 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Speech-to-Speech Neural Machine Translation: A Survey
Nov 13, 2024



Speech-to-Speech Translation (S2ST) models transform speech from one language to another target language with the same linguistic information. S2ST is important for bridging the communication gap among communities and has diverse applications. In recent years, researchers have introduced direct S2ST models, which have the potential to translate speech without relying on intermediate text generation, have better decoding latency, and the ability to preserve paralinguistic and non-linguistic features. However, direct S2ST has yet to achieve quality performance for seamless communication and still lags behind the cascade models in terms of performance, especially in real-world translation. To the best of our knowledge, no comprehensive survey is available on the direct S2ST system, which beginners and advanced researchers can look upon for a quick survey. The present work provides a comprehensive review of direct S2ST models, data and application issues, and performance metrics. We critically analyze the models' performance over the benchmark datasets and provide research challenges and future directions.
End-to-End Speech-to-Text Translation: A Survey
Dec 02, 2023



Speech-to-text translation pertains to the task of converting speech signals in a language to text in another language. It finds its application in various domains, such as hands-free communication, dictation, video lecture transcription, and translation, to name a few. Automatic Speech Recognition (ASR), as well as Machine Translation(MT) models, play crucial roles in traditional ST translation, enabling the conversion of spoken language in its original form to written text and facilitating seamless cross-lingual communication. ASR recognizes spoken words, while MT translates the transcribed text into the target language. Such disintegrated models suffer from cascaded error propagation and high resource and training costs. As a result, researchers have been exploring end-to-end (E2E) models for ST translation. However, to our knowledge, there is no comprehensive review of existing works on E2E ST. The present survey, therefore, discusses the work in this direction. Our attempt has been to provide a comprehensive review of models employed, metrics, and datasets used for ST tasks, providing challenges and future research direction with new insights. We believe this review will be helpful to researchers working on various applications of ST models.
Deep Learning Architecture for Automatic Essay Scoring
Jun 16, 2022

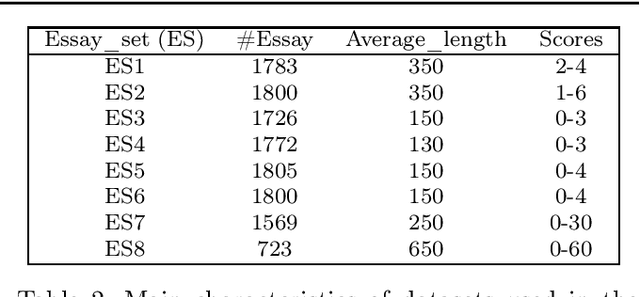
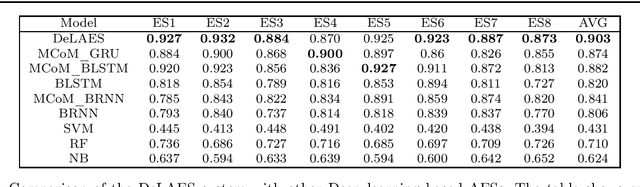
Automatic evaluation of essay (AES) and also called automatic essay scoring has become a severe problem due to the rise of online learning and evaluation platforms such as Coursera, Udemy, Khan academy, and so on. Researchers have recently proposed many techniques for automatic evaluation. However, many of these techniques use hand-crafted features and thus are limited from the feature representation point of view. Deep learning has emerged as a new paradigm in machine learning which can exploit the vast data and identify the features useful for essay evaluation. To this end, we propose a novel architecture based on recurrent networks (RNN) and convolution neural network (CNN). In the proposed architecture, the multichannel convolutional layer learns and captures the contextual features of the word n-gram from the word embedding vectors and the essential semantic concepts to form the feature vector at essay level using max-pooling operation. A variant of RNN called Bi-gated recurrent unit (BGRU) is used to access both previous and subsequent contextual representations. The experiment was carried out on eight data sets available on Kaggle for the task of AES. The experimental results show that our proposed system achieves significantly higher grading accuracy than other deep learning-based AES systems and also other state-of-the-art AES systems.
Anomaly Detection in Big Data
Mar 03, 2022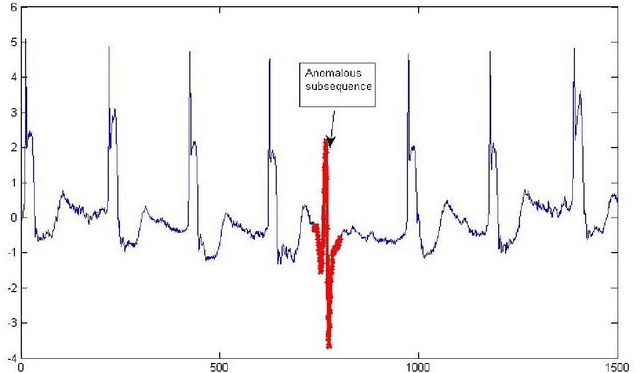

