 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreserving Full 6-DOF Actuation Under Abrupt Total Rotor Failures: Passive Fault-Tolerant Flight Control Using a Biaxial-Tilt Hexacopter
Jun 04, 2026Conventional multirotors suffer from a rapid collapse of attainable wrench space (AWS) under abrupt total rotor failures, rendering full 6-DOF recovery physically impossible. This paper addresses passive fault-tolerant flight of a biaxial-tilt overactuated hexacopter (BTO) under abrupt total rotor failures that are a priori unknown to the controller. The control design and analysis focus on representative abrupt rotor-failure cases for which the post-failure system remains fully actuated, while no explicit fault detection, isolation, or fault-mode switching is assumed. First, we extend the inscribed-sphere metric of the AWS by incorporating the transient-wrench-jump term, enabling quantitative feasibility assessment under up to three simultaneous rotor failures and benchmarking against uniaxial-tilt and coplanar hexacopters. Second, we develop two computationally efficient passive schemes without relying on fault detection or online optimization. One scheme operates at the controller layer by combining a high-order fully actuated (HOFA) controller with a linear extended state observer (LESO) for lumped-disturbance rejection. The other scheme operates at the allocator layer by using model-reference adaptive control allocation with momentum-based wrench estimation to compensate for control-allocation biases. Simulations and flight experiments validate stable hovering and 6-DOF trajectory tracking under single and multiple rotor failures. Further systematic comparisons confirm that the BTO provides larger recovery margins than uniaxial-tilt and coplanar designs. Additional onboard-sensor-only experiments, including indoor tracking under wind disturbance, outdoor tracking under extreme conditions, narrow-frame traversal, and contact-based aerial writing, further validate the robustness of the proposed framework in complex operational environments.
ADAM: A Systematic Data Extraction Attack on Agent Memory via Adaptive Querying
Apr 10, 2026Large Language Model (LLM) agents have achieved rapid adoption and demonstrated remarkable capabilities across a wide range of applications. To improve reasoning and task execution, modern LLM agents would incorporate memory modules or retrieval-augmented generation (RAG) mechanisms, enabling them to further leverage prior interactions or external knowledge. However, such a design also introduces a group of critical privacy vulnerabilities: sensitive information stored in memory can be leaked through query-based attacks. Although feasible, existing attacks often achieve only limited performance, with low attack success rates (ASR). In this paper, we propose ADAM, a novel privacy attack that features data distribution estimation of a victim agent's memory and employs an entropy-guided query strategy for maximizing privacy leakage. Extensive experiments demonstrate that our attack substantially outperforms state-of-the-art ones, achieving up to 100% ASRs. These results thus underscore the urgent need for robust privacy-preserving methods for current LLM agents.
Youtu-VL: Unleashing Visual Potential via Unified Vision-Language Supervision
Jan 27, 2026Despite the significant advancements represented by Vision-Language Models (VLMs), current architectures often exhibit limitations in retaining fine-grained visual information, leading to coarse-grained multimodal comprehension. We attribute this deficiency to a suboptimal training paradigm inherent in prevailing VLMs, which exhibits a text-dominant optimization bias by conceptualizing visual signals merely as passive conditional inputs rather than supervisory targets. To mitigate this, we introduce Youtu-VL, a framework leveraging the Vision-Language Unified Autoregressive Supervision (VLUAS) paradigm, which fundamentally shifts the optimization objective from ``vision-as-input'' to ``vision-as-target.'' By integrating visual tokens directly into the prediction stream, Youtu-VL applies unified autoregressive supervision to both visual details and linguistic content. Furthermore, we extend this paradigm to encompass vision-centric tasks, enabling a standard VLM to perform vision-centric tasks without task-specific additions. Extensive empirical evaluations demonstrate that Youtu-VL achieves competitive performance on both general multimodal tasks and vision-centric tasks, establishing a robust foundation for the development of comprehensive generalist visual agents.
