 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyLift: Scaling Motion Reconstruction from Internet Videos via 2D Diffusion
Apr 20, 2026Reconstructing 3D human motion and human-object interactions (HOI) from Internet videos is a fundamental step toward building large-scale datasets of human behavior. Existing methods struggle to recover globally consistent 3D motion under dynamic cameras, especially for motion types underrepresented in current motion-capture datasets, and face additional difficulty recovering coherent human-object interactions in 3D. We introduce a two-stage framework leveraging 2D diffusion that reconstructs 3D human motion and HOI from Internet videos. In the first stage, we synthesize multi-view 2D motion data for each domain, leveraging 2D keypoints extracted from Internet videos to incorporate human motions that rarely appear in existing MoCap datasets. In the second stage, a camera-conditioned multi-view 2D motion diffusion model is trained on the domain-specific synthetic data to recover 3D human motion and 3D HOI in the world space. We demonstrate the effectiveness of our method on Internet videos featuring challenging motions such as gymnastics, as well as in-the-wild HOI videos, and show that it outperforms prior work in producing realistic human motion and human-object interaction.
WHOLE: World-Grounded Hand-Object Lifted from Egocentric Videos
Feb 25, 2026Egocentric manipulation videos are highly challenging due to severe occlusions during interactions and frequent object entries and exits from the camera view as the person moves. Current methods typically focus on recovering either hand or object pose in isolation, but both struggle during interactions and fail to handle out-of-sight cases. Moreover, their independent predictions often lead to inconsistent hand-object relations. We introduce WHOLE, a method that holistically reconstructs hand and object motion in world space from egocentric videos given object templates. Our key insight is to learn a generative prior over hand-object motion to jointly reason about their interactions. At test time, the pretrained prior is guided to generate trajectories that conform to the video observations. This joint generative reconstruction substantially outperforms approaches that process hands and objects separately followed by post-processing. WHOLE achieves state-of-the-art performance on hand motion estimation, 6D object pose estimation, and their relative interaction reconstruction. Project website: https://judyye.github.io/whole-www
ZeroHSI: Zero-Shot 4D Human-Scene Interaction by Video Generation
Dec 24, 2024Human-scene interaction (HSI) generation is crucial for applications in embodied AI, virtual reality, and robotics. While existing methods can synthesize realistic human motions in 3D scenes and generate plausible human-object interactions, they heavily rely on datasets containing paired 3D scene and motion capture data, which are expensive and time-consuming to collect across diverse environments and interactions. We present ZeroHSI, a novel approach that enables zero-shot 4D human-scene interaction synthesis by integrating video generation and neural human rendering. Our key insight is to leverage the rich motion priors learned by state-of-the-art video generation models, which have been trained on vast amounts of natural human movements and interactions, and use differentiable rendering to reconstruct human-scene interactions. ZeroHSI can synthesize realistic human motions in both static scenes and environments with dynamic objects, without requiring any ground-truth motion data. We evaluate ZeroHSI on a curated dataset of different types of various indoor and outdoor scenes with different interaction prompts, demonstrating its ability to generate diverse and contextually appropriate human-scene interactions.
Lifting Motion to the 3D World via 2D Diffusion
Nov 27, 2024Estimating 3D motion from 2D observations is a long-standing research challenge. Prior work typically requires training on datasets containing ground truth 3D motions, limiting their applicability to activities well-represented in existing motion capture data. This dependency particularly hinders generalization to out-of-distribution scenarios or subjects where collecting 3D ground truth is challenging, such as complex athletic movements or animal motion. We introduce MVLift, a novel approach to predict global 3D motion -- including both joint rotations and root trajectories in the world coordinate system -- using only 2D pose sequences for training. Our multi-stage framework leverages 2D motion diffusion models to progressively generate consistent 2D pose sequences across multiple views, a key step in recovering accurate global 3D motion. MVLift generalizes across various domains, including human poses, human-object interactions, and animal poses. Despite not requiring 3D supervision, it outperforms prior work on five datasets, including those methods that require 3D supervision.