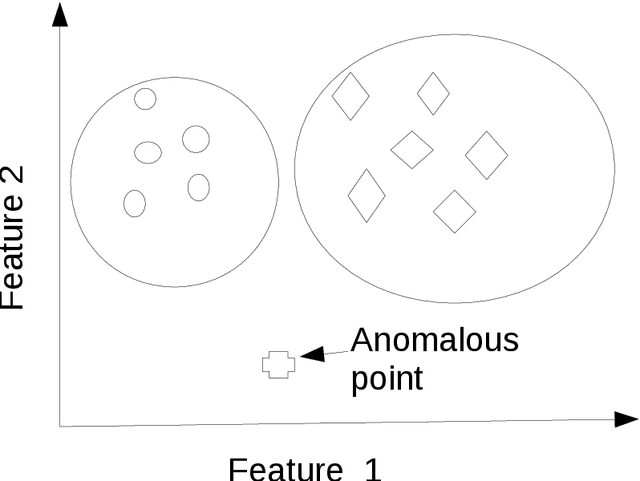
Anomaly is defined as a state of the system that do not conform to the normal behavior. For example, the emission of neutrons in a nuclear reactor channel above the specified threshold is an anomaly. Big data refers to the data set that is \emph{high volume, streaming, heterogeneous, distributed} and often \emph{sparse}. Big data is not uncommon these days. For example, as per Internet live stats, the number of tweets posted per day has gone above 500 millions. Due to data explosion in data laden domains, traditional anomaly detection techniques developed for small data sets scale poorly on large-scale data sets. Therefore, we take an alternative approach to tackle anomaly detection in big data. Essentially, there are two ways to scale anomaly detection in big data. The first is based on the \emph{online} learning and the second is based on the \emph{distributed} learning. Our aim in the thesis is to tackle big data problems while detecting anomaly efficiently. To that end, we first take \emph{streaming} issue of the big data and propose Passive-Aggressive GMEAN (PAGMEAN) algorithms. Although, online learning algorithm can scale well over large number of data points and dimensions, they can not process data when it is distributed at multiple locations; which is quite common these days. Therefore, we propose anomaly detection algorithm which is inherently distributed using ADMM. Finally, we present a case study on anomaly detection in nuclear power plant data.
How Effective is Incongruity? Implications for Code-mix Sarcasm Detection
Feb 06, 2022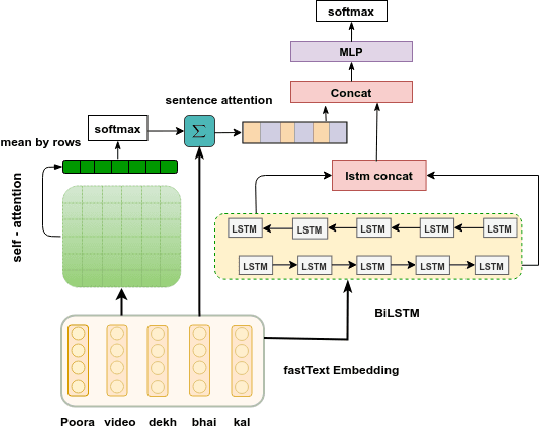
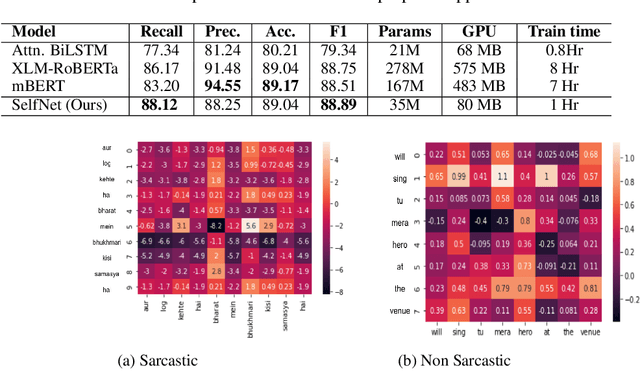
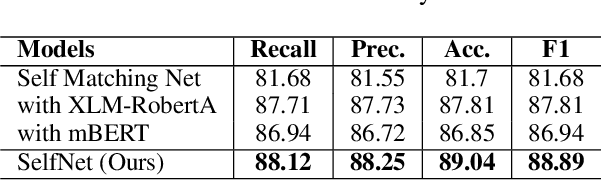
The presence of sarcasm in conversational systems and social media like chatbots, Facebook, Twitter, etc. poses several challenges for downstream NLP tasks. This is attributed to the fact that the intended meaning of a sarcastic text is contrary to what is expressed. Further, the use of code-mix language to express sarcasm is increasing day by day. Current NLP techniques for code-mix data have limited success due to the use of different lexicon, syntax, and scarcity of labeled corpora. To solve the joint problem of code-mixing and sarcasm detection, we propose the idea of capturing incongruity through sub-word level embeddings learned via fastText. Empirical results shows that our proposed model achieves F1-score on code-mix Hinglish dataset comparable to pretrained multilingual models while training 10x faster and using a lower memory footprint
An Intelligent Recommendation-cum-Reminder System
Aug 09, 2021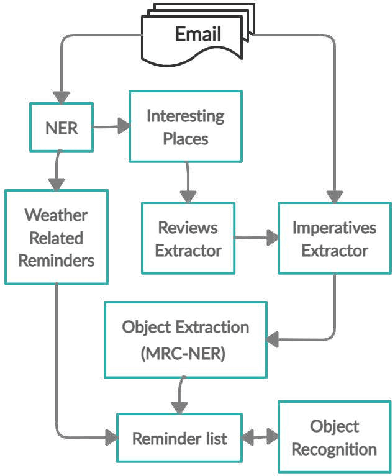