Youtu-LLM: Unlocking the Native Agentic Potential for Lightweight Large Language Models
Dec 31, 2025We introduce Youtu-LLM, a lightweight yet powerful language model that harmonizes high computational efficiency with native agentic intelligence. Unlike typical small models that rely on distillation, Youtu-LLM (1.96B) is pre-trained from scratch to systematically cultivate reasoning and planning capabilities. The key technical advancements are as follows: (1) Compact Architecture with Long-Context Support: Built on a dense Multi-Latent Attention (MLA) architecture with a novel STEM-oriented vocabulary, Youtu-LLM supports a 128k context window. This design enables robust long-context reasoning and state tracking within a minimal memory footprint, making it ideal for long-horizon agent and reasoning tasks. (2) Principled "Commonsense-STEM-Agent" Curriculum: We curated a massive corpus of approximately 11T tokens and implemented a multi-stage training strategy. By progressively shifting the pre-training data distribution from general commonsense to complex STEM and agentic tasks, we ensure the model acquires deep cognitive abilities rather than superficial alignment. (3) Scalable Agentic Mid-training: Specifically for the agentic mid-training, we employ diverse data construction schemes to synthesize rich and varied trajectories across math, coding, and tool-use domains. This high-quality data enables the model to internalize planning and reflection behaviors effectively. Extensive evaluations show that Youtu-LLM sets a new state-of-the-art for sub-2B LLMs. On general benchmarks, it achieves competitive performance against larger models, while on agent-specific tasks, it significantly surpasses existing SOTA baselines, demonstrating that lightweight models can possess strong intrinsic agentic capabilities.
MDSEval: A Meta-Evaluation Benchmark for Multimodal Dialogue Summarization
Oct 02, 2025Multimodal Dialogue Summarization (MDS) is a critical task with wide-ranging applications. To support the development of effective MDS models, robust automatic evaluation methods are essential for reducing both cost and human effort. However, such methods require a strong meta-evaluation benchmark grounded in human annotations. In this work, we introduce MDSEval, the first meta-evaluation benchmark for MDS, consisting image-sharing dialogues, corresponding summaries, and human judgments across eight well-defined quality aspects. To ensure data quality