 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Role of Depth in Surgical Vision Foundation Models: An Empirical Study of RGB-D Pre-training
Jan 26, 2026Vision foundation models (VFMs) have emerged as powerful tools for surgical scene understanding. However, current approaches predominantly rely on unimodal RGB pre-training, overlooking the complex 3D geometry inherent to surgical environments. Although several architectures support multimodal or geometry-aware inputs in general computer vision, the benefits of incorporating depth information in surgical settings remain underexplored. We conduct a large-scale empirical study comparing eight ViT-based VFMs that differ in pre-training domain, learning objective, and input modality (RGB vs. RGB-D). For pre-training, we use a curated dataset of 1.4 million robotic surgical images paired with depth maps generated from an off-the-shelf network. We evaluate these models under both frozen-backbone and end-to-end fine-tuning protocols across eight surgical datasets spanning object detection, segmentation, depth estimation, and pose estimation. Our experiments yield several consistent findings. Models incorporating explicit geometric tokenization, such as MultiMAE, substantially outperform unimodal baselines across all tasks. Notably, geometric-aware pre-training enables remarkable data efficiency: models fine-tuned on just 25% of labeled data consistently surpass RGB-only models trained on the full dataset. Importantly, these gains require no architectural or runtime changes at inference; depth is used only during pre-training, making adoption straightforward. These findings suggest that multimodal pre-training offers a viable path towards building more capable surgical vision systems.
Systematic Evaluation of Large Vision-Language Models for Surgical Artificial Intelligence
Apr 03, 2025Large Vision-Language Models offer a new paradigm for AI-driven image understanding, enabling models to perform tasks without task-specific training. This flexibility holds particular promise across medicine, where expert-annotated data is scarce. Yet, VLMs' practical utility in intervention-focused domains--especially surgery, where decision-making is subjective and clinical scenarios are variable--remains uncertain. Here, we present a comprehensive analysis of 11 state-of-the-art VLMs across 17 key visual understanding tasks in surgical AI--from anatomy recognition to skill assessment--using 13 datasets spanning laparoscopic, robotic, and open procedures. In our experiments, VLMs demonstrate promising generalizability, at times outperforming supervised models when deployed outside their training setting. In-context learning, incorporating examples during testing, boosted performance up to three-fold, suggesting adaptability as a key strength. Still, tasks requiring spatial or temporal reasoning remained difficult. Beyond surgery, our findings offer insights into VLMs' potential for tackling complex and dynamic scenarios in clinical and broader real-world applications.
Video Action Differencing
Mar 10, 2025How do two individuals differ when performing the same action? In this work, we introduce Video Action Differencing (VidDiff), the novel task of identifying subtle differences between videos of the same action, which has many applications, such as coaching and skill learning. To enable development on this new task, we first create VidDiffBench, a benchmark dataset containing 549 video pairs, with human annotations of 4,469 fine-grained action differences and 2,075 localization timestamps indicating where these differences occur. Our experiments demonstrate that VidDiffBench poses a significant challenge for state-of-the-art large multimodal models (LMMs), such as GPT-4o and Qwen2-VL. By analyzing failure cases of LMMs on VidDiffBench, we highlight two key challenges for this task: localizing relevant sub-actions over two videos and fine-grained frame comparison. To overcome these, we propose the VidDiff method, an agentic workflow that breaks the task into three stages: action difference proposal, keyframe localization, and frame differencing, each stage utilizing specialized foundation models. To encourage future research in this new task, we release the benchmark at https://huggingface.co/datasets/jmhb/VidDiffBench and code at http://jmhb0.github.io/viddiff.
BIOMEDICA: An Open Biomedical Image-Caption Archive, Dataset, and Vision-Language Models Derived from Scientific Literature
Jan 14, 2025The development of vision-language models (VLMs) is driven by large-scale and diverse multimodal datasets. However, progress toward generalist biomedical VLMs is limited by the lack of annotated, publicly accessible datasets across biology and medicine. Existing efforts are restricted to narrow domains, missing the full diversity of biomedical knowledge encoded in scientific literature. To address this gap, we introduce BIOMEDICA, a scalable, open-source framework to extract, annotate, and serialize the entirety of the PubMed Central Open Access subset into an easy-to-use, publicly accessible dataset. Our framework produces a comprehensive archive with over 24 million unique image-text pairs from over 6 million articles. Metadata and expert-guided annotations are also provided. We demonstrate the utility and accessibility of our resource by releasing BMCA-CLIP, a suite of CLIP-style models continuously pre-trained on the BIOMEDICA dataset via streaming, eliminating the need to download 27 TB of data locally. On average, our models achieve state-of-the-art performance across 40 tasks - spanning pathology, radiology, ophthalmology, dermatology, surgery, molecular biology, parasitology, and cell biology - excelling in zero-shot classification with a 6.56% average improvement (as high as 29.8% and 17.5% in dermatology and ophthalmology, respectively), and stronger image-text retrieval, all while using 10x less compute. To foster reproducibility and collaboration, we release our codebase and dataset for the broader research community.
