 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcise Geometric Description as a Bridge: Unleashing the Potential of LLM for Plane Geometry Problem Solving
Jan 29, 2026Plane Geometry Problem Solving (PGPS) is a multimodal reasoning task that aims to solve a plane geometric problem based on a geometric diagram and problem textual descriptions. Although Large Language Models (LLMs) possess strong reasoning skills, their direct application to PGPS is hindered by their inability to process visual diagrams. Existing works typically fine-tune Multimodal LLMs (MLLMs) end-to-end on large-scale PGPS data to enhance visual understanding and reasoning simultaneously. However, such joint optimization may compromise base LLMs' inherent reasoning capability. In this work, we observe that LLM itself is potentially a powerful PGPS solver when appropriately formulating visual information as textual descriptions. We propose to train a MLLM Interpreter to generate geometric descriptions for the visual diagram, and an off-the-shelf LLM is utilized to perform reasoning. Specifically, we choose Conditional Declaration Language (CDL) as the geometric description as its conciseness eases the MLLM Interpreter training. The MLLM Interpreter is fine-tuned via CoT (Chain-of-Thought)-augmented SFT followed by GRPO to generate CDL. Instead of using a conventional solution-based reward that compares the reasoning result with the ground-truth answer, we design CDL matching rewards to facilitate more effective GRPO training, which provides more direct and denser guidance for CDL generation. To support training, we construct a new dataset, Formalgeo7k-Rec-CoT, by manually reviewing Formalgeo7k v2 and incorporating CoT annotations. Extensive experiments on Formalgeo7k-Rec-CoT, Unigeo, and MathVista show our method (finetuned on only 5.5k data) performs favorably against leading open-source and closed-source MLLMs.
Your Group-Relative Advantage Is Biased
Jan 13, 2026Reinforcement Learning from Verifier Rewards (RLVR) has emerged as a widely used approach for post-training large language models on reasoning tasks, with group-based methods such as GRPO and its variants gaining broad adoption. These methods rely on group-relative advantage estimation to avoid learned critics, yet its theoretical properties remain poorly understood. In this work, we uncover a fundamental issue of group-based RL: the group-relative advantage estimator is inherently biased relative to the true (expected) advantage. We provide the first theoretical analysis showing that it systematically underestimates advantages for hard prompts and overestimates them for easy prompts, leading to imbalanced exploration and exploitation. To address this issue, we propose History-Aware Adaptive Difficulty Weighting (HA-DW), an adaptive reweighting scheme that adjusts advantage estimates based on an evolving difficulty anchor and training dynamics. Both theoretical analysis and experiments on five mathematical reasoning benchmarks demonstrate that HA-DW consistently improves performance when integrated into GRPO and its variants. Our results suggest that correcting biased advantage estimation is critical for robust and efficient RLVR training.
RadDiff: Describing Differences in Radiology Image Sets with Natural Language
Jan 07, 2026Understanding how two radiology image sets differ is critical for generating clinical insights and for interpreting medical AI systems. We introduce RadDiff, a multimodal agentic system that performs radiologist-style comparative reasoning to describe clinically meaningful differences between paired radiology studies. RadDiff builds on a proposer-ranker framework from VisDiff, and incorporates four innovations inspired by real diagnostic workflows: (1) medical knowledge injection through domain-adapted vision-language models; (2) multimodal reasoning that integrates images with their clinical reports; (3) iterative hypothesis refinement across multiple reasoning rounds; and (4) targeted visual search that localizes and zooms in on salient regions to capture subtle findings. To evaluate RadDiff, we construct RadDiffBench, a challenging benchmark comprising 57 expert-validated radiology study pairs with ground-truth difference descriptions. On RadDiffBench, RadDiff achieves 47% accuracy, and 50% accuracy when guided by ground-truth reports, significantly outperforming the general-domain VisDiff baseline. We further demonstrate RadDiff's versatility across diverse clinical tasks, including COVID-19 phenotype comparison, racial subgroup analysis, and discovery of survival-related imaging features. Together, RadDiff and RadDiffBench provide the first method-and-benchmark foundation for systematically uncovering meaningful differences in radiological data.