Human-Object Interaction from Human-Level Instructions
Jun 25, 2024
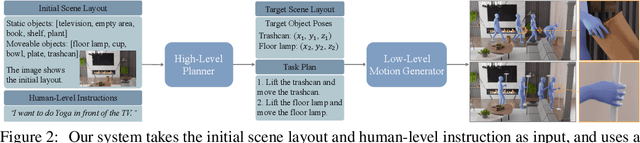
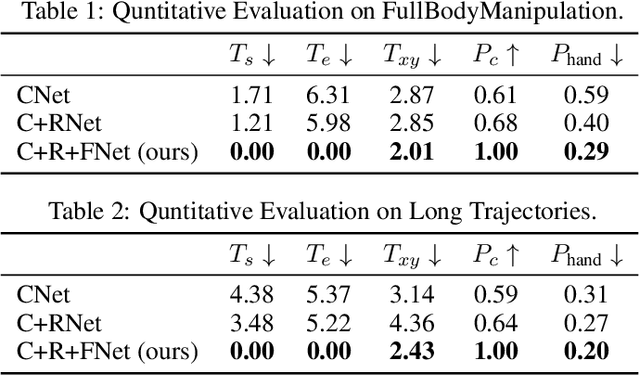
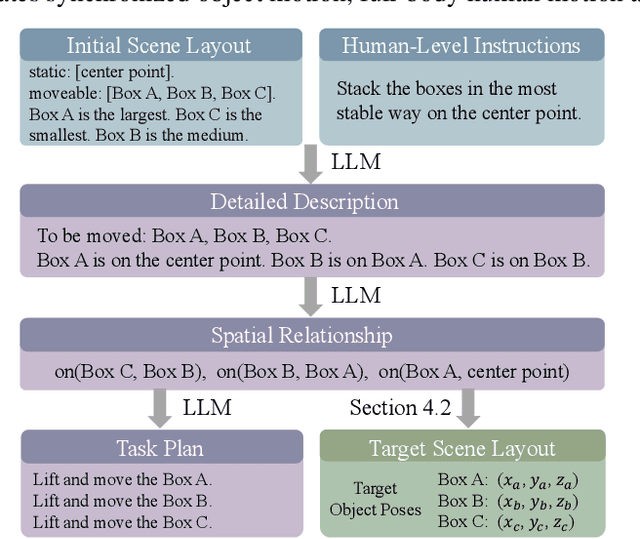
Intelligent agents need to autonomously navigate and interact within contextual environments to perform a wide range of daily tasks based on human-level instructions. These agents require a foundational understanding of the world, incorporating common sense and knowledge, to interpret such instructions. Moreover, they must possess precise low-level skills for movement and interaction to execute the detailed task plans derived from these instructions. In this work, we address the task of synthesizing continuous human-object interactions for manipulating large objects within contextual environments, guided by human-level instructions. Our goal is to generate synchronized object motion, full-body human motion, and detailed finger motion, all essential for realistic interactions. Our framework consists of a large language model (LLM) planning module and a low-level motion generator. We use LLMs to deduce spatial object relationships and devise a method for accurately determining their positions and orientations in target scene layouts. Additionally, the LLM planner outlines a detailed task plan specifying a sequence of sub-tasks. This task plan, along with the target object poses, serves as input for our low-level motion generator, which seamlessly alternates between navigation and interaction modules. We present the first complete system that can synthesize object motion, full-body motion, and finger motion simultaneously from human-level instructions. Our experiments demonstrate the effectiveness of our high-level planner in generating plausible target layouts and our low-level motion generator in synthesizing realistic interactions for diverse objects. Please refer to our project page for more results: https://hoifhli.github.io/.
Controllable Human-Object Interaction Synthesis
Dec 06, 2023
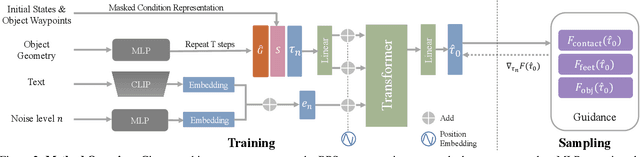
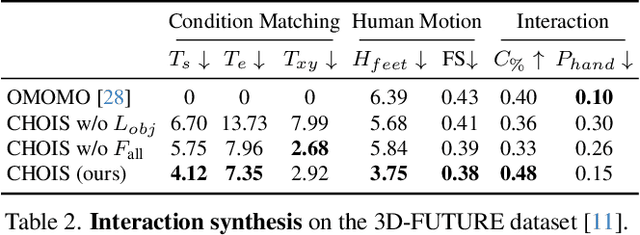
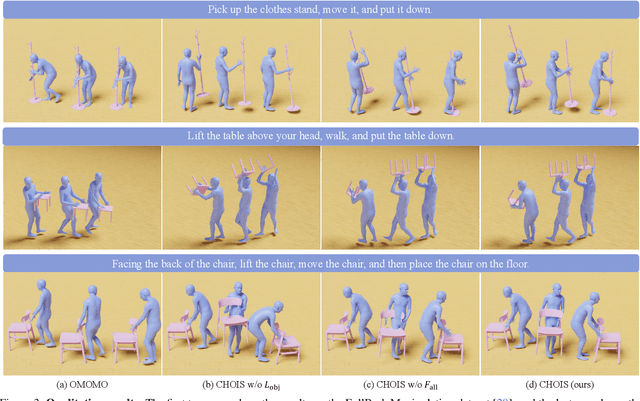
Synthesizing semantic-aware, long-horizon, human-object interaction is critical to simulate realistic human behaviors. In this work, we address the challenging problem of generating synchronized object motion and human motion guided by language descriptions in 3D scenes. We propose Controllable Human-Object Interaction Synthesis (CHOIS), an approach that generates object motion and human motion simultaneously using a conditional diffusion model given a language description, initial object and human states, and sparse object waypoints. While language descriptions inform style and intent, waypoints ground the motion in the scene and can be effectively extracted using high-level planning methods. Naively applying a diffusion model fails to predict object motion aligned with the input waypoints and cannot ensure the realism of interactions that require precise hand-object contact and appropriate contact grounded by the floor. To overcome these problems, we introduce an object geometry loss as additional supervision to improve the matching between generated object motion and input object waypoints. In addition, we design guidance terms to enforce contact constraints during the sampling process of the trained diffusion model.
