 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocomotion Beyond Feet
Jan 07, 2026Most locomotion methods for humanoid robots focus on leg-based gaits, yet natural bipeds frequently rely on hands, knees, and elbows to establish additional contacts for stability and support in complex environments. This paper introduces Locomotion Beyond Feet, a comprehensive system for whole-body humanoid locomotion across extremely challenging terrains, including low-clearance spaces under chairs, knee-high walls, knee-high platforms, and steep ascending and descending stairs. Our approach addresses two key challenges: contact-rich motion planning and generalization across diverse terrains. To this end, we combine physics-grounded keyframe animation with reinforcement learning. Keyframes encode human knowledge of motor skills, are embodiment-specific, and can be readily validated in simulation or on hardware, while reinforcement learning transforms these references into robust, physically accurate motions. We further employ a hierarchical framework consisting of terrain-specific motion-tracking policies, failure recovery mechanisms, and a vision-based skill planner. Real-world experiments demonstrate that Locomotion Beyond Feet achieves robust whole-body locomotion and generalizes across obstacle sizes, obstacle instances, and terrain sequences.
Persona-Aware Alignment Framework for Personalized Dialogue Generation
Nov 13, 2025Personalized dialogue generation aims to leverage persona profiles and dialogue history to generate persona-relevant and consistent responses. Mainstream models typically rely on token-level language model training with persona dialogue data, such as Next Token Prediction, to implicitly achieve personalization, making these methods tend to neglect the given personas and generate generic responses. To address this issue, we propose a novel Persona-Aware Alignment Framework (PAL), which directly treats persona alignment as the training objective of dialogue generation. Specifically, PAL employs a two-stage training method including Persona-aware Learning and Persona Alignment, equipped with an easy-to-use inference strategy Select then Generate, to improve persona sensitivity and generate more persona-relevant responses at the semantics level. Through extensive experiments, we demonstrate that our framework outperforms many state-of-the-art personalized dialogue methods and large language models.
OmniRetarget: Interaction-Preserving Data Generation for Humanoid Whole-Body Loco-Manipulation and Scene Interaction
Sep 30, 2025A dominant paradigm for teaching humanoid robots complex skills is to retarget human motions as kinematic references to train reinforcement learning (RL) policies. However, existing retargeting pipelines often struggle with the significant embodiment gap between humans and robots, producing physically implausible artifacts like foot-skating and penetration. More importantly, common retargeting methods neglect the rich human-object and human-environment interactions essential for expressive locomotion and loco-manipulation. To address this, we introduce OmniRetarget, an interaction-preserving data generation engine based on an interaction mesh that explicitly models and preserves the crucial spatial and contact relationships between an agent, the terrain, and manipulated objects. By minimizing the Laplacian deformation between the human and robot meshes while enforcing kinematic constraints, OmniRetarget generates kinematically feasible trajectories. Moreover, preserving task-relevant interactions enables efficient data augmentation, from a single demonstration to different robot embodiments, terrains, and object configurations. We comprehensively evaluate OmniRetarget by retargeting motions from OMOMO, LAFAN1, and our in-house MoCap datasets, generating over 8-hour trajectories that achieve better kinematic constraint satisfaction and contact preservation than widely used baselines. Such high-quality data enables proprioceptive RL policies to successfully execute long-horizon (up to 30 seconds) parkour and loco-manipulation skills on a Unitree G1 humanoid, trained with only 5 reward terms and simple domain randomization shared by all tasks, without any learning curriculum.
Learning to Ball: Composing Policies for Long-Horizon Basketball Moves
Sep 26, 2025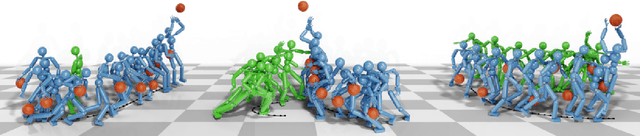

