 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStagePilot: A Deep Reinforcement Learning Agent for Stage-Controlled Cybergrooming Simulation
Feb 04, 2026Cybergrooming is an evolving threat to youth, necessitating proactive educational interventions. We propose StagePilot, an offline RL-based dialogue agent that simulates the stage-wise progression of grooming behaviors for prevention training. StagePilot selects conversational stages using a composite reward that balances user sentiment and goal proximity, with transitions constrained to adjacent stages for realism and interpretability. We evaluate StagePilot through LLM-based simulations, measuring stage completion, dialogue efficiency, and emotional engagement. Results show that StagePilot generates realistic and coherent conversations aligned with grooming dynamics. Among tested methods, the IQL+AWAC agent achieves the best balance between strategic planning and emotional coherence, reaching the final stage up to 43% more frequently than baselines while maintaining over 70% sentiment alignment.
Adversarial Reward Auditing for Active Detection and Mitigation of Reward Hacking
Feb 02, 2026Reinforcement Learning from Human Feedback (RLHF) remains vulnerable to reward hacking, where models exploit spurious correlations in learned reward models to achieve high scores while violating human intent. Existing mitigations rely on static defenses that cannot adapt to novel exploitation strategies. We propose Adversarial Reward Auditing (ARA), a framework that reconceptualizes reward hacking as a dynamic, competitive game. ARA operates in two stages: first, a Hacker policy discovers reward model vulnerabilities while an Auditor learns to detect exploitation from latent representations; second, Auditor-Guided RLHF (AG-RLHF) gates reward signals to penalize detected hacking, transforming reward hacking from an unobservable failure into a measurable, controllable signal. Experiments across three hacking scenarios demonstrate that ARA achieves the best alignment-utility tradeoff among all baselines: reducing sycophancy to near-SFT levels while improving helpfulness, decreasing verbosity while achieving the highest ROUGE-L, and suppressing code gaming while improving Pass@1. Beyond single-domain evaluation, we show that reward hacking, detection, and mitigation all generalize across domains -- a Hacker trained on code gaming exhibits increased sycophancy despite no reward for this behavior, and an Auditor trained on one domain effectively suppresses exploitation in others, enabling efficient multi-domain defense with a single model.
TokenSeek: Memory Efficient Fine Tuning via Instance-Aware Token Ditching
Jan 27, 2026Fine tuning has been regarded as a de facto approach for adapting large language models (LLMs) to downstream tasks, but the high training memory consumption inherited from LLMs makes this process inefficient. Among existing memory efficient approaches, activation-related optimization has proven particularly effective, as activations consistently dominate overall memory consumption. Although prior arts offer various activation optimization strategies, their data-agnostic nature ultimately results in ineffective and unstable fine tuning. In this paper, we propose TokenSeek, a universal plugin solution for various transformer-based models through instance-aware token seeking and ditching, achieving significant fine-tuning memory savings (e.g., requiring only 14.8% of the memory on Llama3.2 1B) with on-par or even better performance. Furthermore, our interpretable token seeking process reveals the underlying reasons for its effectiveness, offering valuable insights for future research on token efficiency. Homepage: https://runjia.tech/iclr_tokenseek/
From Passive Metric to Active Signal: The Evolving Role of Uncertainty Quantification in Large Language Models
Jan 22, 2026While Large Language Models (LLMs) show remarkable capabilities, their unreliability remains a critical barrier to deployment in high-stakes domains. This survey charts a functional evolution in addressing this challenge: the evolution of uncertainty from a passive diagnostic metric to an active control signal guiding real-time model behavior. We demonstrate how uncertainty is leveraged as an active control signal across three frontiers: in \textbf{advanced reasoning} to optimize computation and trigger self-correction; in \textbf{autonomous agents} to govern metacognitive decisions about tool use and information seeking; and in \textbf{reinforcement learning} to mitigate reward hacking and enable self-improvement via intrinsic rewards. By grounding these advancements in emerging theoretical frameworks like Bayesian methods and Conformal Prediction, we provide a unified perspective on this transformative trend. This survey provides a comprehensive overview, critical analysis, and practical design patterns, arguing that mastering the new trend of uncertainty is essential for building the next generation of scalable, reliable, and trustworthy AI.
Zero-shot adaptable task planning for autonomous construction robots: a comparative study of lightweight single and multi-AI agent systems
Jan 20, 2026Robots are expected to play a major role in the future construction industry but face challenges due to high costs and difficulty adapting to dynamic tasks. This study explores the potential of foundation models to enhance the adaptability and generalizability of task planning in construction robots. Four models are proposed and implemented using lightweight, open-source large language models (LLMs) and vision language models (VLMs). These models include one single agent and three multi-agent teams that collaborate to create robot action plans. The models are evaluated across three construction roles: Painter, Safety Inspector, and Floor Tiling. Results show that the four-agent team outperforms the state-of-the-art GPT-4o in most metrics while being ten times more cost-effective. Additionally, teams with three and four agents demonstrate the improved generalizability. By discussing how agent behaviors influence outputs, this study enhances the understanding of AI teams and supports future research in diverse unstructured environments beyond construction.