Depth-guided NeRF Training via Earth Mover's Distance
Mar 19, 2024



Neural Radiance Fields (NeRFs) are trained to minimize the rendering loss of predicted viewpoints. However, the photometric loss often does not provide enough information to disambiguate between different possible geometries yielding the same image. Previous work has thus incorporated depth supervision during NeRF training, leveraging dense predictions from pre-trained depth networks as pseudo-ground truth. While these depth priors are assumed to be perfect once filtered for noise, in practice, their accuracy is more challenging to capture. This work proposes a novel approach to uncertainty in depth priors for NeRF supervision. Instead of using custom-trained depth or uncertainty priors, we use off-the-shelf pretrained diffusion models to predict depth and capture uncertainty during the denoising process. Because we know that depth priors are prone to errors, we propose to supervise the ray termination distance distribution with Earth Mover's Distance instead of enforcing the rendered depth to replicate the depth prior exactly through L2-loss. Our depth-guided NeRF outperforms all baselines on standard depth metrics by a large margin while maintaining performance on photometric measures.
Task-guided Domain Gap Reduction for Monocular Depth Prediction in Endoscopy
Oct 02, 2023Colorectal cancer remains one of the deadliest cancers in the world. In recent years computer-aided methods have aimed to enhance cancer screening and improve the quality and availability of colonoscopies by automatizing sub-tasks. One such task is predicting depth from monocular video frames, which can assist endoscopic navigation. As ground truth depth from standard in-vivo colonoscopy remains unobtainable due to hardware constraints, two approaches have aimed to circumvent the need for real training data: supervised methods trained on labeled synthetic data and self-supervised models trained on unlabeled real data. However, self-supervised methods depend on unreliable loss functions that struggle with edges, self-occlusion, and lighting inconsistency. Methods trained on synthetic data can provide accurate depth for synthetic geometries but do not use any geometric supervisory signal from real data and overfit to synthetic anatomies and properties. This work proposes a novel approach to leverage labeled synthetic and unlabeled real data. While previous domain adaptation methods indiscriminately enforce the distributions of both input data modalities to coincide, we focus on the end task, depth prediction, and translate only essential information between the input domains. Our approach results in more resilient and accurate depth maps of real colonoscopy sequences.
* First Data Engineering in Medical Imaging Workshop at MICCAI 2023
SimCol3D -- 3D Reconstruction during Colonoscopy Challenge
Jul 20, 2023Colorectal cancer is one of the most common cancers in the world. While colonoscopy is an effective screening technique, navigating an endoscope through the colon to detect polyps is challenging. A 3D map of the observed surfaces could enhance the identification of unscreened colon tissue and serve as a training platform. However, reconstructing the colon from video footage remains unsolved due to numerous factors such as self-occlusion, reflective surfaces, lack of texture, and tissue deformation that limit feature-based methods. Learning-based approaches hold promise as robust alternatives, but necessitate extensive datasets. By establishing a benchmark, the 2022 EndoVis sub-challenge SimCol3D aimed to facilitate data-driven depth and pose prediction during colonoscopy. The challenge was hosted as part of MICCAI 2022 in Singapore. Six teams from around the world and representatives from academia and industry participated in the three sub-challenges: synthetic depth prediction, synthetic pose prediction, and real pose prediction. This paper describes the challenge, the submitted methods, and their results. We show that depth prediction in virtual colonoscopy is robustly solvable, while pose estimation remains an open research question.