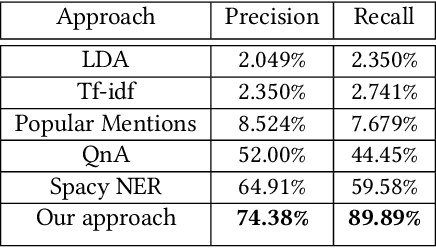
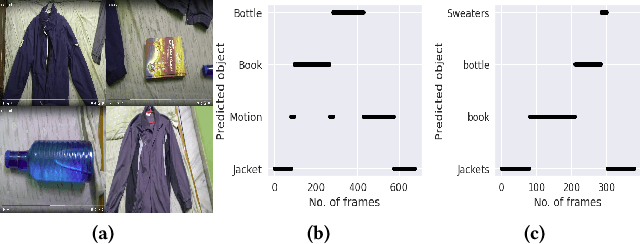
Intelligent recommendation and reminder systems are the need of the fast-pacing life. Current intelligent systems such as Siri, Google Assistant, Microsoft Cortona, etc., have limited capability. For example, if you want to wake up at 6 am because you have an upcoming trip, you have to set the alarm manually. Besides, these systems do not recommend or remind what else to carry, such as carrying an umbrella during a likely rain. The present work proposes a system that takes an email as input and returns a recommendation-cumreminder list. As a first step, we parse the emails, recognize the entities using named entity recognition (NER). In the second step, information retrieval over the web is done to identify nearby places, climatic conditions, etc. Imperative sentences from the reviews of all places are extracted and passed to the object extraction module. The main challenge lies in extracting the objects (items) of interest from the review. To solve it, a modified Machine Reading Comprehension-NER (MRC-NER) model is trained to tag objects of interest by formulating annotation rules as a query. The objects so found are recommended to the user one day in advance. The final reminder list of objects is pruned by our proposed model for tracking objects kept during the "packing activity." Eventually, when the user leaves for the event/trip, an alert is sent containing the reminding list items. Our approach achieves superior performance compared to several baselines by as much as 30% on recall and 10% on precision.
Online Similarity Learning with Feedback for Invoice Line Item Matching
Feb 14, 2020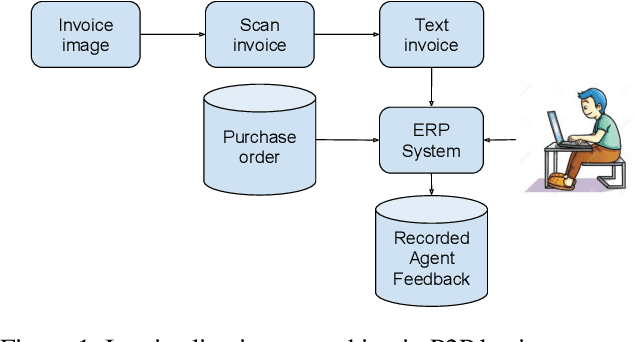