Navigating Ideation Space: Decomposed Conceptual Representations for Positioning Scientific Ideas
Jan 13, 2026Scientific discovery is a cumulative process and requires new ideas to be situated within an ever-expanding landscape of existing knowledge. An emerging and critical challenge is how to identify conceptually relevant prior work from rapidly growing literature, and assess how a new idea differentiates from existing research. Current embedding approaches typically conflate distinct conceptual aspects into single representations and cannot support fine-grained literature retrieval; meanwhile, LLM-based evaluators are subject to sycophancy biases, failing to provide discriminative novelty assessment. To tackle these challenges, we introduce the Ideation Space, a structured representation that decomposes scientific knowledge into three distinct dimensions, i.e., research problem, methodology, and core findings, each learned through contrastive training. This framework enables principled measurement of conceptual distance between ideas, and modeling of ideation transitions that capture the logical connections within a proposed idea. Building upon this representation, we propose a Hierarchical Sub-Space Retrieval framework for efficient, targeted literature retrieval, and a Decomposed Novelty Assessment algorithm that identifies which aspects of an idea are novel. Extensive experiments demonstrate substantial improvements, where our approach achieves Recall@30 of 0.329 (16.7% over baselines), our ideation transition retrieval reaches Hit Rate@30 of 0.643, and novelty assessment attains 0.37 correlation with expert judgments. In summary, our work provides a promising paradigm for future research on accelerating and evaluating scientific discovery.
MiLDEdit: Reasoning-Based Multi-Layer Design Document Editing
Jan 08, 2026Real-world design documents (e.g., posters) are inherently multi-layered, combining decoration, text, and images. Editing them from natural-language instructions requires fine-grained, layer-aware reasoning to identify relevant layers and coordinate modifications. Prior work largely overlooks multi-layer design document editing, focusing instead on single-layer image editing or multi-layer generation, which assume a flat canvas and lack the reasoning needed to determine what and where to modify. To address this gap, we introduce the Multi-Layer Document Editing Agent (MiLDEAgent), a reasoning-based framework that combines an RL-trained multimodal reasoner for layer-wise understanding with an image editor for targeted modifications. To systematically benchmark this setting, we introduce the MiLDEBench, a human-in-the-loop corpus of over 20K design documents paired with diverse editing instructions. The benchmark is complemented by a task-specific evaluation protocol, MiLDEEval, which spans four dimensions including instruction following, layout consistency, aesthetics, and text rendering. Extensive experiments on 14 open-source and 2 closed-source models reveal that existing approaches fail to generalize: open-source models often cannot complete multi-layer document editing tasks, while closed-source models suffer from format violations. In contrast, MiLDEAgent achieves strong layer-aware reasoning and precise editing, significantly outperforming all open-source baselines and attaining performance comparable to closed-source models, thereby establishing the first strong baseline for multi-layer document editing.
How Do Large Language Models Learn Concepts During Continual Pre-Training?
Jan 07, 2026Human beings primarily understand the world through concepts (e.g., dog), abstract mental representations that structure perception, reasoning, and learning. However, how large language models (LLMs) acquire, retain, and forget such concepts during continual pretraining remains poorly understood. In this work, we study how individual concepts are acquired and forgotten, as well as how multiple concepts interact through interference and synergy. We link these behavioral dynamics to LLMs' internal Concept Circuits, computational subgraphs associated with specific concepts, and incorporate Graph Metrics to characterize circuit structure. Our analysis reveals: (1) LLMs concept circuits provide a non-trivial, statistically significant signal of concept learning and forgetting; (2) Concept circuits exhibit a stage-wise temporal pattern during continual pretraining, with an early increase followed by gradual decrease and stabilization; (3) concepts with larger learning gains tend to exhibit greater forgetting under subsequent training; (4) semantically similar concepts induce stronger interference than weakly related ones; (5) conceptual knowledge differs in their transferability, with some significantly facilitating the learning of others. Together, our findings offer a circuit-level view of concept learning dynamics and inform the design of more interpretable and robust concept-aware training strategies for LLMs.