and richfulness, we propose a novel filtering framework leveraging Mutually Exclusive Key Information (MEKI) across modalities. Our work is the first to identify and formalize key evaluation dimensions specific to MDS. We benchmark state-of-the-art modal evaluation methods, revealing their limitations in distinguishing summaries from advanced MLLMs and their susceptibility to various bias.
ASPD: Unlocking Adaptive Serial-Parallel Decoding by Exploring Intrinsic Parallelism in LLMs
Aug 12, 2025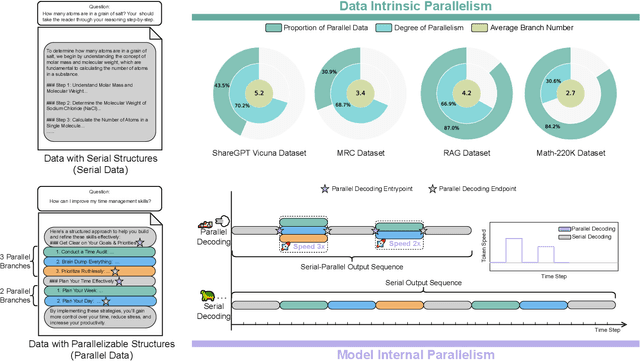
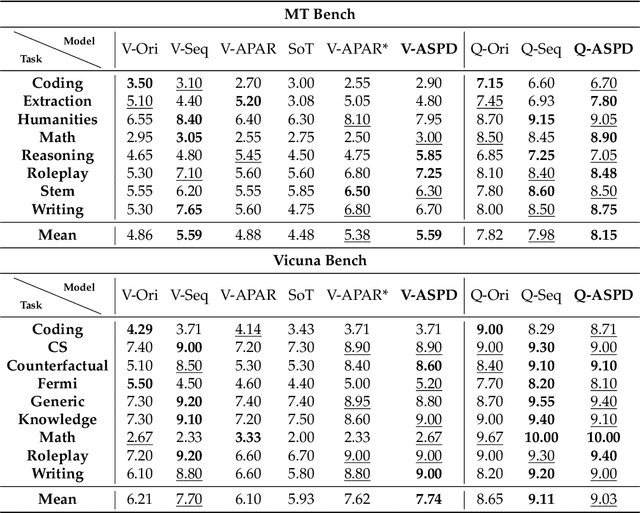
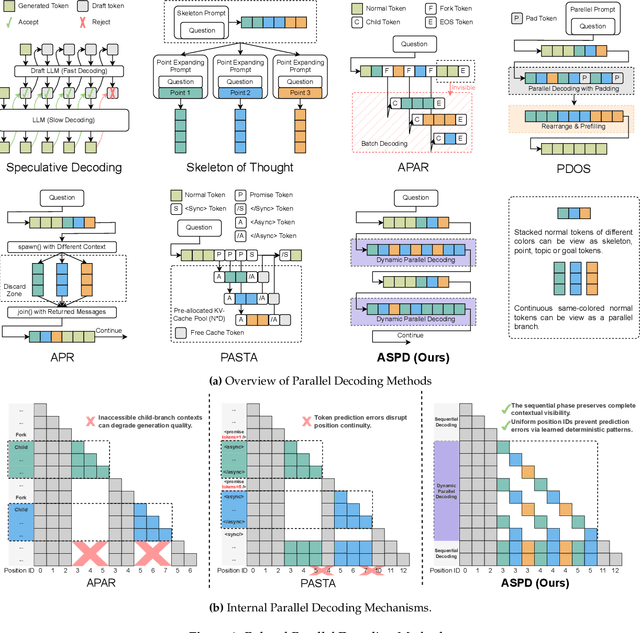
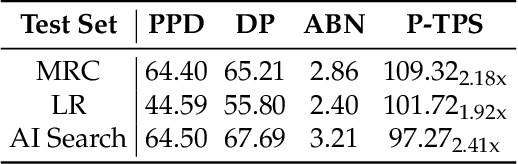
The increasing scale and complexity of large language models (LLMs) pose significant inference latency challenges, primarily due to their autoregressive decoding paradigm characterized by the sequential nature of next-token prediction. By re-examining the outputs of autoregressive models, we observed that some segments exhibit parallelizable structures, which we term intrinsic parallelism. Decoding each parallelizable branch simultaneously (i.e. parallel decoding) can significantly improve the overall inference speed of LLMs. In this paper, we propose an Adaptive Serial-Parallel Decoding (ASPD), which addresses two core challenges: automated construction of parallelizable data and efficient parallel decoding mechanism. More specifically, we introduce a non-invasive pipeline that automatically extracts and validates parallelizable structures from the responses of autoregressive models. To empower efficient adaptive serial-parallel decoding, we implement a Hybrid Decoding Engine which enables seamless transitions between serial and parallel decoding modes while maintaining a reusable KV cache, maximizing computational efficiency. Extensive evaluations across General Tasks, Retrieval-Augmented Generation, Mathematical Reasoning, demonstrate that ASPD achieves unprecedented performance in both effectiveness and efficiency. Notably, on Vicuna Bench, our method achieves up to 3.19x speedup (1.85x on average) while maintaining response quality within 1% difference compared to autoregressive models, realizing significant acceleration without compromising generation quality. Our framework sets a groundbreaking benchmark for efficient LLM parallel inference, paving the way for its deployment in latency-sensitive applications such as AI-powered customer service bots and answer retrieval engines.
