 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo VLMs Perceive or Recall? Probing Visual Perception vs. Memory with Classic Visual Illusions
Jan 29, 2026Large Vision-Language Models (VLMs) often answer classic visual illusions "correctly" on original images, yet persist with the same responses when illusion factors are inverted, even though the visual change is obvious to humans. This raises a fundamental question: do VLMs perceive visual changes or merely recall memorized patterns? While several studies have noted this phenomenon, the underlying causes remain unclear. To move from observations to systematic understanding, this paper introduces VI-Probe, a controllable visual-illusion framework with graded perturbations and matched visual controls (without illusion inducer) that disentangles visually grounded perception from language-driven recall. Unlike prior work that focuses on averaged accuracy, we measure stability and sensitivity using Polarity-Flip Consistency, Template Fixation Index, and an illusion multiplier normalized against matched controls. Experiments across different families reveal that response persistence arises from heterogeneous causes rather than a single mechanism. For instance, GPT-5 exhibits memory override, Claude-Opus-4.1 shows perception-memory competition, while Qwen variants suggest visual-processing limits. Our findings challenge single-cause views and motivate probing-based evaluation that measures both knowledge and sensitivity to controlled visual change. Data and code are available at https://sites.google.com/view/vi-probe/.
Systematic Evaluation of Large Vision-Language Models for Surgical Artificial Intelligence
Apr 03, 2025Large Vision-Language Models offer a new paradigm for AI-driven image understanding, enabling models to perform tasks without task-specific training. This flexibility holds particular promise across medicine, where expert-annotated data is scarce. Yet, VLMs' practical utility in intervention-focused domains--especially surgery, where decision-making is subjective and clinical scenarios are variable--remains uncertain. Here, we present a comprehensive analysis of 11 state-of-the-art VLMs across 17 key visual understanding tasks in surgical AI--from anatomy recognition to skill assessment--using 13 datasets spanning laparoscopic, robotic, and open procedures. In our experiments, VLMs demonstrate promising generalizability, at times outperforming supervised models when deployed outside their training setting. In-context learning, incorporating examples during testing, boosted performance up to three-fold, suggesting adaptability as a key strength. Still, tasks requiring spatial or temporal reasoning remained difficult. Beyond surgery, our findings offer insights into VLMs' potential for tackling complex and dynamic scenarios in clinical and broader real-world applications.
Feather the Throttle: Revisiting Visual Token Pruning for Vision-Language Model Acceleration
Dec 17, 2024Recent works on accelerating Vision-Language Models show that strong performance can be maintained across a variety of vision-language tasks despite highly compressing visual information. In this work, we examine the popular acceleration approach of early pruning of visual tokens inside the language model and find that its strong performance across many tasks is not due to an exceptional ability to compress visual information, but rather the benchmarks' limited ability to assess fine-grained visual capabilities. Namely, we demonstrate a core issue with the acceleration approach where most tokens towards the top of the image are pruned away. Yet, this issue is only reflected in performance for a small subset of tasks such as localization. For the other evaluated tasks, strong performance is maintained with the flawed pruning strategy. Noting the limited visual capabilities of the studied acceleration technique, we propose FEATHER (Fast and Effective Acceleration wiTH Ensemble cRiteria), a straightforward approach that (1) resolves the identified issue with early-layer pruning, (2) incorporates uniform sampling to ensure coverage across all image regions, and (3) applies pruning in two stages to allow the criteria to become more effective at a later layer while still achieving significant speedup through early-layer pruning. With comparable computational savings, we find that FEATHER has more than $5\times$ performance improvement on the vision-centric localization benchmarks compared to the original acceleration approach.