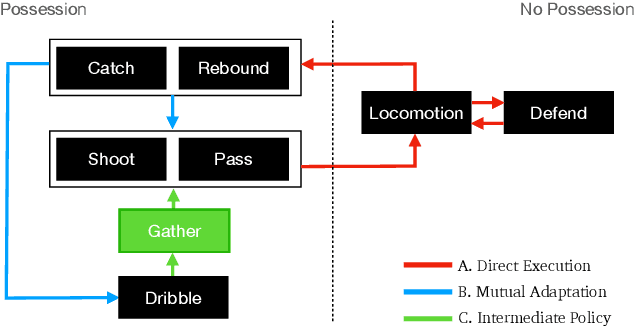

Learning a control policy for a multi-phase, long-horizon task, such as basketball maneuvers, remains challenging for reinforcement learning approaches due to the need for seamless policy composition and transitions between skills. A long-horizon task typically consists of distinct subtasks with well-defined goals, separated by transitional subtasks with unclear goals but critical to the success of the entire task. Existing methods like the mixture of experts and skill chaining struggle with tasks where individual policies do not share significant commonly explored states or lack well-defined initial and terminal states between different phases. In this paper, we introduce a novel policy integration framework to enable the composition of drastically different motor skills in multi-phase long-horizon tasks with ill-defined intermediate states. Based on that, we further introduce a high-level soft router to enable seamless and robust transitions between the subtasks. We evaluate our framework on a set of fundamental basketball skills and challenging transitions. Policies trained by our approach can effectively control the simulated character to interact with the ball and accomplish the long-horizon task specified by real-time user commands, without relying on ball trajectory references.
* ACM Transactions on Graphics (Proceedings of SIGGRAPH Asia 2025). Website: http://pei-xu.github.io/basketball. Video: https://youtu.be/2RBFIjjmR2I. Code: https://github.com/xupei0610/basketball
CS-FLEURS: A Massively Multilingual and Code-Switched Speech Dataset
Sep 17, 2025We present CS-FLEURS, a new dataset for developing and evaluating code-switched speech recognition and translation systems beyond high-resourced languages. CS-FLEURS consists of 4 test sets which cover in total 113 unique code-switched language pairs across 52 languages: 1) a 14 X-English language pair set with real voices reading synthetically generated code-switched sentences, 2) a 16 X-English language pair set with generative text-to-speech 3) a 60 {Arabic, Mandarin, Hindi, Spanish}-X language pair set with the generative text-to-speech, and 4) a 45 X-English lower-resourced language pair test set with concatenative text-to-speech. Besides the four test sets, CS-FLEURS also provides a training set with 128 hours of generative text-to-speech data across 16 X-English language pairs. Our hope is that CS-FLEURS helps to broaden the scope of future code-switched speech research. Dataset link: https://huggingface.co/datasets/byan/cs-fleurs.
Zero-Shot Human-Object Interaction Synthesis with Multimodal Priors
Mar 25, 2025Human-object interaction (HOI) synthesis is important for various applications, ranging from virtual reality to robotics. However, acquiring 3D HOI data is challenging due to its complexity and high cost, limiting existing methods to the narrow diversity of object types and interaction patterns in training datasets. This paper proposes a novel zero-shot HOI synthesis framework without relying on end-to-end training on currently limited 3D HOI datasets. The core idea of our method lies in leveraging extensive HOI knowledge from pre-trained Multimodal Models. Given a text description, our system first obtains temporally consistent 2D HOI image sequences using image or video generation models, which are then uplifted to 3D HOI milestones of human and object poses. We employ pre-trained human pose estimation models to extract human poses and introduce a generalizable category-level 6-DoF estimation method to obtain the object poses from 2D HOI images. Our estimation method is adaptive to various object templates obtained from text-to-3D models or online retrieval. A physics-based tracking of the 3D HOI kinematic milestone is further applied to refine both body motions and object poses, yielding more physically plausible HOI generation results. The experimental results demonstrate that our method is capable of generating open-vocabulary HOIs with physical realism and semantic diversity.
Counterfactual Language Reasoning for Explainable Recommendation Systems
Mar 11, 2025
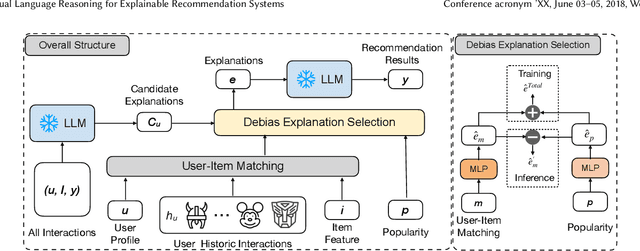