GLEAN: Generalized Category Discovery with Diverse and Quality-Enhanced LLM Feedback
Feb 25, 2025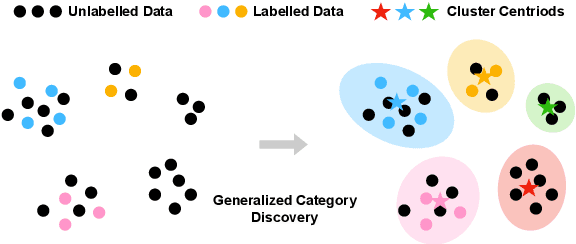
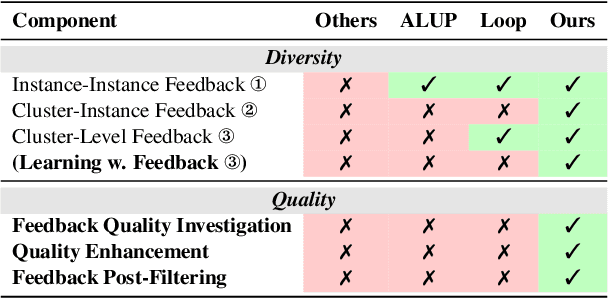
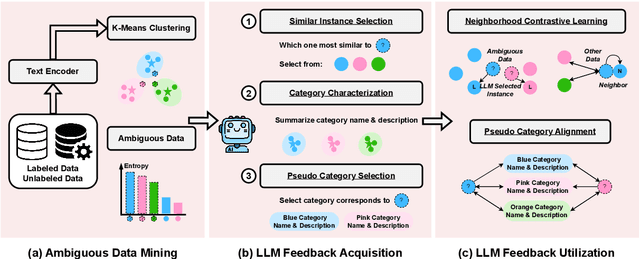
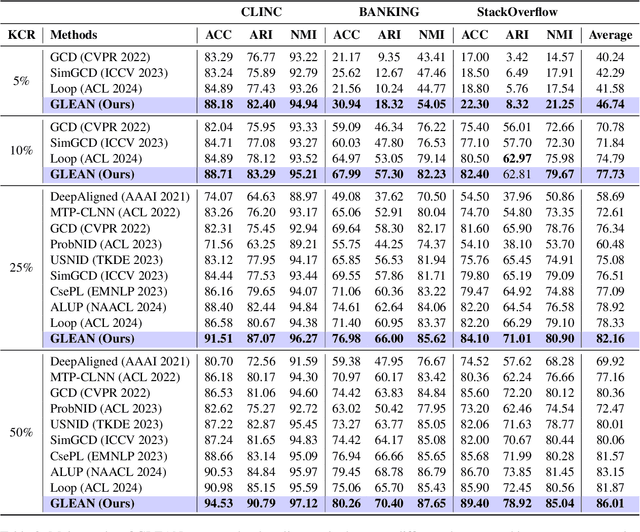
Generalized Category Discovery (GCD) is a practical and challenging open-world task that aims to recognize both known and novel categories in unlabeled data using limited labeled data from known categories. Due to the lack of supervision, previous GCD methods face significant challenges, such as difficulty in rectifying errors for confusing instances, and inability to effectively uncover and leverage the semantic meanings of discovered clusters. Therefore, additional annotations are usually required for real-world applicability. However, human annotation is extremely costly and inefficient. To address these issues, we propose GLEAN, a unified framework for generalized category discovery that actively learns from diverse and quality-enhanced LLM feedback. Our approach leverages three different types of LLM feedback to: (1) improve instance-level contrastive features, (2) generate category descriptions, and (3) align uncertain instances with LLM-selected category descriptions. Extensive experiments demonstrate the superior performance of \MethodName over state-of-the-art models across diverse datasets, metrics, and supervision settings. Our code is available at https://github.com/amazon-science/Glean.
Faithful, Unfaithful or Ambiguous? Multi-Agent Debate with Initial Stance for Summary Evaluation
Feb 12, 2025Faithfulness evaluators based on large language models (LLMs) are often fooled by the fluency of the text and struggle with identifying errors in the summaries. We propose an approach to summary faithfulness evaluation in which multiple LLM-based agents are assigned initial stances (regardless of what their belief might be) and forced to come up with a reason to justify the imposed belief, thus engaging in a multi-round debate to reach an agreement. The uniformly distributed initial assignments result in a greater diversity of stances leading to more meaningful debates and ultimately more errors identified. Furthermore, by analyzing the recent faithfulness evaluation datasets, we observe that naturally, it is not always the case for a summary to be either faithful to the source document or not. We therefore introduce a new dimension, ambiguity, and a detailed taxonomy to identify such special cases. Experiments demonstrate our approach can help identify ambiguities, and have even a stronger performance on non-ambiguous summaries.