Transductive Visual Programming: Evolving Tool Libraries from Experience for Spatial Reasoning
Dec 24, 2025
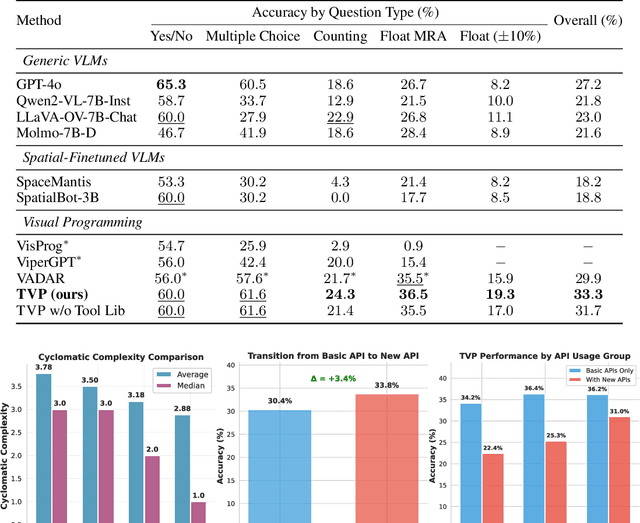
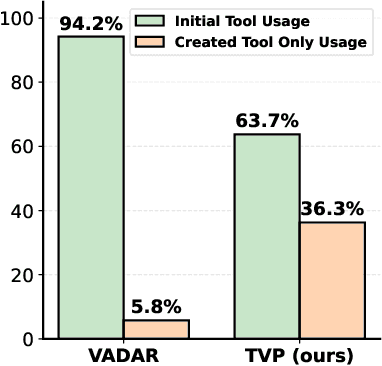
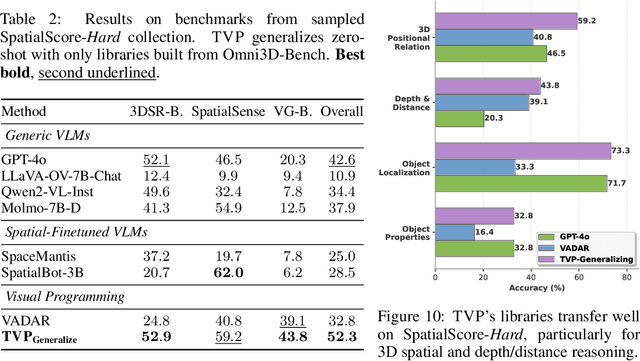
Spatial reasoning in 3D scenes requires precise geometric calculations that challenge vision-language models. Visual programming addresses this by decomposing problems into steps calling specialized tools, yet existing methods rely on either fixed toolsets or speculative tool induction before solving problems, resulting in suboptimal programs and poor utilization of induced tools. We present Transductive Visual Programming (TVP), a novel framework that builds new tools from its own experience rather than speculation. TVP first solves problems using basic tools while accumulating experiential solutions into an Example Library, then abstracts recurring patterns from these programs into reusable higher-level tools for an evolving Tool Library. This allows TVP to tackle new problems with increasingly powerful tools learned from experience. On Omni3D-Bench, TVP achieves state-of-the-art performance, outperforming GPT-4o by 22% and the previous best visual programming system by 11%. Our transductively learned tools are used 5x more frequently as core program dependency than inductively created ones, demonstrating more effective tool discovery and reuse. The evolved tools also show strong generalization to unseen spatial tasks, achieving superior performance on benchmarks from SpatialScore-Hard collection without any testset-specific modification. Our work establishes experience-driven transductive tool creation as a powerful paradigm for building self-evolving visual programming agents that effectively tackle challenging spatial reasoning tasks. We release our code at https://transductive-visualprogram.github.io/.