Explainable recommendation systems leverage transparent reasoning to foster user trust and improve decision-making processes. Current approaches typically decouple recommendation generation from explanation creation, violating causal precedence principles where explanatory factors should logically precede outcomes. This paper introduces a novel framework integrating structural causal models with large language models to establish causal consistency in recommendation pipelines. Our methodology enforces explanation factors as causal antecedents to recommendation predictions through causal graph construction and counterfactual adjustment. We particularly address the confounding effect of item popularity that distorts personalization signals in explanations, developing a debiasing mechanism that disentangles genuine user preferences from conformity bias. Through comprehensive experiments across multiple recommendation scenarios, we demonstrate that CausalX achieves superior performance in recommendation accuracy, explanation plausibility, and bias mitigation compared to baselines.
PersuasiveToM: A Benchmark for Evaluating Machine Theory of Mind in Persuasive Dialogues
Feb 28, 2025The ability to understand and predict the mental states of oneself and others, known as the Theory of Mind (ToM), is crucial for effective social interactions. Recent research has emerged to evaluate whether Large Language Models (LLMs) exhibit a form of ToM. Although recent studies have evaluated ToM in LLMs, existing benchmarks focus predominantly on physical perception with principles guided by the Sally-Anne test in synthetic stories and conversations, failing to capture the complex psychological activities of mental states in real-life social interactions. To mitigate this gap, we propose PersuasiveToM, a benchmark designed to evaluate the ToM abilities of LLMs in persuasive dialogues. Our framework introduces two categories of questions: (1) ToM Reasoning, assessing the capacity of LLMs to track evolving mental states (e.g., desire shifts in persuadees), and (2) ToM Application, evaluating whether LLMs can take advantage of inferred mental states to select effective persuasion strategies (e.g., emphasize rarity) and evaluate the effectiveness of persuasion strategies. Experiments across eight state-of-the-art LLMs reveal that while models excel on multiple questions, they struggle to answer questions that need tracking the dynamics and shifts of mental states and understanding the mental states in the whole dialogue comprehensively. Our aim with PersuasiveToM is to allow an effective evaluation of the ToM reasoning ability of LLMs with more focus on complex psychological activities. Our code is available at https://github.com/Yu-Fangxu/PersuasiveToM.
Rethinking Relation Extraction: Beyond Shortcuts to Generalization with a Debiased Benchmark
Jan 02, 2025



Benchmarks are crucial for evaluating machine learning algorithm performance, facilitating comparison and identifying superior solutions. However, biases within datasets can lead models to learn shortcut patterns, resulting in inaccurate assessments and hindering real-world applicability. This paper addresses the issue of entity bias in relation extraction tasks, where models tend to rely on entity mentions rather than context. We propose a debiased relation extraction benchmark DREB that breaks the pseudo-correlation between entity mentions and relation types through entity replacement. DREB utilizes Bias Evaluator and PPL Evaluator to ensure low bias and high naturalness, providing a reliable and accurate assessment of model generalization in entity bias scenarios. To establish a new baseline on DREB, we introduce MixDebias, a debiasing method combining data-level and model training-level techniques. MixDebias effectively improves model performance on DREB while maintaining performance on the original dataset. Extensive experiments demonstrate the effectiveness and robustness of MixDebias compared to existing methods, highlighting its potential for improving the generalization ability of relation extraction models. We will release DREB and MixDebias publicly.
GePBench: Evaluating Fundamental Geometric Perception for Multimodal Large Language Models
Dec 30, 2024
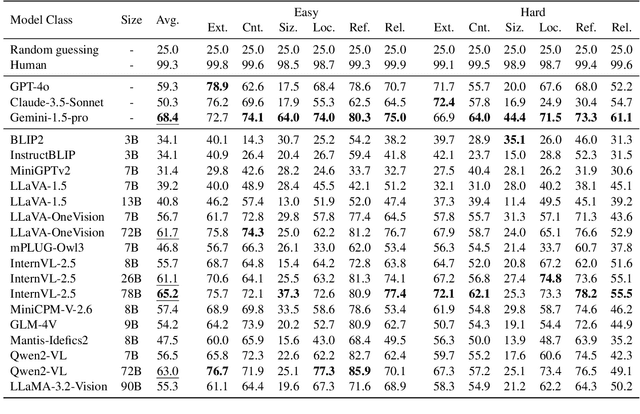


Multimodal large language models (MLLMs) have achieved significant advancements in integrating visual and linguistic understanding. While existing benchmarks evaluate these models in context-rich, real-life scenarios, they often overlook fundamental perceptual skills essential for environments deviating from everyday realism. In particular, geometric perception, the ability to interpret spatial relationships and abstract visual patterns, remains underexplored. To address this limitation, we introduce GePBench, a novel benchmark designed to assess the geometric perception capabilities of MLLMs. Results from extensive evaluations reveal that current state-of-the-art MLLMs exhibit significant deficiencies in such tasks. Additionally, we demonstrate that models trained with data sourced from GePBench show notable improvements on a wide range of downstream tasks, underscoring the importance of geometric perception as a foundation for advanced multimodal applications. Our code and datasets will be publicly available.