 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Granger-Causal Perspective on Gradient Descent with Application to Pruning
Dec 04, 2024



Stochastic Gradient Descent (SGD) is the main approach to optimizing neural networks. Several generalization properties of deep networks, such as convergence to a flatter minima, are believed to arise from SGD. This article explores the causality aspect of gradient descent. Specifically, we show that the gradient descent procedure has an implicit granger-causal relationship between the reduction in loss and a change in parameters. By suitable modifications, we make this causal relationship explicit. A causal approach to gradient descent has many significant applications which allow greater control. In this article, we illustrate the significance of the causal approach using the application of Pruning. The causal approach to pruning has several interesting properties - (i) We observe a phase shift as the percentage of pruned parameters increase. Such phase shift is indicative of an optimal pruning strategy. (ii) After pruning, we see that minima becomes "flatter", explaining the increase in accuracy after pruning weights.
Enhanced Breast Cancer Tumor Classification using MobileNetV2: A Detailed Exploration on Image Intensity, Error Mitigation, and Streamlit-driven Real-time Deployment
Dec 05, 2023



This research introduces a sophisticated transfer learning model based on Google's MobileNetV2 for breast cancer tumor classification into normal, benign, and malignant categories, utilizing a dataset of 1576 ultrasound images (265 normal, 891 benign, 420 malignant). The model achieves an accuracy of 0.82, precision of 0.83, recall of 0.81, ROC-AUC of 0.94, PR-AUC of 0.88, and MCC of 0.74. It examines image intensity distributions and misclassification errors, offering improvements for future applications. Addressing dataset imbalances, the study ensures a generalizable model. This work, using a dataset from Baheya Hospital, Cairo, Egypt, compiled by Walid Al-Dhabyani et al., emphasizes MobileNetV2's potential in medical imaging, aiming to improve diagnostic precision in oncology. Additionally, the paper explores Streamlit-based deployment for real-time tumor classification, demonstrating MobileNetV2's applicability in medical imaging and setting a benchmark for future research in oncology diagnostics.
Retrieval-based Text Selection for Addressing Class-Imbalanced Data in Classification
Jul 27, 2023