SuperFlow: Training Flow Matching Models with RL on the Fly
Dec 17, 2025Recent progress in flow-based generative models and reinforcement learning (RL) has improved text-image alignment and visual quality. However, current RL training for flow models still has two main problems: (i) GRPO-style fixed per-prompt group sizes ignore variation in sampling importance across prompts, which leads to inefficient sampling and slower training; and (ii) trajectory-level advantages are reused as per-step estimates, which biases credit assignment along the flow. We propose SuperFlow, an RL training framework for flow-based models that adjusts group sizes with variance-aware sampling and computes step-level advantages in a way that is consistent with continuous-time flow dynamics. Empirically, SuperFlow reaches promising performance while using only 5.4% to 56.3% of the original training steps and reduces training time by 5.2% to 16.7% without any architectural changes. On standard text-to-image (T2I) tasks, including text rendering, compositional image generation, and human preference alignment, SuperFlow improves over SD3.5-M by 4.6% to 47.2%, and over Flow-GRPO by 1.7% to 16.0%.
Data Value in the Age of Scaling: Understanding LLM Scaling Dynamics Under Real-Synthetic Data Mixtures
Nov 17, 2025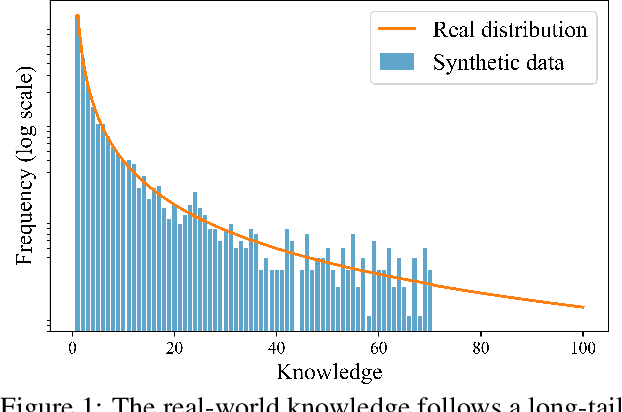
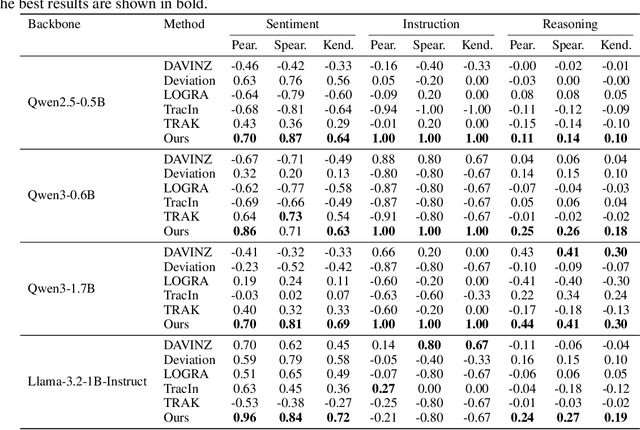
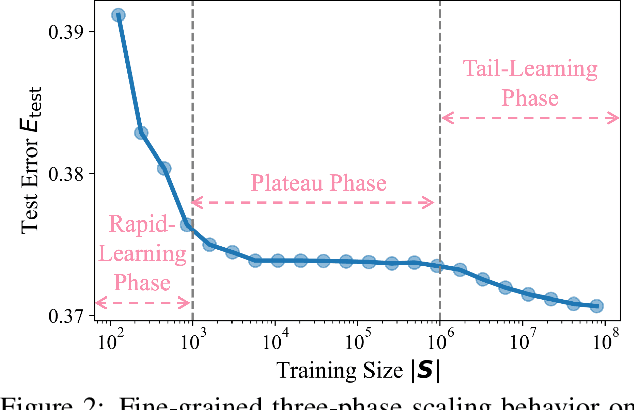
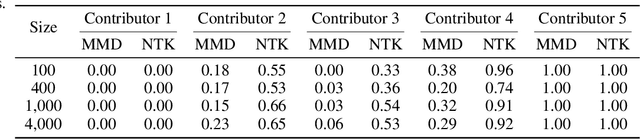
The rapid progress of large language models (LLMs) is fueled by the growing reliance on datasets that blend real and synthetic data. While synthetic data offers scalability and cost-efficiency, it often introduces systematic distributional discrepancies, particularly underrepresenting long-tail knowledge due to truncation effects from data generation mechanisms like top-p sampling, temperature scaling, and finite sampling. These discrepancies pose fundamental challenges in characterizing and evaluating the utility of mixed real-synthetic datasets. In this paper, we identify a three-phase scaling behavior characterized by two breakpoints that reflect transitions in model behavior across learning head and tail knowledge. We further derive an LLM generalization bound designed for real and synthetic mixtures, revealing several key factors that govern their generalization performance. Building on our theoretical findings, we propose an effective yet efficient data valuation method that scales to large-scale datasets. Comprehensive experiments across four tasks, including image classification, sentiment classification, instruction following, and complex reasoning, demonstrate that our method surpasses state-of-the-art baselines in data valuation with significantly low computational cost.