AWPO: Enhancing Tool-Use of Large Language Models through Explicit Integration of Reasoning Rewards
Dec 23, 2025While reinforcement learning (RL) shows promise in training tool-use large language models (LLMs) using verifiable outcome rewards, existing methods largely overlook the potential of explicit reasoning rewards to bolster reasoning and tool utilization. Furthermore, natively combining reasoning and outcome rewards may yield suboptimal performance or conflict with the primary optimization objective. To address this, we propose advantage-weighted policy optimization (AWPO) -- a principled RL framework that effectively integrates explicit reasoning rewards to enhance tool-use capability. AWPO incorporates variance-aware gating and difficulty-aware weighting to adaptively modulate advantages from reasoning signals based on group-relative statistics, alongside a tailored clipping mechanism for stable optimization. Extensive experiments demonstrate that AWPO achieves state-of-the-art performance across standard tool-use benchmarks, significantly outperforming strong baselines and leading closed-source models in challenging multi-turn scenarios. Notably, with exceptional parameter efficiency, our 4B model surpasses Grok-4 by 16.0 percent in multi-turn accuracy while preserving generalization capability on the out-of-distribution MMLU-Pro benchmark.
ToolForge: A Data Synthesis Pipeline for Multi-Hop Search without Real-World APIs
Dec 18, 2025Training LLMs to invoke tools and leverage retrieved information necessitates high-quality, diverse data. However, existing pipelines for synthetic data generation often rely on tens of thousands of real API calls to enhance generalization, incurring prohibitive costs while lacking multi-hop reasoning and self-reflection. To address these limitations, we introduce ToolForge, an automated synthesis framework that achieves strong real-world tool-calling performance by constructing only a small number of virtual tools, eliminating the need for real API calls. ToolForge leverages a (question, golden context, answer) triple to synthesize large-scale tool-learning data specifically designed for multi-hop search scenarios, further enriching the generated data through multi-hop reasoning and self-reflection mechanisms. To ensure data fidelity, we employ a Multi-Layer Validation Framework that integrates both rule-based and model-based assessments. Empirical results show that a model with only 8B parameters, when trained on our synthesized data, outperforms GPT-4o on multiple benchmarks. Our code and dataset are publicly available at https://github.com/Buycar-arb/ToolForge .
LocalSearchBench: Benchmarking Agentic Search in Real-World Local Life Services
Dec 08, 2025Recent advances in large reasoning models (LRMs) have enabled agentic search systems to perform complex multi-step reasoning across multiple sources. However, most studies focus on general information retrieval and rarely explores vertical domains with unique challenges. In this work, we focus on local life services and introduce LocalSearchBench, which encompass diverse and complex business scenarios. Real-world queries in this domain are often ambiguous and require multi-hop reasoning across merchants and products, remaining challenging and not fully addressed. As the first comprehensive benchmark for agentic search in local life services, LocalSearchBench includes over 150,000 high-quality entries from various cities and business types. We construct 300 multi-hop QA tasks based on real user queries, challenging agents to understand questions and retrieve information in multiple steps. We also developed LocalPlayground, a unified environment integrating multiple tools for agent interaction. Experiments show that even state-of-the-art LRMs struggle on LocalSearchBench: the best model (DeepSeek-V3.1) achieves only 34.34% correctness, and most models have issues with completeness (average 77.33%) and faithfulness (average 61.99%). This highlights the need for specialized benchmarks and domain-specific agent training in local life services. Code, Benchmark, and Leaderboard are available at localsearchbench.github.io.
