 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSALT: Steering Activations towards Leakage-free Thinking in Chain of Thought
Nov 11, 2025As Large Language Models (LLMs) evolve into personal assistants with access to sensitive user data, they face a critical privacy challenge: while prior work has addressed output-level privacy, recent findings reveal that LLMs often leak private information through their internal reasoning processes, violating contextual privacy expectations. These leaky thoughts occur when models inadvertently expose sensitive details in their reasoning traces, even when final outputs appear safe. The challenge lies in preventing such leakage without compromising the model's reasoning capabilities, requiring a delicate balance between privacy and utility. We introduce Steering Activations towards Leakage-free Thinking (SALT), a lightweight test-time intervention that mitigates privacy leakage in model's Chain of Thought (CoT) by injecting targeted steering vectors into hidden state. We identify the high-leakage layers responsible for this behavior. Through experiments across multiple LLMs, we demonstrate that SALT achieves reductions including $18.2\%$ reduction in CPL on QwQ-32B, $17.9\%$ reduction in CPL on Llama-3.1-8B, and $31.2\%$ reduction in CPL on Deepseek in contextual privacy leakage dataset AirGapAgent-R while maintaining comparable task performance and utility. Our work establishes SALT as a practical approach for test-time privacy protection in reasoning-capable language models, offering a path toward safer deployment of LLM-based personal agents.
Alignment-Constrained Dynamic Pruning for LLMs: Identifying and Preserving Alignment-Critical Circuits
Nov 09, 2025Large Language Models require substantial computational resources for inference, posing deployment challenges. While dynamic pruning offers superior efficiency over static methods through adaptive circuit selection, it exacerbates alignment degradation by retaining only input-dependent safety-critical circuit preservation across diverse inputs. As a result, addressing these heightened alignment vulnerabilities remains critical. We introduce Alignment-Aware Probe Pruning (AAPP), a dynamic structured pruning method that adaptively preserves alignment-relevant circuits during inference, building upon Probe Pruning. Experiments on LLaMA 2-7B, Qwen2.5-14B-Instruct, and Gemma-3-12B-IT show AAPP improves refusal rates by 50\% at matched compute, enabling efficient yet safety-preserving LLM deployment.
Optimizing Chain-of-Thought Confidence via Topological and Dirichlet Risk Analysis
Nov 09, 2025


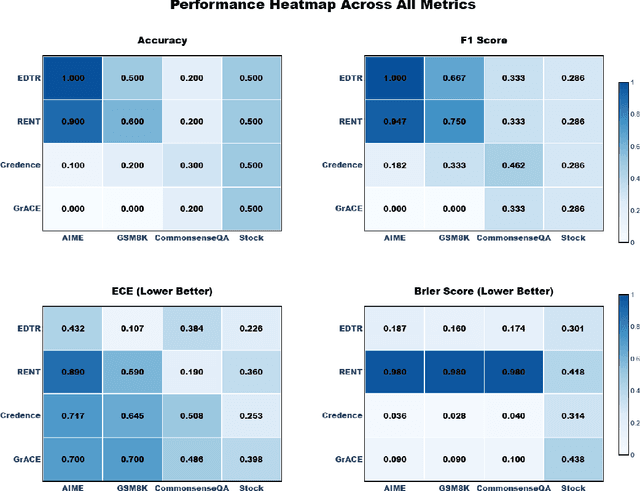
Chain-of-thought (CoT) prompting enables Large Language Models to solve complex problems, but deploying these models safely requires reliable confidence estimates, a capability where existing methods suffer from poor calibration and severe overconfidence on incorrect predictions. We propose Enhanced Dirichlet and Topology Risk (EDTR), a novel decoding strategy that combines topological analysis with Dirichlet-based uncertainty quantification to measure LLM confidence across multiple reasoning paths. EDTR treats each CoT as a vector in high-dimensional space and extracts eight topological risk features capturing the geometric structure of reasoning distributions: tighter, more coherent clusters indicate higher confidence while dispersed, inconsistent paths signal uncertainty. We evaluate EDTR against three state-of-the-art calibration methods across four diverse reasoning benchmarks spanning olympiad-level mathematics (AIME), grade school math (GSM8K), commonsense reasoning, and stock price prediction \cite{zhang2025aime, cobbe2021training, talmor-etal-2019-commonsenseqa, yahoo_finance}. EDTR achieves 41\% better calibration than competing methods with an average ECE of 0.287 and the best overall composite score of 0.672, while notably achieving perfect accuracy on AIME and exceptional calibration on GSM8K with an ECE of 0.107, domains where baselines exhibit severe overconfidence. Our work provides a geometric framework for understanding and quantifying uncertainty in multi-step LLM reasoning, enabling more reliable deployment where calibrated confidence estimates are essential.