Motion Question Answering via Modular Motion Programs
May 17, 2023

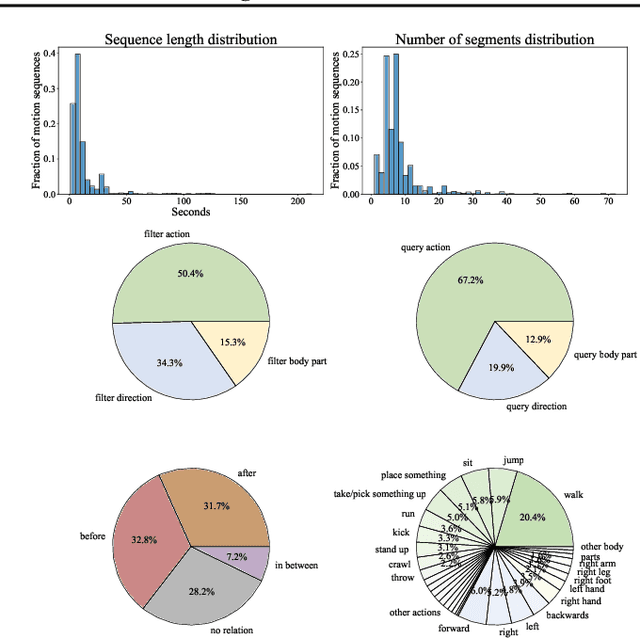

In order to build artificial intelligence systems that can perceive and reason with human behavior in the real world, we must first design models that conduct complex spatio-temporal reasoning over motion sequences. Moving towards this goal, we propose the HumanMotionQA task to evaluate complex, multi-step reasoning abilities of models on long-form human motion sequences. We generate a dataset of question-answer pairs that require detecting motor cues in small portions of motion sequences, reasoning temporally about when events occur, and querying specific motion attributes. In addition, we propose NSPose, a neuro-symbolic method for this task that uses symbolic reasoning and a modular design to ground motion through learning motion concepts, attribute neural operators, and temporal relations. We demonstrate the suitability of NSPose for the HumanMotionQA task, outperforming all baseline methods.
GaitForeMer: Self-Supervised Pre-Training of Transformers via Human Motion Forecasting for Few-Shot Gait Impairment Severity Estimation
Jun 30, 2022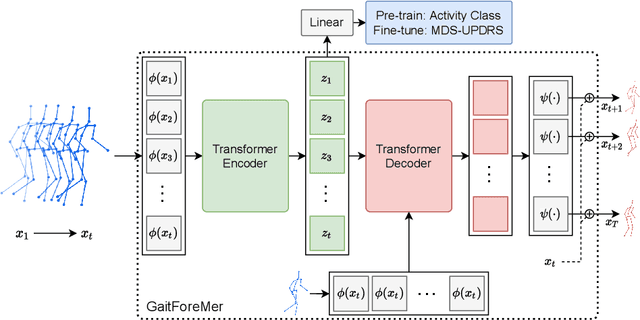


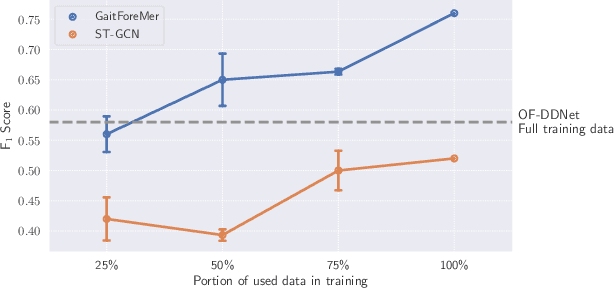
Parkinson's disease (PD) is a neurological disorder that has a variety of observable motor-related symptoms such as slow movement, tremor, muscular rigidity, and impaired posture. PD is typically diagnosed by evaluating the severity of motor impairments according to scoring systems such as the Movement Disorder Society Unified Parkinson's Disease Rating Scale (MDS-UPDRS). Automated severity prediction using video recordings of individuals provides a promising route for non-intrusive monitoring of motor impairments. However, the limited size of PD gait data hinders model ability and clinical potential. Because of this clinical data scarcity and inspired by the recent advances in self-supervised large-scale language models like GPT-3, we use human motion forecasting as an effective self-supervised pre-training task for the estimation of motor impairment severity. We introduce GaitForeMer, Gait Forecasting and impairment estimation transforMer, which is first pre-trained on public datasets to forecast gait movements and then applied to clinical data to predict MDS-UPDRS gait impairment severity. Our method outperforms previous approaches that rely solely on clinical data by a large margin, achieving an F1 score of 0.76, precision of 0.79, and recall of 0.75. Using GaitForeMer, we show how public human movement data repositories can assist clinical use cases through learning universal motion representations. The code is available at https://github.com/markendo/GaitForeMer .
