 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning Theater: Disentangling Model Beliefs from Chain-of-Thought
Mar 05, 2026We provide evidence of performative chain-of-thought (CoT) in reasoning models, where a model becomes strongly confident in its final answer, but continues generating tokens without revealing its internal belief. Our analysis compares activation probing, early forced answering, and a CoT monitor across two large models (DeepSeek-R1 671B & GPT-OSS 120B) and find task difficulty-specific differences: The model's final answer is decodable from activations far earlier in CoT than a monitor is able to say, especially for easy recall-based MMLU questions. We contrast this with genuine reasoning in difficult multihop GPQA-Diamond questions. Despite this, inflection points (e.g., backtracking, 'aha' moments) occur almost exclusively in responses where probes show large belief shifts, suggesting these behaviors track genuine uncertainty rather than learned "reasoning theater." Finally, probe-guided early exit reduces tokens by up to 80% on MMLU and 30% on GPQA-Diamond with similar accuracy, positioning attention probing as an efficient tool for detecting performative reasoning and enabling adaptive computation.
Surgical Activation Steering via Generative Causal Mediation
Feb 17, 2026Where should we intervene in a language model (LM) to control behaviors that are diffused across many tokens of a long-form response? We introduce Generative Causal Mediation (GCM), a procedure for selecting model components, e.g., attention heads, to steer a binary concept (e.g., talk in verse vs. talk in prose) from contrastive long-form responses. In GCM, we first construct a dataset of contrasting inputs and responses. Then, we quantify how individual model components mediate the contrastive concept and select the strongest mediators for steering. We evaluate GCM on three tasks--refusal, sycophancy, and style transfer--across three language models. GCM successfully localizes concepts expressed in long-form responses and consistently outperforms correlational probe-based baselines when steering with a sparse set of attention heads. Together, these results demonstrate that GCM provides an effective approach for localizing and controlling the long-form responses of LMs.
The Shape of Beliefs: Geometry, Dynamics, and Interventions along Representation Manifolds of Language Models' Posteriors
Feb 02, 2026Large language models (LLMs) represent prompt-conditioned beliefs (posteriors over answers and claims), but we lack a mechanistic account of how these beliefs are encoded in representation space, how they update with new evidence, and how interventions reshape them. We study a controlled setting in which Llama-3.2 generates samples from a normal distribution by implicitly inferring its parameters (mean and standard deviation) given only samples from the distribution in context. We find representations of curved "belief manifolds" for these parameters form with sufficient in-context learning and study how the model adapts when the distribution suddenly changes. While standard linear steering often pushes the model off-manifold and induces coupled, out-of-distribution shifts, geometry and field-aware steering better preserves the intended belief family. Our work demonstrates an example of linear field probing (LFP) as a simple approach to tile the data manifold and make interventions that respect the underlying geometry. We conclude that rich structure emerges naturally in LLMs and that purely linear concept representations are often an inadequate abstraction.
From Directions to Regions: Decomposing Activations in Language Models via Local Geometry
Feb 02, 2026Activation decomposition methods in language models are tightly coupled to geometric assumptions on how concepts are realized in activation space. Existing approaches search for individual global directions, implicitly assuming linear separability, which overlooks concepts with nonlinear or multi-dimensional structure. In this work, we leverage Mixture of Factor Analyzers (MFA) as a scalable, unsupervised alternative that models the activation space as a collection of Gaussian regions with their local covariance structure. MFA decomposes activations into two compositional geometric objects: the region's centroid in activation space, and the local variation from the centroid. We train large-scale MFAs for Llama-3.1-8B and Gemma-2-2B, and show they capture complex, nonlinear structures in activation space. Moreover, evaluations on localization and steering benchmarks show that MFA outperforms unsupervised baselines, is competitive with supervised localization methods, and often achieves stronger steering performance than sparse autoencoders. Together, our findings position local geometry, expressed through subspaces, as a promising unit of analysis for scalable concept discovery and model control, accounting for complex structures that isolated directions fail to capture.
Are language models aware of the road not taken? Token-level uncertainty and hidden state dynamics
Nov 06, 2025When a language model generates text, the selection of individual tokens might lead it down very different reasoning paths, making uncertainty difficult to quantify. In this work, we consider whether reasoning language models represent the alternate paths that they could take during generation. To test this hypothesis, we use hidden activations to control and predict a language model's uncertainty during chain-of-thought reasoning. In our experiments, we find a clear correlation between how uncertain a model is at different tokens, and how easily the model can be steered by controlling its activations. This suggests that activation interventions are most effective when there are alternate paths available to the model -- in other words, when it has not yet committed to a particular final answer. We also find that hidden activations can predict a model's future outcome distribution, demonstrating that models implicitly represent the space of possible paths.