Object Motion Guided Human Motion Synthesis
Sep 28, 2023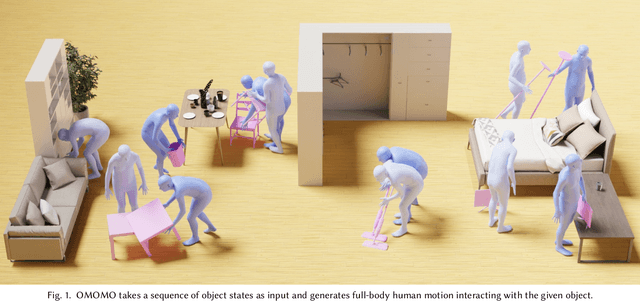

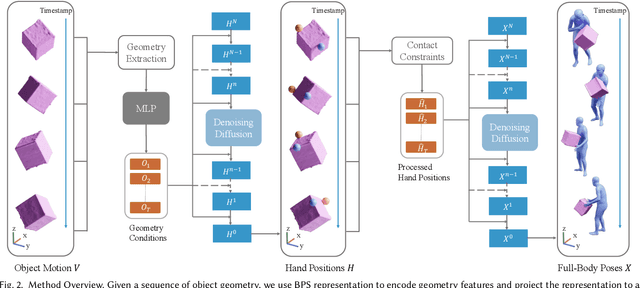

Modeling human behaviors in contextual environments has a wide range of applications in character animation, embodied AI, VR/AR, and robotics. In real-world scenarios, humans frequently interact with the environment and manipulate various objects to complete daily tasks. In this work, we study the problem of full-body human motion synthesis for the manipulation of large-sized objects. We propose Object MOtion guided human MOtion synthesis (OMOMO), a conditional diffusion framework that can generate full-body manipulation behaviors from only the object motion. Since naively applying diffusion models fails to precisely enforce contact constraints between the hands and the object, OMOMO learns two separate denoising processes to first predict hand positions from object motion and subsequently synthesize full-body poses based on the predicted hand positions. By employing the hand positions as an intermediate representation between the two denoising processes, we can explicitly enforce contact constraints, resulting in more physically plausible manipulation motions. With the learned model, we develop a novel system that captures full-body human manipulation motions by simply attaching a smartphone to the object being manipulated. Through extensive experiments, we demonstrate the effectiveness of our proposed pipeline and its ability to generalize to unseen objects. Additionally, as high-quality human-object interaction datasets are scarce, we collect a large-scale dataset consisting of 3D object geometry, object motion, and human motion. Our dataset contains human-object interaction motion for 15 objects, with a total duration of approximately 10 hours.
