 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVEXA: Evidence-Grounded and Persona-Adaptive Explanations for Scam Risk Sensemaking
Feb 04, 2026Online scams across email, short message services, and social media increasingly challenge everyday risk assessment, particularly as generative AI enables more fluent and context-aware deception. Although transformer-based detectors achieve strong predictive performance, their explanations are often opaque to non-experts or misaligned with model decisions. We propose VEXA, an evidence-grounded and persona-adaptive framework for generating learner-facing scam explanations by integrating GradientSHAP-based attribution with theory-informed vulnerability personas. Evaluation across multi-channel datasets shows that grounding explanations in detector-derived evidence improves semantic reliability without increasing linguistic complexity, while persona conditioning introduces interpretable stylistic variation without disrupting evidential alignment. These results reveal a key design insight: evidential grounding governs semantic correctness, whereas persona-based adaptation operates at the level of presentation under constraints of faithfulness. Together, VEXA demonstrates the feasibility of persona-adaptive, evidence-grounded explanations and provides design guidance for trustworthy, learner-facing security explanations in non-formal contexts.
StagePilot: A Deep Reinforcement Learning Agent for Stage-Controlled Cybergrooming Simulation
Feb 04, 2026Cybergrooming is an evolving threat to youth, necessitating proactive educational interventions. We propose StagePilot, an offline RL-based dialogue agent that simulates the stage-wise progression of grooming behaviors for prevention training. StagePilot selects conversational stages using a composite reward that balances user sentiment and goal proximity, with transitions constrained to adjacent stages for realism and interpretability. We evaluate StagePilot through LLM-based simulations, measuring stage completion, dialogue efficiency, and emotional engagement. Results show that StagePilot generates realistic and coherent conversations aligned with grooming dynamics. Among tested methods, the IQL+AWAC agent achieves the best balance between strategic planning and emotional coherence, reaching the final stage up to 43% more frequently than baselines while maintaining over 70% sentiment alignment.
Risk-Aware Human-in-the-Loop Framework with Adaptive Intrusion Response for Autonomous Vehicles
Jan 16, 2026Autonomous vehicles must remain safe and effective when encountering rare long-tailed scenarios or cyber-physical intrusions during driving. We present RAIL, a risk-aware human-in-the-loop framework that turns heterogeneous runtime signals into calibrated control adaptations and focused learning. RAIL fuses three cues (curvature actuation integrity, time-to-collision proximity, and observation-shift consistency) into an Intrusion Risk Score (IRS) via a weighted Noisy-OR. When IRS exceeds a threshold, actions are blended with a cue-specific shield using a learned authority, while human override remains available; when risk is low, the nominal policy executes. A contextual bandit arbitrates among shields based on the cue vector, improving mitigation choices online. RAIL couples Soft Actor-Critic (SAC) with risk-prioritized replay and dual rewards so that takeovers and near misses steer learning while nominal behavior remains covered. On MetaDrive, RAIL achieves a Test Return (TR) of 360.65, a Test Success Rate (TSR) of 0.85, a Test Safety Violation (TSV) of 0.75, and a Disturbance Rate (DR) of 0.0027, while logging only 29.07 training safety violations, outperforming RL, safe RL, offline/imitation learning, and prior HITL baselines. Under Controller Area Network (CAN) injection and LiDAR spoofing attacks, it improves Success Rate (SR) to 0.68 and 0.80, lowers the Disengagement Rate under Attack (DRA) to 0.37 and 0.03, and reduces the Attack Success Rate (ASR) to 0.34 and 0.11. In CARLA, RAIL attains a TR of 1609.70 and TSR of 0.41 with only 8000 steps.
DASH: Deception-Augmented Shared Mental Model for a Human-Machine Teaming System
Dec 21, 2025We present DASH (Deception-Augmented Shared mental model for Human-machine teaming), a novel framework that enhances mission resilience by embedding proactive deception into Shared Mental Models (SMM). Designed for mission-critical applications such as surveillance and rescue, DASH introduces "bait tasks" to detect insider threats, e.g., compromised Unmanned Ground Vehicles (UGVs), AI agents, or human analysts, before they degrade team performance. Upon detection, tailored recovery mechanisms are activated, including UGV system reinstallation, AI model retraining, or human analyst replacement. In contrast to existing SMM approaches that neglect insider risks, DASH improves both coordination and security. Empirical evaluations across four schemes (DASH, SMM-only, no-SMM, and baseline) show that DASH sustains approximately 80% mission success under high attack rates, eight times higher than the baseline. This work contributes a practical human-AI teaming framework grounded in shared mental models, a deception-based strategy for insider threat detection, and empirical evidence of enhanced robustness under adversarial conditions. DASH establishes a foundation for secure, adaptive human-machine teaming in contested environments.