Bimodal Camera Pose Prediction for Endoscopy
Apr 11, 2022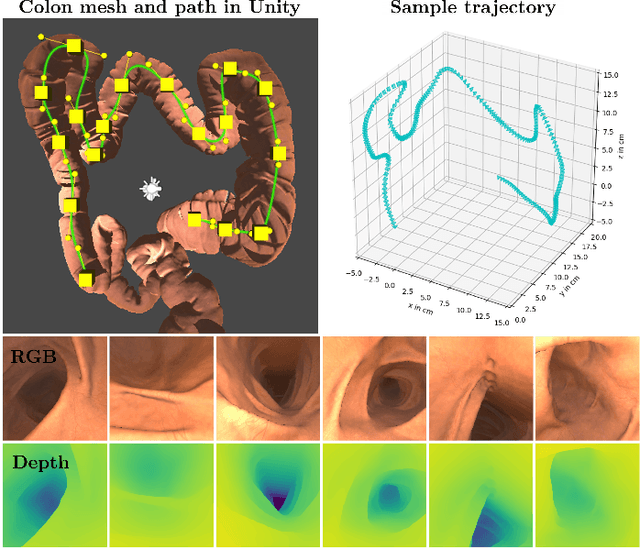
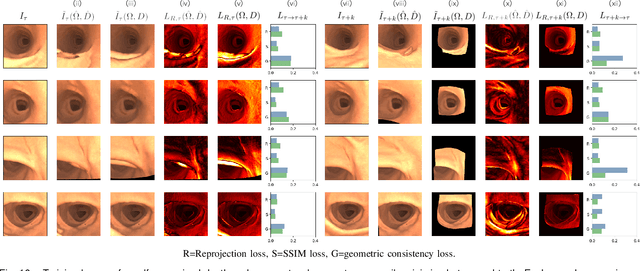
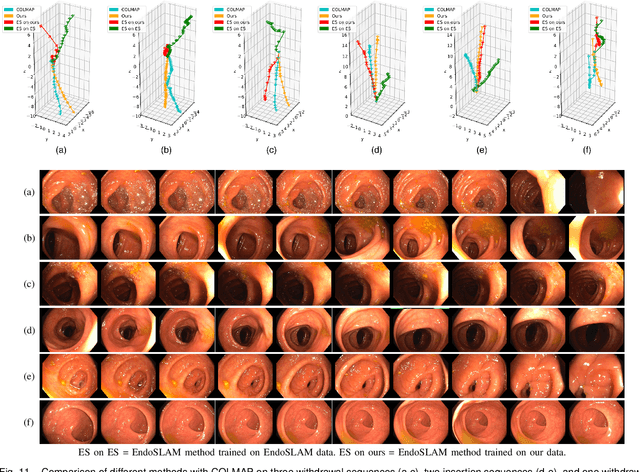
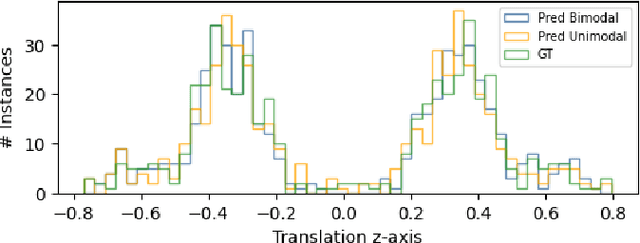
Deducing the 3D structure of endoscopic scenes from images remains extremely challenging. In addition to deformation and view-dependent lighting, tubular structures like the colon present problems stemming from the self-occluding, repetitive anatomical structures. In this paper, we propose SimCol, a synthetic dataset for camera pose estimation in colonoscopy and a novel method that explicitly learns a bimodal distribution to predict the endoscope pose. Our dataset replicates real colonoscope motion and highlights drawbacks of existing methods. We publish 18k RGB images from simulated colonoscopy with corresponding depth and camera poses and make our data generation environment in Unity publicly available. We evaluate different camera pose prediction methods and demonstrate that, when trained on our data, they generalize to real colonoscopy sequences and our bimodal approach outperforms prior unimodal work.
Predicting Visual Overlap of Images Through Interpretable Non-Metric Box Embeddings
Aug 13, 2020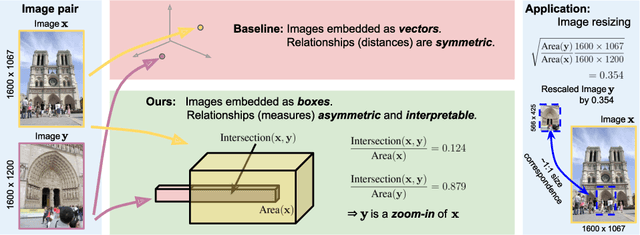
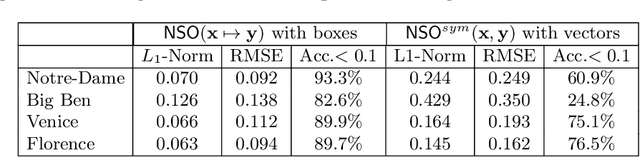

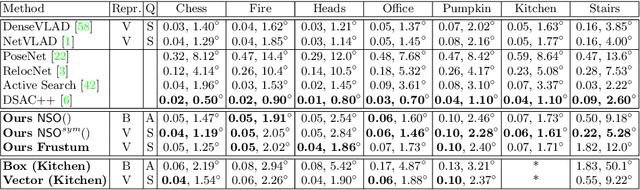
To what extent are two images picturing the same 3D surfaces? Even when this is a known scene, the answer typically requires an expensive search across scale space, with matching and geometric verification of large sets of local features. This expense is further multiplied when a query image is evaluated against a gallery, e.g. in visual relocalization. While we don't obviate the need for geometric verification, we propose an interpretable image-embedding that cuts the search in scale space to essentially a lookup. Our approach measures the asymmetric relation between two images. The model then learns a scene-specific measure of similarity, from training examples with known 3D visible-surface overlaps. The result is that we can quickly identify, for example, which test image is a close-up version of another, and by what scale factor. Subsequently, local features need only be detected at that scale. We validate our scene-specific model by showing how this embedding yields competitive image-matching results, while being simpler, faster, and also interpretable by humans.