This paper addresses the problem of selecting of a set of texts for annotation in text classification using retrieval methods when there are limits on the number of annotations due to constraints on human resources. An additional challenge addressed is dealing with binary categories that have a small number of positive instances, reflecting severe class imbalance. In our situation, where annotation occurs over a long time period, the selection of texts to be annotated can be made in batches, with previous annotations guiding the choice of the next set. To address these challenges, the paper proposes leveraging SHAP to construct a quality set of queries for Elasticsearch and semantic search, to try to identify optimal sets of texts for annotation that will help with class imbalance. The approach is tested on sets of cue texts describing possible future events, constructed by participants involved in studies aimed to help with the management of obesity and diabetes. We introduce an effective method for selecting a small set of texts for annotation and building high-quality classifiers. We integrate vector search, semantic search, and machine learning classifiers to yield a good solution. Our experiments demonstrate improved F1 scores for the minority classes in binary classification.
End-to-End Multimodal Fact-Checking and Explanation Generation: A Challenging Dataset and Models
May 25, 2022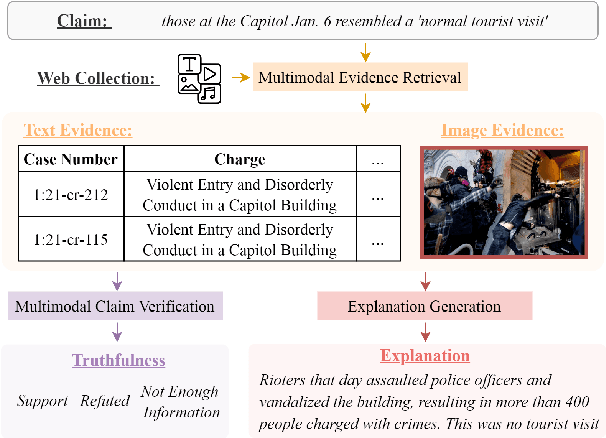
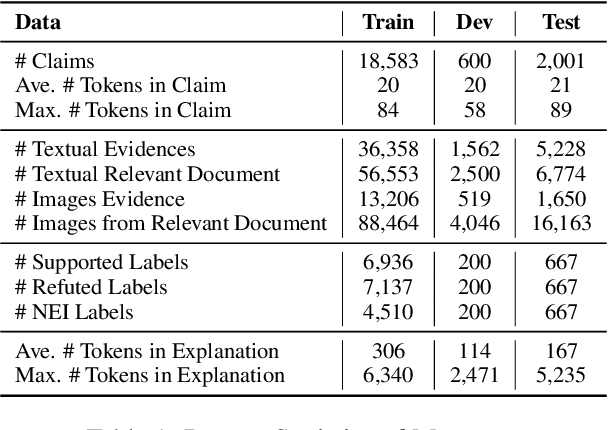
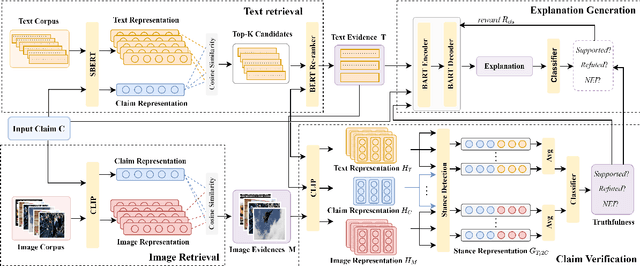
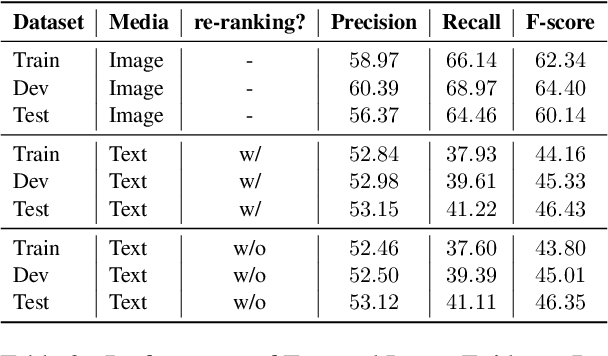
We propose the end-to-end multimodal fact-checking and explanation generation, where the input is a claim and a large collection of web sources, including articles, images, videos, and tweets, and the goal is to assess the truthfulness of the claim by retrieving relevant evidence and predicting a truthfulness label (i.e., support, refute and not enough information), and generate a rationalization statement to explain the reasoning and ruling process. To support this research, we construct Mocheg, a large-scale dataset that consists of 21,184 claims where each claim is assigned with a truthfulness label and ruling statement, with 58,523 evidence in the form of text and images. To establish baseline performances on Mocheg, we experiment with several state-of-the-art neural architectures on the three pipelined subtasks: multimodal evidence retrieval, claim verification, and explanation generation, and demonstrate the current state-of-the-art performance of end-to-end multimodal fact-checking is still far from satisfying. To the best of our knowledge, we are the first to build the benchmark dataset and solutions for end-to-end multimodal fact-checking and justification.
How Effective is Incongruity? Implications for Code-mix Sarcasm Detection
Feb 06, 2022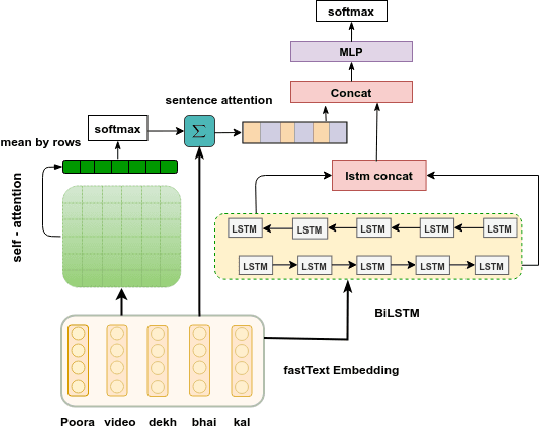
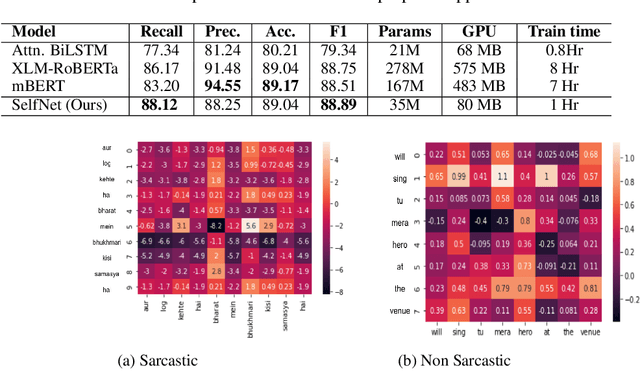
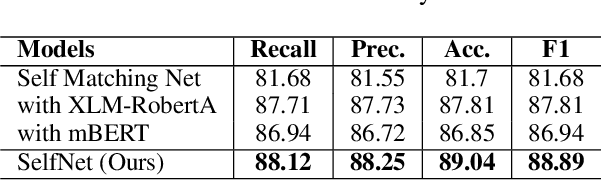
The presence of sarcasm in conversational systems and social media like chatbots, Facebook, Twitter, etc. poses several challenges for downstream NLP tasks. This is attributed to the fact that the intended meaning of a sarcastic text is contrary to what is expressed. Further, the use of code-mix language to express sarcasm is increasing day by day. Current NLP techniques for code-mix data have limited success due to the use of different lexicon, syntax, and scarcity of labeled corpora. To solve the joint problem of code-mixing and sarcasm detection, we propose the idea of capturing incongruity through sub-word level embeddings learned via fastText. Empirical results shows that our proposed model achieves F1-score on code-mix Hinglish dataset comparable to pretrained multilingual models while training 10x faster and using a lower memory footprint
Vector Quantized Spectral Clustering applied to Soybean Whole Genome Sequences
Sep 30, 2018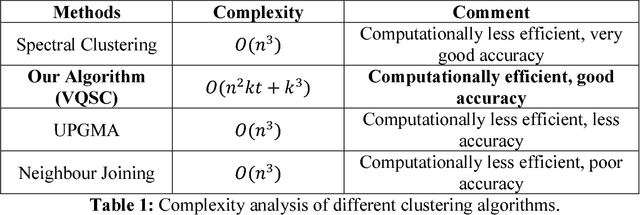