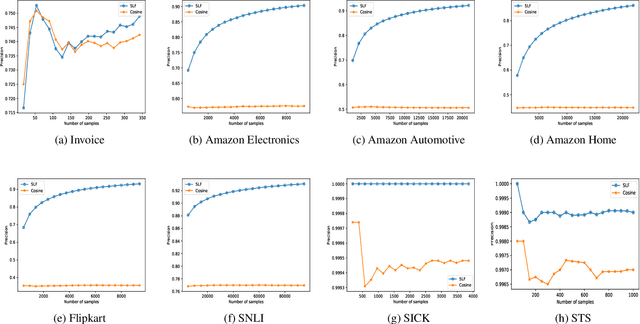
The procure to pay process (P2P) in large enterprises is a back-end business process which deals with the procurement of products and services for enterprise operations. Procurement is done by issuing purchase orders to impaneled vendors and invoices submitted by vendors are paid after they go through a rigorous validation process. Agents orchestrating P2P process often encounter the problem of matching a product or service descriptions in the invoice to those in purchase order and verify if the ordered items are what have been supplied or serviced. For example, the description in the invoice and purchase order could be TRES 739mL CD KER Smooth and TRES 0.739L CD KER Smth which look different at word level but refer to the same item. In a typical P2P process, agents are asked to manually select the products which are similar before invoices are posted for payment. This step in the business process is manual, repetitive, cumbersome, and costly. Since descriptions are not well-formed sentences, we cannot apply existing semantic and syntactic text similarity approaches directly. In this paper, we present two approaches to solve the above problem using various types of available agent's recorded feedback data. If the agent's feedback is in the form of a relative ranking between descriptions, we use similarity ranking algorithm. If the agent's feedback is absolute such as match or no-match, we use classification similarity algorithm. We also present the threats to the validity of our approach and present a possible remedy making use of product taxonomy and catalog. We showcase the comparative effectiveness and efficiency of the proposed approaches over many benchmarks and real-world data sets.
Online Anomaly Detection via Class-Imbalance Learning
Aug 27, 2015
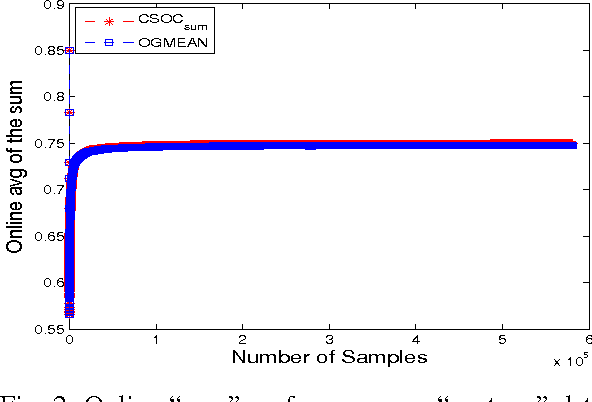


Anomaly detection is an important task in many real world applications such as fraud detection, suspicious activity detection, health care monitoring etc. In this paper, we tackle this problem from supervised learning perspective in online learning setting. We maximize well known \emph{Gmean} metric for class-imbalance learning in online learning framework. Specifically, we show that maximizing \emph{Gmean} is equivalent to minimizing a convex surrogate loss function and based on that we propose novel online learning algorithm for anomaly detection. We then show, by extensive experiments, that the performance of the proposed algorithm with respect to $sum$ metric is as good as a recently proposed Cost-Sensitive Online Classification(CSOC) algorithm for class-imbalance learning over various benchmarked data sets while keeping running time close to the perception algorithm. Our another conclusion is that other competitive online algorithms do not perform consistently over data sets of varying size. This shows the potential applicability of our proposed approach.