Motion Question Answering via Modular Motion Programs
May 17, 2023

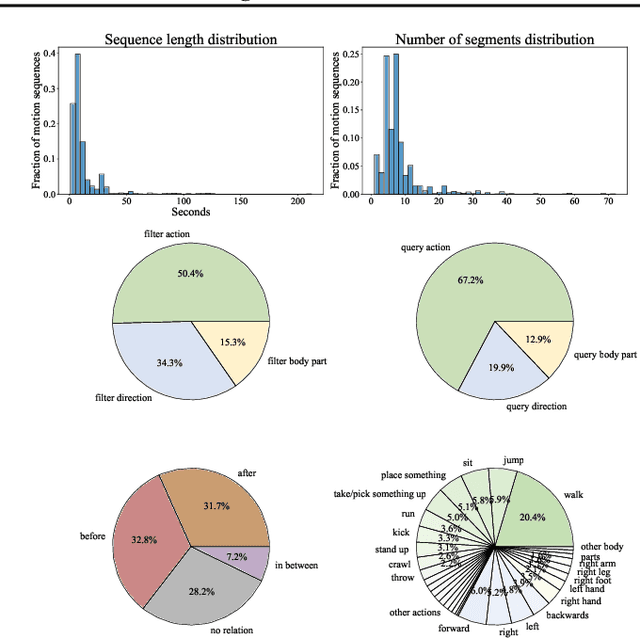

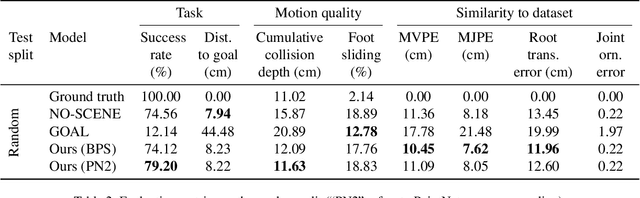
In order to build artificial intelligence systems that can perceive and reason with human behavior in the real world, we must first design models that conduct complex spatio-temporal reasoning over motion sequences. Moving towards this goal, we propose the HumanMotionQA task to evaluate complex, multi-step reasoning abilities of models on long-form human motion sequences. We generate a dataset of question-answer pairs that require detecting motor cues in small portions of motion sequences, reasoning temporally about when events occur, and querying specific motion attributes. In addition, we propose NSPose, a neuro-symbolic method for this task that uses symbolic reasoning and a modular design to ground motion through learning motion concepts, attribute neural operators, and temporal relations. We demonstrate the suitability of NSPose for the HumanMotionQA task, outperforming all baseline methods.
CIRCLE: Capture In Rich Contextual Environments
Mar 31, 2023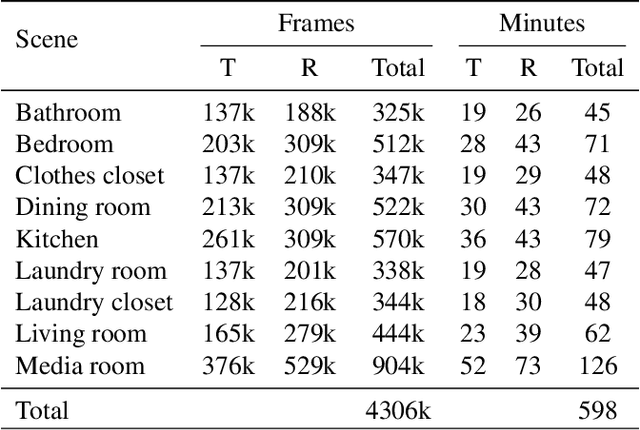
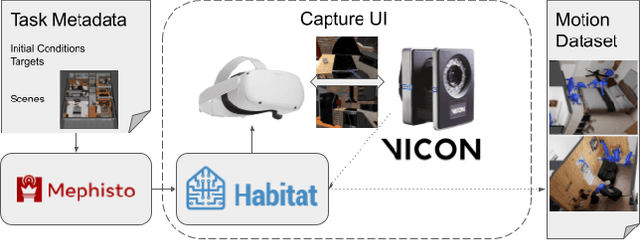

Synthesizing 3D human motion in a contextual, ecological environment is important for simulating realistic activities people perform in the real world. However, conventional optics-based motion capture systems are not suited for simultaneously capturing human movements and complex scenes. The lack of rich contextual 3D human motion datasets presents a roadblock to creating high-quality generative human motion models. We propose a novel motion acquisition system in which the actor perceives and operates in a highly contextual virtual world while being motion captured in the real world. Our system enables rapid collection of high-quality human motion in highly diverse scenes, without the concern of occlusion or the need for physical scene construction in the real world. We present CIRCLE, a dataset containing 10 hours of full-body reaching motion from 5 subjects across nine scenes, paired with ego-centric information of the environment represented in various forms, such as RGBD videos. We use this dataset to train a model that generates human motion conditioned on scene information. Leveraging our dataset, the model learns to use ego-centric scene information to achieve nontrivial reaching tasks in the context of complex 3D scenes. To download the data please visit https://stanford-tml.github.io/circle_dataset/.
Scene Synthesis from Human Motion
Jan 04, 2023Large-scale capture of human motion with diverse, complex scenes, while immensely useful, is often considered prohibitively costly. Meanwhile, human motion alone contains rich information about the scene they reside in and interact with. For example, a sitting human suggests the existence of a chair, and their leg position further implies the chair's pose. In this paper, we propose to synthesize diverse, semantically reasonable, and physically plausible scenes based on human motion. Our framework, Scene Synthesis from HUMan MotiON (SUMMON), includes two steps. It first uses ContactFormer, our newly introduced contact predictor, to obtain temporally consistent contact labels from human motion. Based on these predictions, SUMMON then chooses interacting objects and optimizes physical plausibility losses; it further populates the scene with objects that do not interact with humans. Experimental results demonstrate that SUMMON synthesizes feasible, plausible, and diverse scenes and has the potential to generate extensive human-scene interaction data for the community.