 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Object Interaction from Human-Level Instructions
Paper and Code

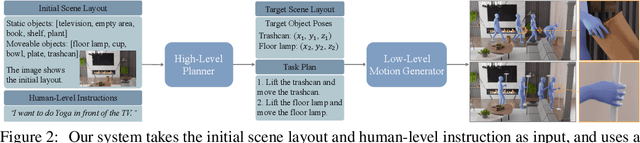
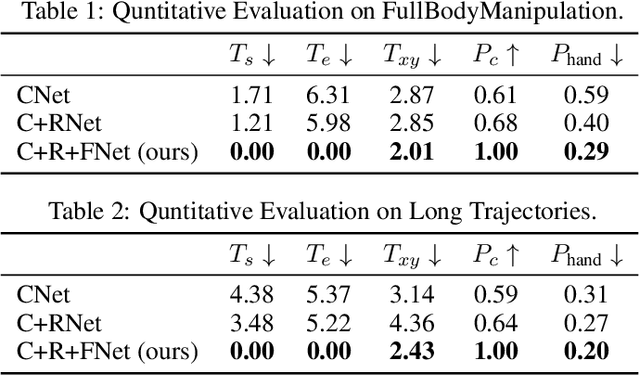
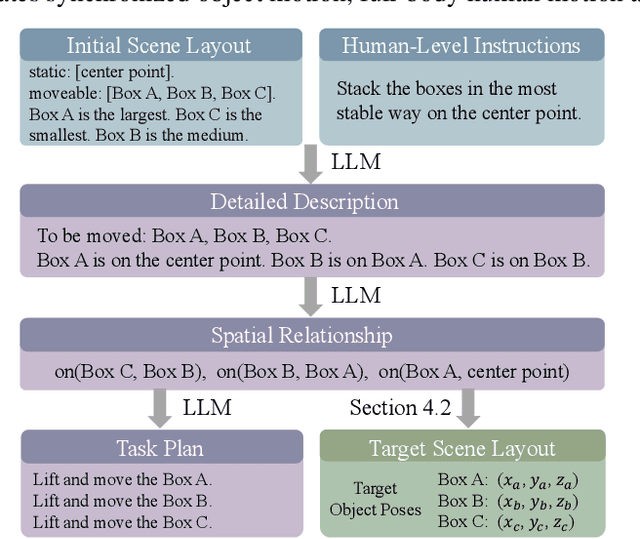
Intelligent agents need to autonomously navigate and interact within contextual environments to perform a wide range of daily tasks based on human-level instructions. These agents require a foundational understanding of the world, incorporating common sense and knowledge, to interpret such instructions. Moreover, they must possess precise low-level skills for movement and interaction to execute the detailed task plans derived from these instructions. In this work, we address the task of synthesizing continuous human-object interactions for manipulating large objects within contextual environments, guided by human-level instructions. Our goal is to generate synchronized object motion, full-body human motion, and detailed finger motion, all essential for realistic interactions. Our framework consists of a large language model (LLM) planning module and a low-level motion generator. We use LLMs to deduce spatial object relationships and devise a method for accurately determining their positions and orientations in target scene layouts. Additionally, the LLM planner outlines a detailed task plan specifying a sequence of sub-tasks. This task plan, along with the target object poses, serves as input for our low-level motion generator, which seamlessly alternates between navigation and interaction modules. We present the first complete system that can synthesize object motion, full-body motion, and finger motion simultaneously from human-level instructions. Our experiments demonstrate the effectiveness of our high-level planner in generating plausible target layouts and our low-level motion generator in synthesizing realistic interactions for diverse objects. Please refer to our project page for more results: https://hoifhli.github.io/.