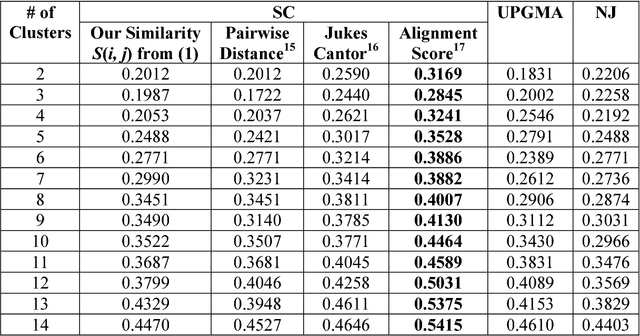

We develop a Vector Quantized Spectral Clustering (VQSC) algorithm that is a combination of Spectral Clustering (SC) and Vector Quantization (VQ) sampling for grouping Soybean genomes. The inspiration here is to use SC for its accuracy and VQ to make the algorithm computationally cheap (the complexity of SC is cubic in-terms of the input size). Although the combination of SC and VQ is not new, the novelty of our work is in developing the crucial similarity matrix in SC as well as use of k-medoids in VQ, both adapted for the Soybean genome data. We compare our approach with commonly used techniques like UPGMA (Un-weighted Pair Graph Method with Arithmetic Mean) and NJ (Neighbour Joining). Experimental results show that our approach outperforms both these techniques significantly in terms of cluster quality (up to 25% better cluster quality) and time complexity (order of magnitude faster).