Rethinking the Uncertainty: A Critical Review and Analysis in the Era of Large Language Models
Oct 26, 2024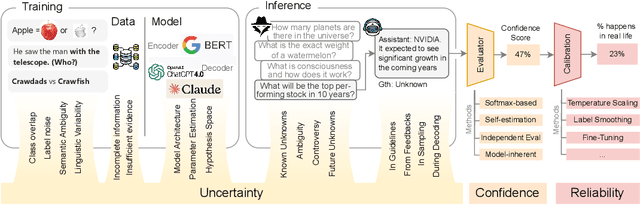
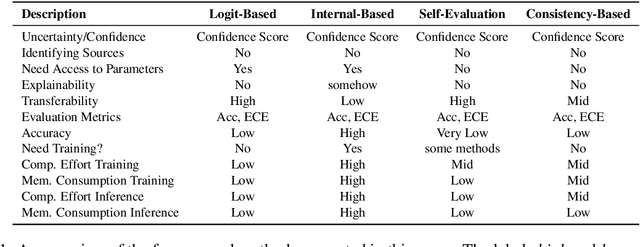
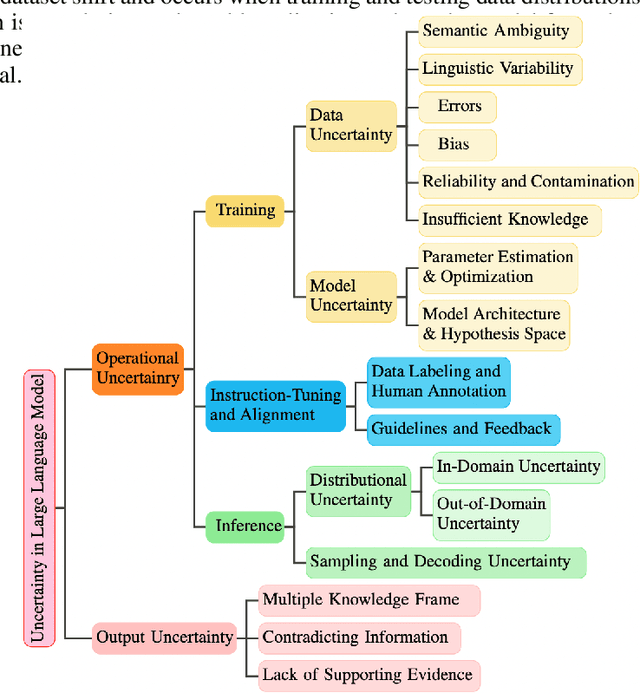
In recent years, Large Language Models (LLMs) have become fundamental to a broad spectrum of artificial intelligence applications. As the use of LLMs expands, precisely estimating the uncertainty in their predictions has become crucial. Current methods often struggle to accurately identify, measure, and address the true uncertainty, with many focusing primarily on estimating model confidence. This discrepancy is largely due to an incomplete understanding of where, when, and how uncertainties are injected into models. This paper introduces a comprehensive framework specifically designed to identify and understand the types and sources of uncertainty, aligned with the unique characteristics of LLMs. Our framework enhances the understanding of the diverse landscape of uncertainties by systematically categorizing and defining each type, establishing a solid foundation for developing targeted methods that can precisely quantify these uncertainties. We also provide a detailed introduction to key related concepts and examine the limitations of current methods in mission-critical and safety-sensitive applications. The paper concludes with a perspective on future directions aimed at enhancing the reliability and practical adoption of these methods in real-world scenarios.