Decomposing MLP Activations into Interpretable Features via Semi-Nonnegative Matrix Factorization
Jun 12, 2025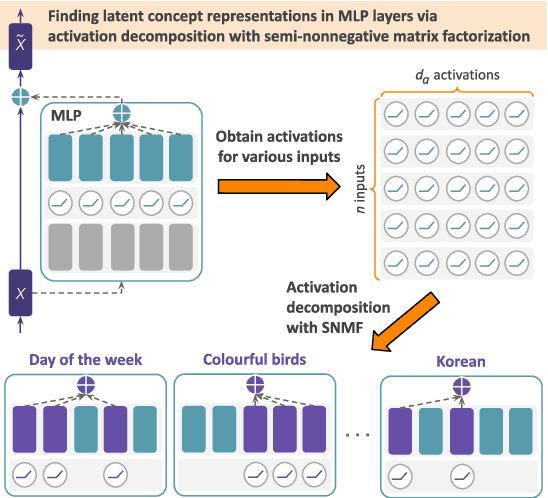



A central goal for mechanistic interpretability has been to identify the right units of analysis in large language models (LLMs) that causally explain their outputs. While early work focused on individual neurons, evidence that neurons often encode multiple concepts has motivated a shift toward analyzing directions in activation space. A key question is how to find directions that capture interpretable features in an unsupervised manner. Current methods rely on dictionary learning with sparse autoencoders (SAEs), commonly trained over residual stream activations to learn directions from scratch. However, SAEs often struggle in causal evaluations and lack intrinsic interpretability, as their learning is not explicitly tied to the computations of the model. Here, we tackle these limitations by directly decomposing MLP activations with semi-nonnegative matrix factorization (SNMF), such that the learned features are (a) sparse linear combinations of co-activated neurons, and (b) mapped to their activating inputs, making them directly interpretable. Experiments on Llama 3.1, Gemma 2 and GPT-2 show that SNMF derived features outperform SAEs and a strong supervised baseline (difference-in-means) on causal steering, while aligning with human-interpretable concepts. Further analysis reveals that specific neuron combinations are reused across semantically-related features, exposing a hierarchical structure in the MLP's activation space. Together, these results position SNMF as a simple and effective tool for identifying interpretable features and dissecting concept representations in LLMs.
How Do Transformers Learn Variable Binding in Symbolic Programs?
May 27, 2025Variable binding -- the ability to associate variables with values -- is fundamental to symbolic computation and cognition. Although classical architectures typically implement variable binding via addressable memory, it is not well understood how modern neural networks lacking built-in binding operations may acquire this capacity. We investigate this by training a Transformer to dereference queried variables in symbolic programs where variables are assigned either numerical constants or other variables. Each program requires following chains of variable assignments up to four steps deep to find the queried value, and also contains irrelevant chains of assignments acting as distractors. Our analysis reveals a developmental trajectory with three distinct phases during training: (1) random prediction of numerical constants, (2) a shallow heuristic prioritizing early variable assignments, and (3) the emergence of a systematic mechanism for dereferencing assignment chains. Using causal interventions, we find that the model learns to exploit the residual stream as an addressable memory space, with specialized attention heads routing information across token positions. This mechanism allows the model to dynamically track variable bindings across layers, resulting in accurate dereferencing. Our results show how Transformer models can learn to implement systematic variable binding without explicit architectural support, bridging connectionist and symbolic approaches.
Language Models use Lookbacks to Track Beliefs
May 20, 2025How do language models (LMs) represent characters' beliefs, especially when those beliefs may differ from reality? This question lies at the heart of understanding the Theory of Mind (ToM) capabilities of LMs. We analyze Llama-3-70B-Instruct's ability to reason about characters' beliefs using causal mediation and abstraction. We construct a dataset that consists of simple stories where two characters each separately change the state of two objects, potentially unaware of each other's actions. Our investigation uncovered a pervasive algorithmic pattern that we call a lookback mechanism, which enables the LM to recall important information when it becomes necessary. The LM binds each character-object-state triple together by co-locating reference information about them, represented as their Ordering IDs (OIs) in low rank subspaces of the state token's residual stream. When asked about a character's beliefs regarding the state of an object, the binding lookback retrieves the corresponding state OI and then an answer lookback retrieves the state token. When we introduce text specifying that one character is (not) visible to the other, we find that the LM first generates a visibility ID encoding the relation between the observing and the observed character OIs. In a visibility lookback, this ID is used to retrieve information about the observed character and update the observing character's beliefs. Our work provides insights into the LM's belief tracking mechanisms, taking a step toward reverse-engineering ToM reasoning in LMs.
