 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccidentBench: Benchmarking Multimodal Understanding and Reasoning in Vehicle Accidents and Beyond
Sep 30, 2025Rapid advances in multimodal models demand benchmarks that rigorously evaluate understanding and reasoning in safety-critical, dynamic real-world settings. We present AccidentBench, a large-scale benchmark that combines vehicle accident scenarios with Beyond domains, safety-critical settings in air and water that emphasize spatial and temporal reasoning (e.g., navigation, orientation, multi-vehicle motion). The benchmark contains approximately 2000 videos and over 19000 human-annotated question--answer pairs spanning multiple video lengths (short/medium/long) and difficulty levels (easy/medium/hard). Tasks systematically probe core capabilities: temporal, spatial, and intent understanding and reasoning. By unifying accident-centric traffic scenes with broader safety-critical scenarios in air and water, AccidentBench offers a comprehensive, physically grounded testbed for evaluating models under real-world variability. Evaluations of state-of-the-art models (e.g., Gemini-2.5 Pro and GPT-5) show that even the strongest models achieve only about 18% accuracy on the hardest tasks and longest videos, revealing substantial gaps in real-world temporal, spatial, and intent reasoning. AccidentBench is designed to expose these critical gaps and drive the development of multimodal models that are safer, more robust, and better aligned with real-world safety-critical challenges. The code and dataset are available at: https://github.com/SafeRL-Lab/AccidentBench
Can We Trust the Performance Evaluation of Uncertainty Estimation Methods in Text Summarization?
Jun 25, 2024Text summarization, a key natural language generation (NLG) task, is vital in various domains. However, the high cost of inaccurate summaries in risk-critical applications, particularly those involving human-in-the-loop decision-making, raises concerns about the reliability of uncertainty estimation on text summarization (UE-TS) evaluation methods. This concern stems from the dependency of uncertainty model metrics on diverse and potentially conflicting NLG metrics. To address this issue, we introduce a comprehensive UE-TS benchmark incorporating 31 NLG metrics across four dimensions. The benchmark evaluates the uncertainty estimation capabilities of two large language models and one pre-trained language model on three datasets, with human-annotation analysis incorporated where applicable. We also assess the performance of 14 common uncertainty estimation methods within this benchmark. Our findings emphasize the importance of considering multiple uncorrelated NLG metrics and diverse uncertainty estimation methods to ensure reliable and efficient evaluation of UE-TS techniques.
InternalInspector $I^2$: Robust Confidence Estimation in LLMs through Internal States
Jun 17, 2024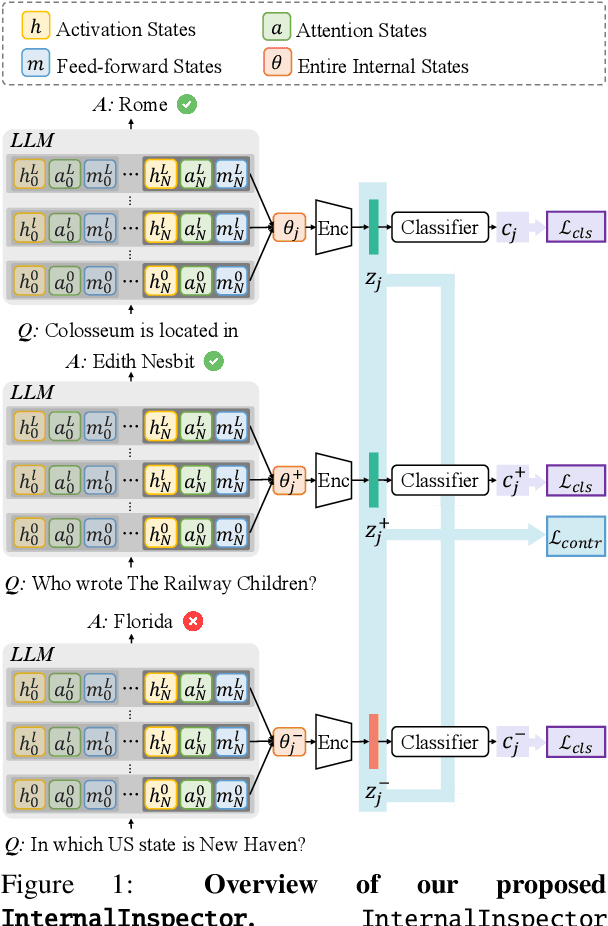
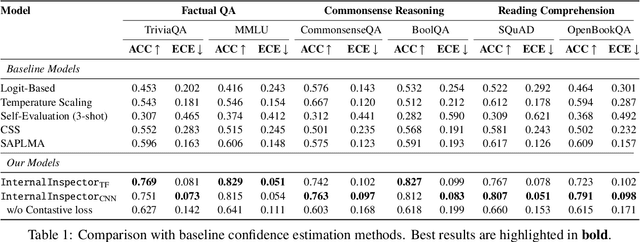
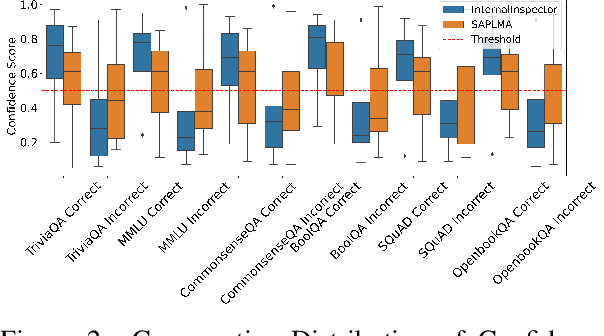
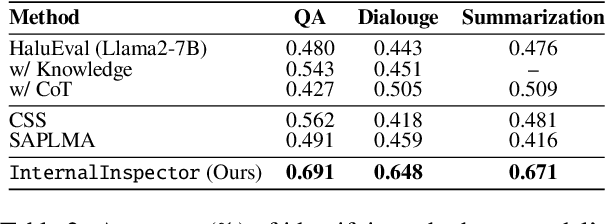
Despite their vast capabilities, Large Language Models (LLMs) often struggle with generating reliable outputs, frequently producing high-confidence inaccuracies known as hallucinations. Addressing this challenge, our research introduces InternalInspector, a novel framework designed to enhance confidence estimation in LLMs by leveraging contrastive learning on internal states including attention states, feed-forward states, and activation states of all layers. Unlike existing methods that primarily focus on the final activation state, InternalInspector conducts a comprehensive analysis across all internal states of every layer to accurately identify both correct and incorrect prediction processes. By benchmarking InternalInspector against existing confidence estimation methods across various natural language understanding and generation tasks, including factual question answering, commonsense reasoning, and reading comprehension, InternalInspector achieves significantly higher accuracy in aligning the estimated confidence scores with the correctness of the LLM's predictions and lower calibration error. Furthermore, InternalInspector excels at HaluEval, a hallucination detection benchmark, outperforming other internal-based confidence estimation methods in this task.