SafetyNet: Detecting Harmful Outputs in LLMs by Modeling and Monitoring Deceptive Behaviors
May 20, 2025High-risk industries like nuclear and aviation use real-time monitoring to detect dangerous system conditions. Similarly, Large Language Models (LLMs) need monitoring safeguards. We propose a real-time framework to predict harmful AI outputs before they occur by using an unsupervised approach that treats normal behavior as the baseline and harmful outputs as outliers. Our study focuses specifically on backdoor-triggered responses -- where specific input phrases activate hidden vulnerabilities causing the model to generate unsafe content like violence, pornography, or hate speech. We address two key challenges: (1) identifying true causal indicators rather than surface correlations, and (2) preventing advanced models from deception -- deliberately evading monitoring systems. Hence, we approach this problem from an unsupervised lens by drawing parallels to human deception: just as humans exhibit physical indicators while lying, we investigate whether LLMs display distinct internal behavioral signatures when generating harmful content. Our study addresses two critical challenges: 1) designing monitoring systems that capture true causal indicators rather than superficial correlations; and 2)preventing intentional evasion by increasingly capable "Future models''. Our findings show that models can produce harmful content through causal mechanisms and can become deceptive by: (a) alternating between linear and non-linear representations, and (b) modifying feature relationships. To counter this, we developed Safety-Net -- a multi-detector framework that monitors different representation dimensions, successfully detecting harmful behavior even when information is shifted across representational spaces to evade individual monitors. Our evaluation shows 96% accuracy in detecting harmful cases using our unsupervised ensemble approach.
Modular Training of Neural Networks aids Interpretability
Feb 04, 2025



An approach to improve neural network interpretability is via clusterability, i.e., splitting a model into disjoint clusters that can be studied independently. We define a measure for clusterability and show that pre-trained models form highly enmeshed clusters via spectral graph clustering. We thus train models to be more modular using a ``clusterability loss'' function that encourages the formation of non-interacting clusters. Using automated interpretability techniques, we show that our method can help train models that are more modular and learn different, disjoint, and smaller circuits. We investigate CNNs trained on MNIST and CIFAR, small transformers trained on modular addition, and language models. Our approach provides a promising direction for training neural networks that learn simpler functions and are easier to interpret.