MIB: A Mechanistic Interpretability Benchmark
Apr 17, 2025



How can we know whether new mechanistic interpretability methods achieve real improvements? In pursuit of meaningful and lasting evaluation standards, we propose MIB, a benchmark with two tracks spanning four tasks and five models. MIB favors methods that precisely and concisely recover relevant causal pathways or specific causal variables in neural language models. The circuit localization track compares methods that locate the model components - and connections between them - most important for performing a task (e.g., attribution patching or information flow routes). The causal variable localization track compares methods that featurize a hidden vector, e.g., sparse autoencoders (SAEs) or distributed alignment search (DAS), and locate model features for a causal variable relevant to the task. Using MIB, we find that attribution and mask optimization methods perform best on circuit localization. For causal variable localization, we find that the supervised DAS method performs best, while SAE features are not better than neurons, i.e., standard dimensions of hidden vectors. These findings illustrate that MIB enables meaningful comparisons of methods, and increases our confidence that there has been real progress in the field.
Combining Causal Models for More Accurate Abstractions of Neural Networks
Mar 14, 2025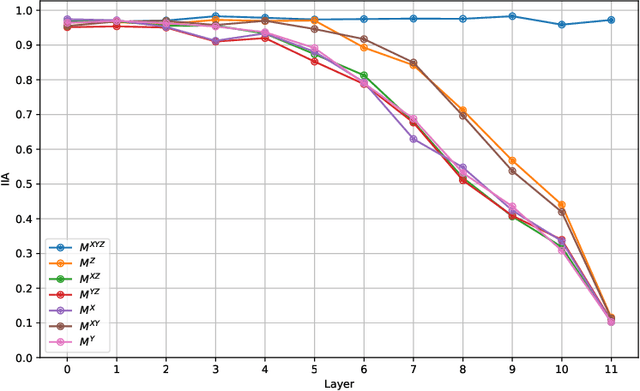
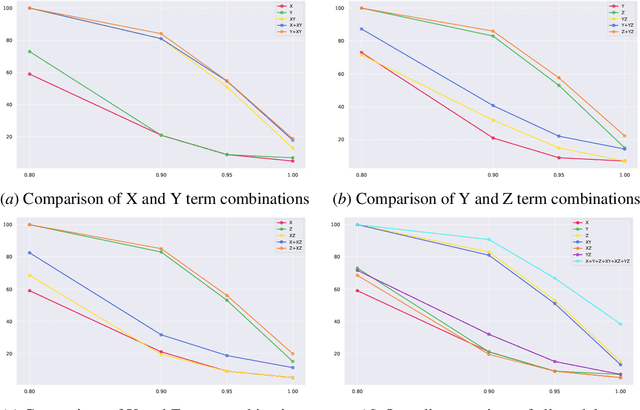
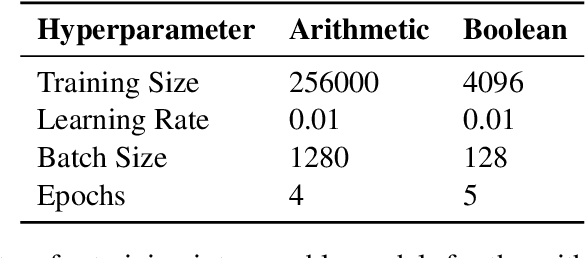
Mechanistic interpretability aims to reverse engineer neural networks by uncovering which high-level algorithms they implement. Causal abstraction provides a precise notion of when a network implements an algorithm, i.e., a causal model of the network contains low-level features that realize the high-level variables in a causal model of the algorithm. A typical problem in practical settings is that the algorithm is not an entirely faithful abstraction of the network, meaning it only partially captures the true reasoning process of a model. We propose a solution where we combine different simple high-level models to produce a more faithful representation of the network. Through learning this combination, we can model neural networks as being in different computational states depending on the input provided, which we show is more accurate to GPT 2-small fine-tuned on two toy tasks. We observe a trade-off between the strength of an interpretability hypothesis, which we define in terms of the number of inputs explained by the high-level models, and its faithfulness, which we define as the interchange intervention accuracy. Our method allows us to modulate between the two, providing the most accurate combination of models that describe the behavior of a neural network given a faithfulness level.