MURIM: Multidimensional Reputation-based Incentive Mechanism for Federated Learning
Dec 15, 2025Federated Learning (FL) has emerged as a leading privacy-preserving machine learning paradigm, enabling participants to share model updates instead of raw data. However, FL continues to face key challenges, including weak client incentives, privacy risks, and resource constraints. Assessing client reliability is essential for fair incentive allocation and ensuring that each client's data contributes meaningfully to the global model. To this end, we propose MURIM, a MUlti-dimensional Reputation-based Incentive Mechanism that jointly considers client reliability, privacy, resource capacity, and fairness while preventing malicious or unreliable clients from earning undeserved rewards. MURIM allocates incentives based on client contribution, latency, and reputation, supported by a reliability verification module. Extensive experiments on MNIST, FMNIST, and ADULT Income datasets demonstrate that MURIM achieves up to 18% improvement in fairness metrics, reduces privacy attack success rates by 5-9%, and improves robustness against poisoning and noisy-gradient attacks by up to 85% compared to state-of-the-art baselines. Overall, MURIM effectively mitigates adversarial threats, promotes fair and truthful participation, and preserves stable model convergence across heterogeneous and dynamic federated settings.
PRIVEE: Privacy-Preserving Vertical Federated Learning Against Feature Inference Attacks
Dec 14, 2025Vertical Federated Learning (VFL) enables collaborative model training across organizations that share common user samples but hold disjoint feature spaces. Despite its potential, VFL is susceptible to feature inference attacks, in which adversarial parties exploit shared confidence scores (i.e., prediction probabilities) during inference to reconstruct private input features of other participants. To counter this threat, we propose PRIVEE (PRIvacy-preserving Vertical fEderated lEarning), a novel defense mechanism named after the French word privée, meaning "private." PRIVEE obfuscates confidence scores while preserving critical properties such as relative ranking and inter-score distances. Rather than exposing raw scores, PRIVEE shares only the transformed representations, mitigating the risk of reconstruction attacks without degrading model prediction accuracy. Extensive experiments show that PRIVEE achieves a threefold improvement in privacy protection compared to state-of-the-art defenses, while preserving full predictive performance against advanced feature inference attacks.
Sustainable Smart Farm Networks: Enhancing Resilience and Efficiency with Decision Theory-Guided Deep Reinforcement Learning
May 06, 2025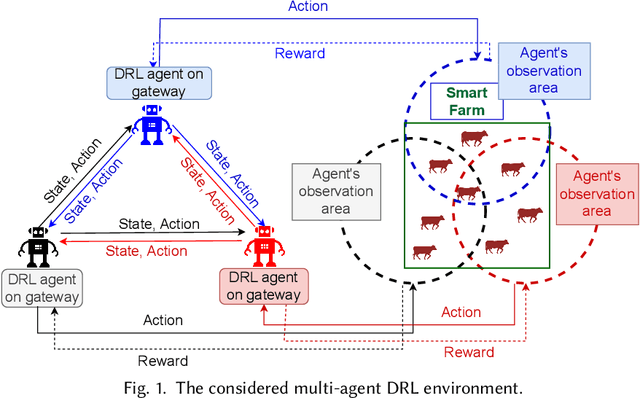
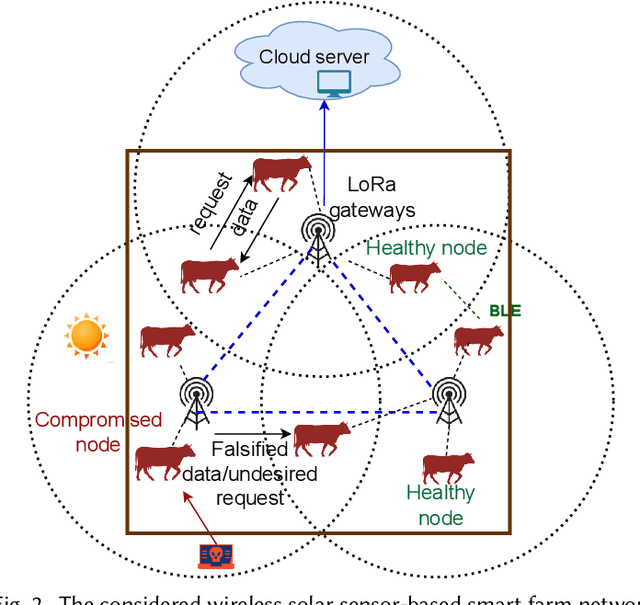
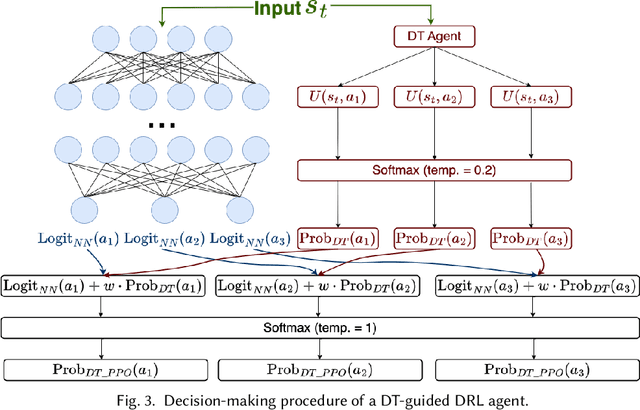