Evaluating Open-Source Sparse Autoencoders on Disentangling Factual Knowledge in GPT-2 Small
Sep 05, 2024


A popular new method in mechanistic interpretability is to train high-dimensional sparse autoencoders (SAEs) on neuron activations and use SAE features as the atomic units of analysis. However, the body of evidence on whether SAE feature spaces are useful for causal analysis is underdeveloped. In this work, we use the RAVEL benchmark to evaluate whether SAEs trained on hidden representations of GPT-2 small have sets of features that separately mediate knowledge of which country a city is in and which continent it is in. We evaluate four open-source SAEs for GPT-2 small against each other, with neurons serving as a baseline, and linear features learned via distributed alignment search (DAS) serving as a skyline. For each, we learn a binary mask to select features that will be patched to change the country of a city without changing the continent, or vice versa. Our results show that SAEs struggle to reach the neuron baseline, and none come close to the DAS skyline. We release code here: https://github.com/MaheepChaudhary/SAE-Ravel
Towards Trustworthy and Aligned Machine Learning: A Data-centric Survey with Causality Perspectives
Jul 31, 2023The trustworthiness of machine learning has emerged as a critical topic in the field, encompassing various applications and research areas such as robustness, security, interpretability, and fairness. The last decade saw the development of numerous methods addressing these challenges. In this survey, we systematically review these advancements from a data-centric perspective, highlighting the shortcomings of traditional empirical risk minimization (ERM) training in handling challenges posed by the data. Interestingly, we observe a convergence of these methods, despite being developed independently across trustworthy machine learning subfields. Pearl's hierarchy of causality offers a unifying framework for these techniques. Accordingly, this survey presents the background of trustworthy machine learning development using a unified set of concepts, connects this language to Pearl's causal hierarchy, and finally discusses methods explicitly inspired by causality literature. We provide a unified language with mathematical vocabulary to link these methods across robustness, adversarial robustness, interpretability, and fairness, fostering a more cohesive understanding of the field. Further, we explore the trustworthiness of large pretrained models. After summarizing dominant techniques like fine-tuning, parameter-efficient fine-tuning, prompting, and reinforcement learning with human feedback, we draw connections between them and the standard ERM. This connection allows us to build upon the principled understanding of trustworthy methods, extending it to these new techniques in large pretrained models, paving the way for future methods. Existing methods under this perspective are also reviewed. Lastly, we offer a brief summary of the applications of these methods and discuss potential future aspects related to our survey. For more information, please visit http://trustai.one.
An Intelligent Recommendation-cum-Reminder System
Aug 09, 2021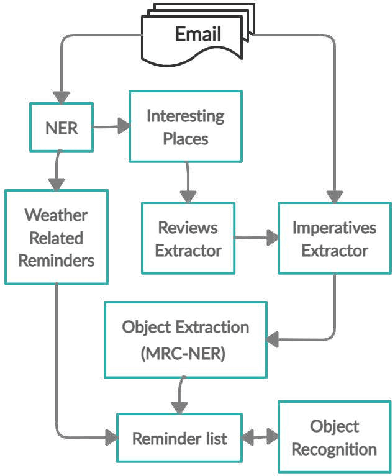

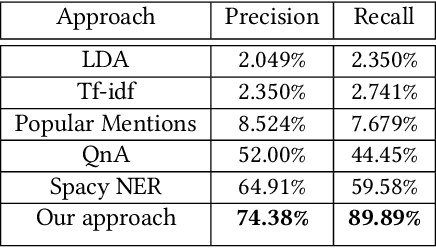
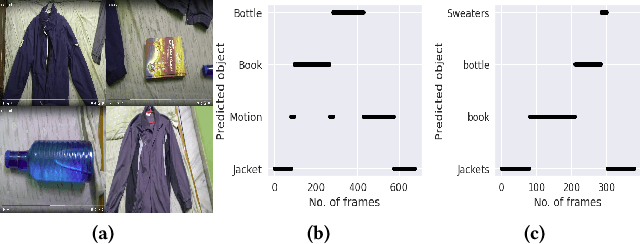
Intelligent recommendation and reminder systems are the need of the fast-pacing life. Current intelligent systems such as Siri, Google Assistant, Microsoft Cortona, etc., have limited capability. For example, if you want to wake up at 6 am because you have an upcoming trip, you have to set the alarm manually. Besides, these systems do not recommend or remind what else to carry, such as carrying an umbrella during a likely rain. The present work proposes a system that takes an email as input and returns a recommendation-cumreminder list. As a first step, we parse the emails, recognize the entities using named entity recognition (NER). In the second step, information retrieval over the web is done to identify nearby places, climatic conditions, etc. Imperative sentences from the reviews of all places are extracted and passed to the object extraction module. The main challenge lies in extracting the objects (items) of interest from the review. To solve it, a modified Machine Reading Comprehension-NER (MRC-NER) model is trained to tag objects of interest by formulating annotation rules as a query. The objects so found are recommended to the user one day in advance. The final reminder list of objects is pruned by our proposed model for tracking objects kept during the "packing activity." Eventually, when the user leaves for the event/trip, an alert is sent containing the reminding list items. Our approach achieves superior performance compared to several baselines by as much as 30% on recall and 10% on precision.