Large Language Models for Multimodal Deformable Image Registration
Aug 20, 2024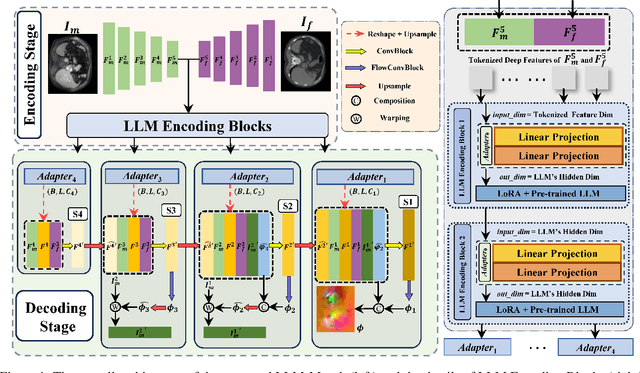
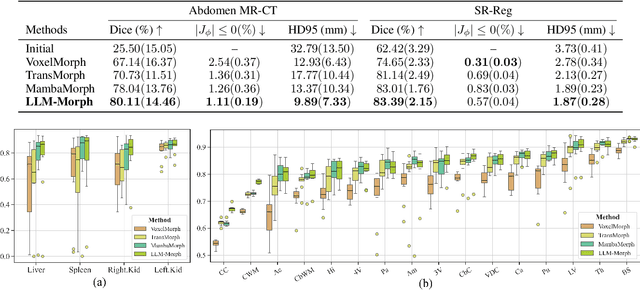
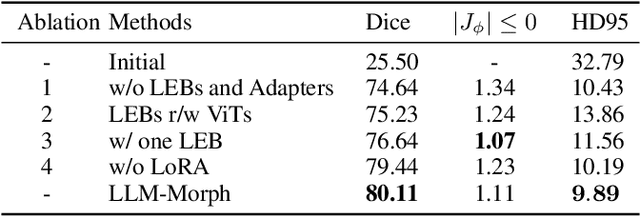
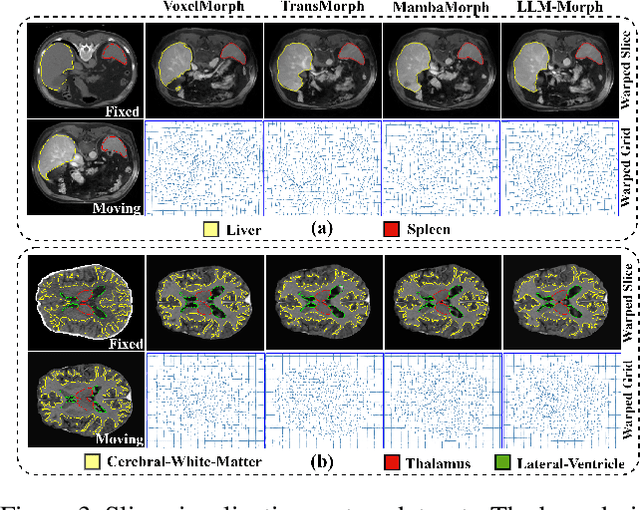
The challenge of Multimodal Deformable Image Registration (MDIR) lies in the conversion and alignment of features between images of different modalities. Generative models (GMs) cannot retain the necessary information enough from the source modality to the target one, while non-GMs struggle to align features across these two modalities. In this paper, we propose a novel coarse-to-fine MDIR framework,LLM-Morph, which is applicable to various pre-trained Large Language Models (LLMs) to solve these concerns by aligning the deep features from different modal medical images. Specifically, we first utilize a CNN encoder to extract deep visual features from cross-modal image pairs, then we use the first adapter to adjust these tokens, and use LoRA in pre-trained LLMs to fine-tune their weights, both aimed at eliminating the domain gap between the pre-trained LLMs and the MDIR task. Third, for the alignment of tokens, we utilize other four adapters to transform the LLM-encoded tokens into multi-scale visual features, generating multi-scale deformation fields and facilitating the coarse-to-fine MDIR task. Extensive experiments in MR-CT Abdomen and SR-Reg Brain datasets demonstrate the effectiveness of our framework and the potential of pre-trained LLMs for MDIR task. Our code is availabel at: https://github.com/ninjannn/LLM-Morph.