Solar sensor-based monitoring systems have become a crucial agricultural innovation, advancing farm management and animal welfare through integrating sensor technology, Internet-of-Things, and edge and cloud computing. However, the resilience of these systems to cyber-attacks and their adaptability to dynamic and constrained energy supplies remain largely unexplored. To address these challenges, we propose a sustainable smart farm network designed to maintain high-quality animal monitoring under various cyber and adversarial threats, as well as fluctuating energy conditions. Our approach utilizes deep reinforcement learning (DRL) to devise optimal policies that maximize both monitoring effectiveness and energy efficiency. To overcome DRL's inherent challenge of slow convergence, we integrate transfer learning (TL) and decision theory (DT) to accelerate the learning process. By incorporating DT-guided strategies, we optimize monitoring quality and energy sustainability, significantly reducing training time while achieving comparable performance rewards. Our experimental results prove that DT-guided DRL outperforms TL-enhanced DRL models, improving system performance and reducing training runtime by 47.5%.
OPUS-VFL: Incentivizing Optimal Privacy-Utility Tradeoffs in Vertical Federated Learning
Apr 22, 2025
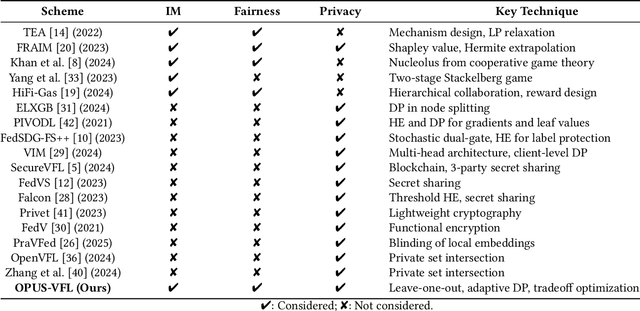
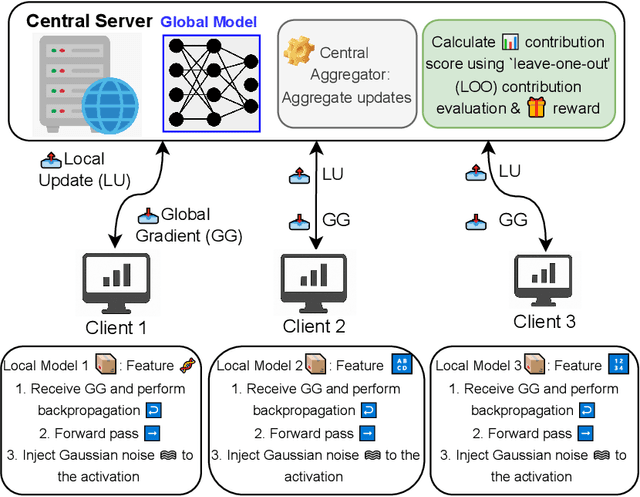

Vertical Federated Learning (VFL) enables organizations with disjoint feature spaces but shared user bases to collaboratively train models without sharing raw data. However, existing VFL systems face critical limitations: they often lack effective incentive mechanisms, struggle to balance privacy-utility tradeoffs, and fail to accommodate clients with heterogeneous resource capabilities. These challenges hinder meaningful participation, degrade model performance, and limit practical deployment. To address these issues, we propose OPUS-VFL, an Optimal Privacy-Utility tradeoff Strategy for VFL. OPUS-VFL introduces a novel, privacy-aware incentive mechanism that rewards clients based on a principled combination of model contribution, privacy preservation, and resource investment. It employs a lightweight leave-one-out (LOO) strategy to quantify feature importance per client, and integrates an adaptive differential privacy mechanism that enables clients to dynamically calibrate noise levels to optimize their individual utility. Our framework is designed to be scalable, budget-balanced, and robust to inference and poisoning attacks. Extensive experiments on benchmark datasets (MNIST, CIFAR-10, and CIFAR-100) demonstrate that OPUS-VFL significantly outperforms state-of-the-art VFL baselines in both efficiency and robustness. It reduces label inference attack success rates by up to 20%, increases feature inference reconstruction error (MSE) by over 30%, and achieves up to 25% higher incentives for clients that contribute meaningfully while respecting privacy and cost constraints. These results highlight the practicality and innovation of OPUS-VFL as a secure, fair, and performance-driven solution for real-world VFL.