CheXseg: Combining Expert Annotations with DNN-generated Saliency Maps for X-ray Segmentation
Feb 21, 2021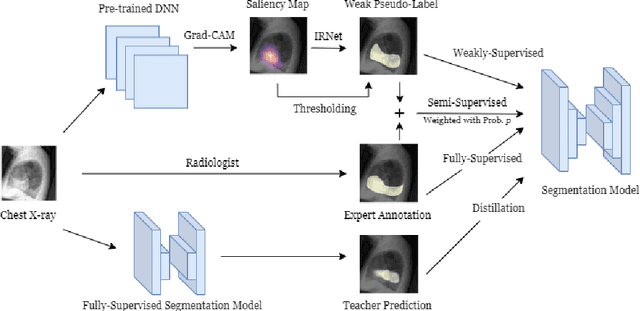
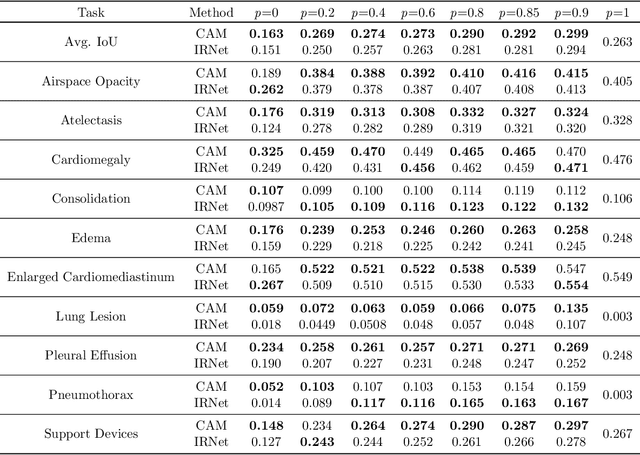
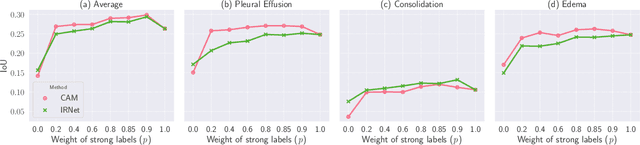
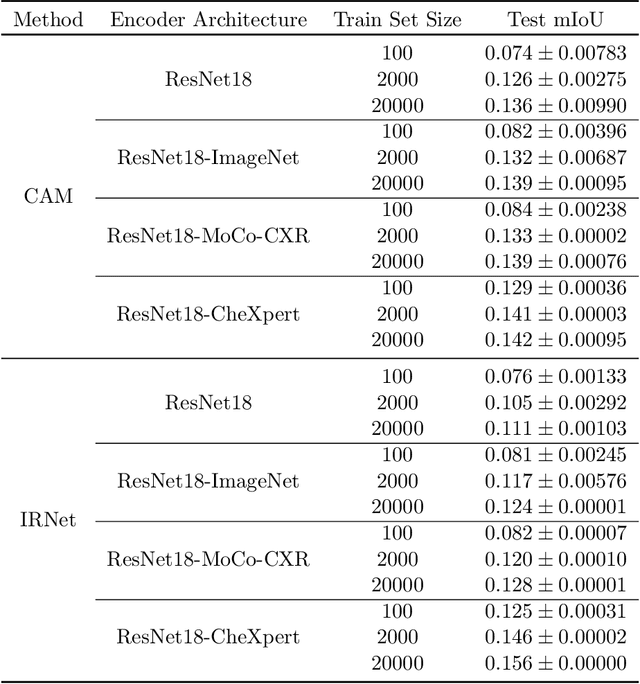
Medical image segmentation models are typically supervised by expert annotations at the pixel-level, which can be expensive to acquire. In this work, we propose a method that combines the high quality of pixel-level expert annotations with the scale of coarse DNN-generated saliency maps for training multi-label semantic segmentation models. We demonstrate the application of our semi-supervised method, which we call CheXseg, on multi-label chest x-ray interpretation. We find that CheXseg improves upon the performance (mIoU) of fully-supervised methods that use only pixel-level expert annotations by 13.4% and weakly-supervised methods that use only DNN-generated saliency maps by 91.2%. Furthermore, we implement a semi-supervised method using knowledge distillation and find that though it is outperformed by CheXseg, it exceeds the performance (mIoU) of the best fully-supervised method by 4.83%. Our best method is able to match radiologist agreement on three out of ten pathologies and reduces the overall performance gap by 71.6% as compared to weakly-supervised methods.