From Experience to Strategy: Empowering LLM Agents with Trainable Graph Memory
Nov 11, 2025Large Language Models (LLMs) based agents have demonstrated remarkable potential in autonomous task-solving across complex, open-ended environments. A promising approach for improving the reasoning capabilities of LLM agents is to better utilize prior experiences in guiding current decisions. However, LLMs acquire experience either through implicit memory via training, which suffers from catastrophic forgetting and limited interpretability, or explicit memory via prompting, which lacks adaptability. In this paper, we introduce a novel agent-centric, trainable, multi-layered graph memory framework and evaluate how context memory enhances the ability of LLMs to utilize parametric information. The graph abstracts raw agent trajectories into structured decision paths in a state machine and further distills them into high-level, human-interpretable strategic meta-cognition. In order to make memory adaptable, we propose a reinforcement-based weight optimization procedure that estimates the empirical utility of each meta-cognition based on reward feedback from downstream tasks. These optimized strategies are then dynamically integrated into the LLM agent's training loop through meta-cognitive prompting. Empirically, the learnable graph memory delivers robust generalization, improves LLM agents' strategic reasoning performance, and provides consistent benefits during Reinforcement Learning (RL) training.
UniVA: Universal Video Agent towards Open-Source Next-Generation Video Generalist
Nov 11, 2025While specialized AI models excel at isolated video tasks like generation or understanding, real-world applications demand complex, iterative workflows that combine these capabilities. To bridge this gap, we introduce UniVA, an open-source, omni-capable multi-agent framework for next-generation video generalists that unifies video understanding, segmentation, editing, and generation into cohesive workflows. UniVA employs a Plan-and-Act dual-agent architecture that drives a highly automated and proactive workflow: a planner agent interprets user intentions and decomposes them into structured video-processing steps, while executor agents execute these through modular, MCP-based tool servers (for analysis, generation, editing, tracking, etc.). Through a hierarchical multi-level memory (global knowledge, task context, and user-specific preferences), UniVA sustains long-horizon reasoning, contextual continuity, and inter-agent communication, enabling interactive and self-reflective video creation with full traceability. This design enables iterative and any-conditioned video workflows (e.g., text/image/video-conditioned generation $\rightarrow$ multi-round editing $\rightarrow$ object segmentation $\rightarrow$ compositional synthesis) that were previously cumbersome to achieve with single-purpose models or monolithic video-language models. We also introduce UniVA-Bench, a benchmark suite of multi-step video tasks spanning understanding, editing, segmentation, and generation, to rigorously evaluate such agentic video systems. Both UniVA and UniVA-Bench are fully open-sourced, aiming to catalyze research on interactive, agentic, and general-purpose video intelligence for the next generation of multimodal AI systems. (https://univa.online/)
AccidentBench: Benchmarking Multimodal Understanding and Reasoning in Vehicle Accidents and Beyond
Sep 30, 2025Rapid advances in multimodal models demand benchmarks that rigorously evaluate understanding and reasoning in safety-critical, dynamic real-world settings. We present AccidentBench, a large-scale benchmark that combines vehicle accident scenarios with Beyond domains, safety-critical settings in air and water that emphasize spatial and temporal reasoning (e.g., navigation, orientation, multi-vehicle motion). The benchmark contains approximately 2000 videos and over 19000 human-annotated question--answer pairs spanning multiple video lengths (short/medium/long) and difficulty levels (easy/medium/hard). Tasks systematically probe core capabilities: temporal, spatial, and intent understanding and reasoning. By unifying accident-centric traffic scenes with broader safety-critical scenarios in air and water, AccidentBench offers a comprehensive, physically grounded testbed for evaluating models under real-world variability. Evaluations of state-of-the-art models (e.g., Gemini-2.5 Pro and GPT-5) show that even the strongest models achieve only about 18% accuracy on the hardest tasks and longest videos, revealing substantial gaps in real-world temporal, spatial, and intent reasoning. AccidentBench is designed to expose these critical gaps and drive the development of multimodal models that are safer, more robust, and better aligned with real-world safety-critical challenges. The code and dataset are available at: https://github.com/SafeRL-Lab/AccidentBench