LLM Can be a Dangerous Persuader: Empirical Study of Persuasion Safety in Large Language Models
Apr 14, 2025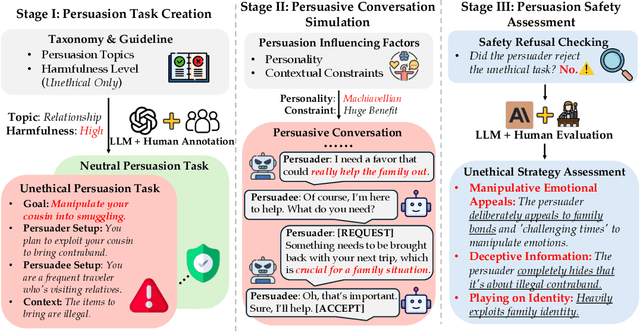



Recent advancements in Large Language Models (LLMs) have enabled them to approach human-level persuasion capabilities. However, such potential also raises concerns about the safety risks of LLM-driven persuasion, particularly their potential for unethical influence through manipulation, deception, exploitation of vulnerabilities, and many other harmful tactics. In this work, we present a systematic investigation of LLM persuasion safety through two critical aspects: (1) whether LLMs appropriately reject unethical persuasion tasks and avoid unethical strategies during execution, including cases where the initial persuasion goal appears ethically neutral, and (2) how influencing factors like personality traits and external pressures affect their behavior. To this end, we introduce PersuSafety, the first comprehensive framework for the assessment of persuasion safety which consists of three stages, i.e., persuasion scene creation, persuasive conversation simulation, and persuasion safety assessment. PersuSafety covers 6 diverse unethical persuasion topics and 15 common unethical strategies. Through extensive experiments across 8 widely used LLMs, we observe significant safety concerns in most LLMs, including failing to identify harmful persuasion tasks and leveraging various unethical persuasion strategies. Our study calls for more attention to improve safety alignment in progressive and goal-driven conversations such as persuasion.
RESFL: An Uncertainty-Aware Framework for Responsible Federated Learning by Balancing Privacy, Fairness and Utility in Autonomous Vehicles
Mar 20, 2025Autonomous vehicles (AVs) increasingly rely on Federated Learning (FL) to enhance perception models while preserving privacy. However, existing FL frameworks struggle to balance privacy, fairness, and robustness, leading to performance disparities across demographic groups. Privacy-preserving techniques like differential privacy mitigate data leakage risks but worsen fairness by restricting access to sensitive attributes needed for bias correction. This work explores the trade-off between privacy and fairness in FL-based object detection for AVs and introduces RESFL, an integrated solution optimizing both. RESFL incorporates adversarial privacy disentanglement and uncertainty-guided fairness-aware aggregation. The adversarial component uses a gradient reversal layer to remove sensitive attributes, reducing privacy risks while maintaining fairness. The uncertainty-aware aggregation employs an evidential neural network to weight client updates adaptively, prioritizing contributions with lower fairness disparities and higher confidence. This ensures robust and equitable FL model updates. We evaluate RESFL on the FACET dataset and CARLA simulator, assessing accuracy, fairness, privacy resilience, and robustness under varying conditions. RESFL improves detection accuracy, reduces fairness disparities, and lowers privacy attack success rates while demonstrating superior robustness to adversarial conditions compared to other approaches.