. These behaviors raise unresolved questions regarding accountability, delegated authority, and responsibility for downstream harms, and warrant urgent attention from legal scholars, policymakers, and researchers across disciplines. This report serves as an initial empirical contribution to that broader conversation.
BrainExplore: Large-Scale Discovery of Interpretable Visual Representations in the Human Brain
Dec 12, 2025
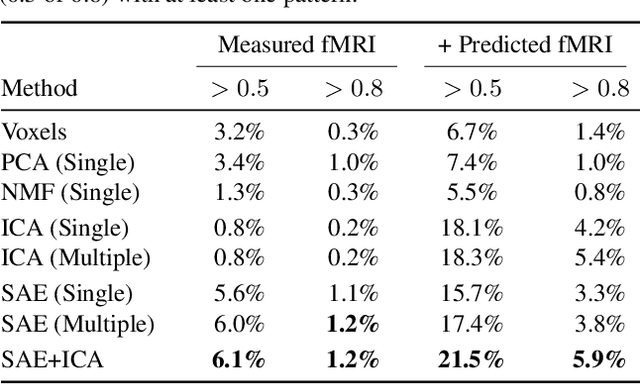
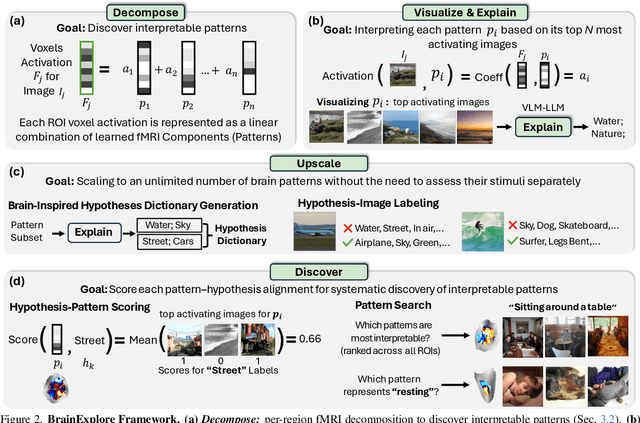

Understanding how the human brain represents visual concepts, and in which brain regions these representations are encoded, remains a long-standing challenge. Decades of work have advanced our understanding of visual representations, yet brain signals remain large and complex, and the space of possible visual concepts is vast. As a result, most studies remain small-scale, rely on manual inspection, focus on specific regions and properties, and rarely include systematic validation. We present a large-scale, automated framework for discovering and explaining visual representations across the human cortex. Our method comprises two main stages. First, we discover candidate interpretable patterns in fMRI activity through unsupervised, data-driven decomposition methods. Next, we explain each pattern by identifying the set of natural images that most strongly elicit it and generating a natural-language description of their shared visual meaning. To scale this process, we introduce an automated pipeline that tests multiple candidate explanations, assigns quantitative reliability scores, and selects the most consistent description for each voxel pattern. Our framework reveals thousands of interpretable patterns spanning many distinct visual concepts, including fine-grained representations previously unreported.
Automated Detection of Visual Attribute Reliance with a Self-Reflective Agent
Oct 24, 2025When a vision model performs image recognition, which visual attributes drive its predictions? Detecting unintended reliance on specific visual features is critical for ensuring model robustness, preventing overfitting, and avoiding spurious correlations. We introduce an automated framework for detecting such dependencies in trained vision models. At the core of our method is a self-reflective agent that systematically generates and tests hypotheses about visual attributes that a model may rely on. This process is iterative: the agent refines its hypotheses based on experimental outcomes and uses a self-evaluation protocol to assess whether its findings accurately explain model behavior. When inconsistencies arise, the agent self-reflects over its findings and triggers a new cycle of experimentation. We evaluate our approach on a novel benchmark of 130 models designed to exhibit diverse visual attribute dependencies across 18 categories. Our results show that the agent's performance consistently improves with self-reflection, with a significant performance increase over non-reflective baselines. We further demonstrate that the agent identifies real-world visual attribute dependencies in state-of-the-art models, including CLIP's vision encoder and the YOLOv8 object detector.
Language Models use Lookbacks to Track Beliefs
May 20, 2025How do language models (LMs) represent characters' beliefs, especially when those beliefs may differ from reality? This question lies at the heart of understanding the Theory of Mind (ToM) capabilities of LMs. We analyze Llama-3-70B-Instruct's ability to reason about characters' beliefs using causal mediation and abstraction. We construct a dataset that consists of simple stories where two characters each separately change the state of two objects, potentially unaware of each other's actions. Our investigation uncovered a pervasive algorithmic pattern that we call a lookback mechanism, which enables the LM to recall important information when it becomes necessary. The LM binds each character-object-state triple together by co-locating reference information about them, represented as their Ordering IDs (OIs) in low rank subspaces of the state token's residual stream. When asked about a character's beliefs regarding the state of an object, the binding lookback retrieves the corresponding state OI and then an answer lookback retrieves the state token. When we introduce text specifying that one character is (not) visible to the other, we find that the LM first generates a visibility ID encoding the relation between the observing and the observed character OIs. In a visibility lookback, this ID is used to retrieve information about the observed character and update the observing character's beliefs. Our work provides insights into the LM's belief tracking mechanisms, taking a step toward reverse-engineering ToM reasoning in LMs.
SketchAgent: Language-Driven Sequential Sketch Generation
Nov 26, 2024Sketching serves as a versatile tool for externalizing ideas, enabling rapid exploration and visual communication that spans various disciplines. While artificial systems have driven substantial advances in content creation and human-computer interaction, capturing the dynamic and abstract nature of human sketching remains challenging. In this work, we introduce SketchAgent, a language-driven, sequential sketch generation method that enables users to create, modify, and refine sketches through dynamic, conversational interactions. Our approach requires no training or fine-tuning. Instead, we leverage the sequential nature and rich prior knowledge of off-the-shelf multimodal large language models (LLMs). We present an intuitive sketching language, introduced to the model through in-context examples, enabling it to "draw" using string-based actions. These are processed into vector graphics and then rendered to create a sketch on a pixel canvas, which can be accessed again for further tasks. By drawing stroke by stroke, our agent captures the evolving, dynamic qualities intrinsic to sketching. We demonstrate that SketchAgent can generate sketches from diverse prompts, engage in dialogue-driven drawing, and collaborate meaningfully with human users.