 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystematic Evaluation of Large Vision-Language Models for Surgical Artificial Intelligence
Apr 03, 2025Large Vision-Language Models offer a new paradigm for AI-driven image understanding, enabling models to perform tasks without task-specific training. This flexibility holds particular promise across medicine, where expert-annotated data is scarce. Yet, VLMs' practical utility in intervention-focused domains--especially surgery, where decision-making is subjective and clinical scenarios are variable--remains uncertain. Here, we present a comprehensive analysis of 11 state-of-the-art VLMs across 17 key visual understanding tasks in surgical AI--from anatomy recognition to skill assessment--using 13 datasets spanning laparoscopic, robotic, and open procedures. In our experiments, VLMs demonstrate promising generalizability, at times outperforming supervised models when deployed outside their training setting. In-context learning, incorporating examples during testing, boosted performance up to three-fold, suggesting adaptability as a key strength. Still, tasks requiring spatial or temporal reasoning remained difficult. Beyond surgery, our findings offer insights into VLMs' potential for tackling complex and dynamic scenarios in clinical and broader real-world applications.
Revisiting MAE pre-training for 3D medical image segmentation
Oct 30, 2024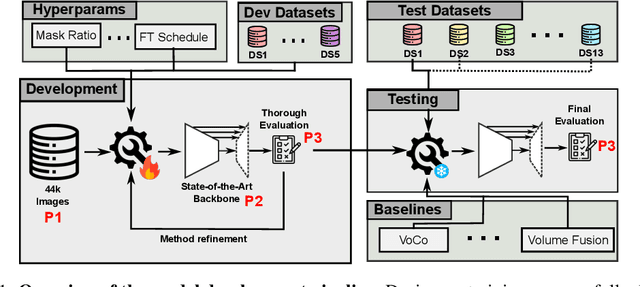
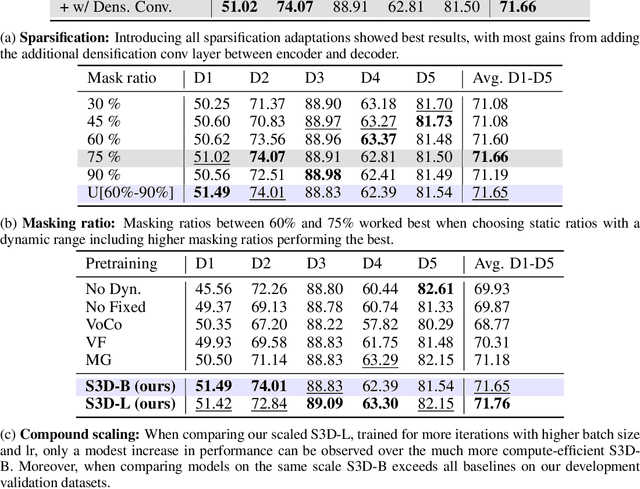
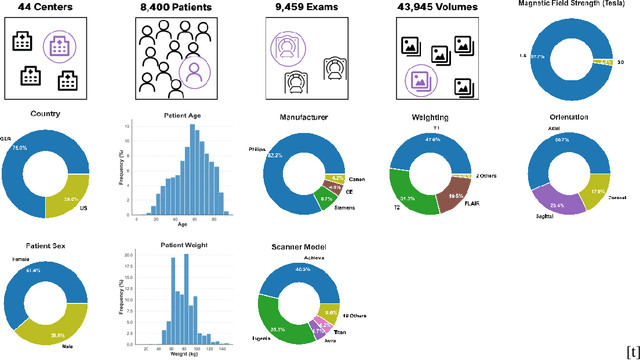
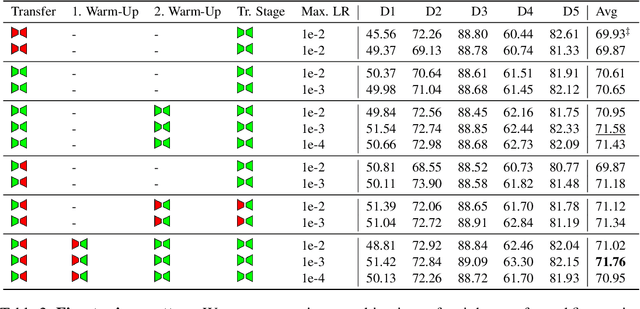
Self-Supervised Learning (SSL) presents an exciting opportunity to unlock the potential of vast, untapped clinical datasets, for various downstream applications that suffer from the scarcity of labeled data. While SSL has revolutionized fields like natural language processing and computer vision, their adoption in 3D medical image computing has been limited by three key pitfalls: Small pre-training dataset sizes, architectures inadequate for 3D medical image analysis, and insufficient evaluation practices. We address these issues by i) leveraging a large-scale dataset of 44k 3D brain MRI volumes and ii) using a Residual Encoder U-Net architecture within the state-of-the-art nnU-Net framework. iii) A robust development framework, incorporating 5 development and 8 testing brain MRI segmentation datasets, allowed performance-driven design decisions to optimize the simple concept of Masked Auto Encoders (MAEs) for 3D CNNs. The resulting model not only surpasses previous SSL methods but also outperforms the strong nnU-Net baseline by an average of approximately 3 Dice points. Furthermore, our model demonstrates exceptional stability, achieving the highest average rank of 2 out of 7 methods, compared to the second-best method's mean rank of 3.