 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternalInspector $I^2$: Robust Confidence Estimation in LLMs through Internal States
Jun 17, 2024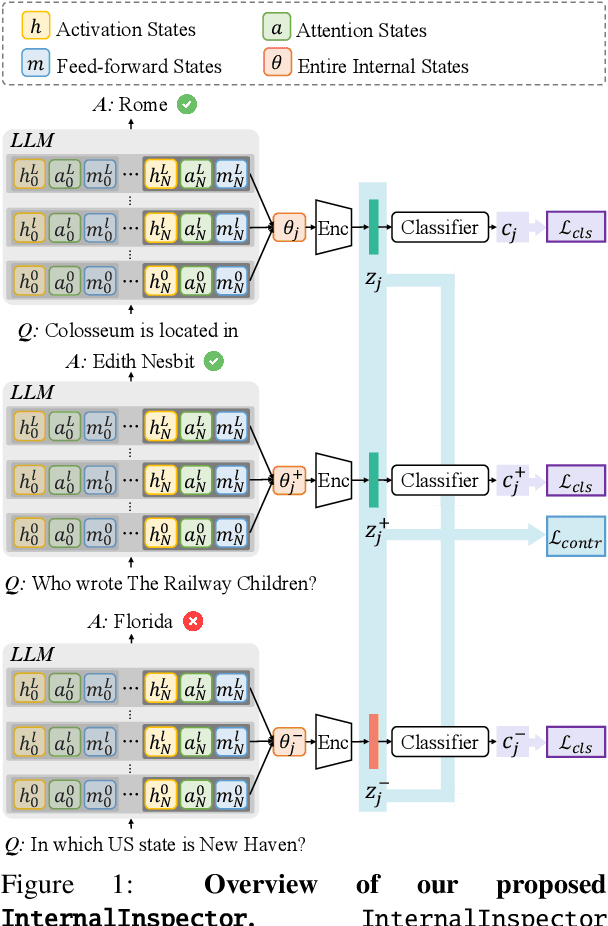
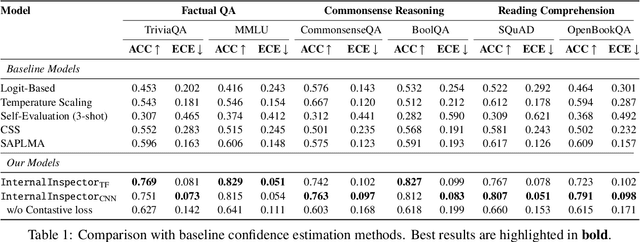
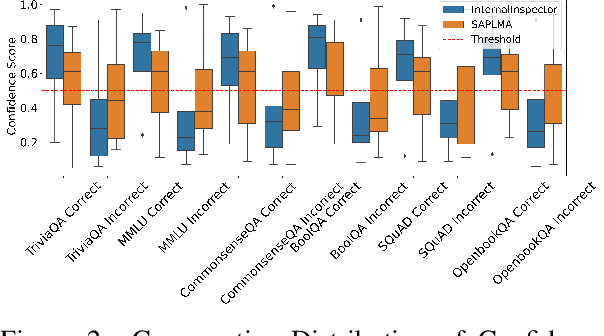
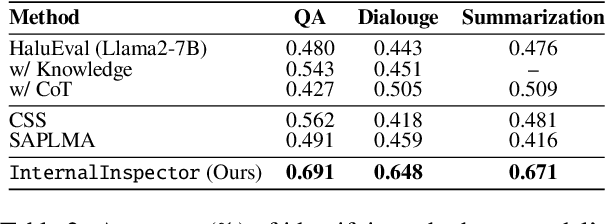
Despite their vast capabilities, Large Language Models (LLMs) often struggle with generating reliable outputs, frequently producing high-confidence inaccuracies known as hallucinations. Addressing this challenge, our research introduces InternalInspector, a novel framework designed to enhance confidence estimation in LLMs by leveraging contrastive learning on internal states including attention states, feed-forward states, and activation states of all layers. Unlike existing methods that primarily focus on the final activation state, InternalInspector conducts a comprehensive analysis across all internal states of every layer to accurately identify both correct and incorrect prediction processes. By benchmarking InternalInspector against existing confidence estimation methods across various natural language understanding and generation tasks, including factual question answering, commonsense reasoning, and reading comprehension, InternalInspector achieves significantly higher accuracy in aligning the estimated confidence scores with the correctness of the LLM's predictions and lower calibration error. Furthermore, InternalInspector excels at HaluEval, a hallucination detection benchmark, outperforming other internal-based confidence estimation methods in this task.
Graph Signal Recovery Using Restricted Boltzmann Machines
Nov 20, 2020



We propose a model-agnostic pipeline to recover graph signals from an expert system by exploiting the content addressable memory property of restricted Boltzmann machine and the representational ability of a neural network. The proposed pipeline requires the deep neural network that is trained on a downward machine learning task with clean data, data which is free from any form of corruption or incompletion. We show that denoising the representations learned by the deep neural networks is usually more effective than denoising the data itself. Although this pipeline can deal with noise in any dataset, it is particularly effective for graph-structured datasets.