 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersona-Aware Alignment Framework for Personalized Dialogue Generation
Nov 13, 2025Personalized dialogue generation aims to leverage persona profiles and dialogue history to generate persona-relevant and consistent responses. Mainstream models typically rely on token-level language model training with persona dialogue data, such as Next Token Prediction, to implicitly achieve personalization, making these methods tend to neglect the given personas and generate generic responses. To address this issue, we propose a novel Persona-Aware Alignment Framework (PAL), which directly treats persona alignment as the training objective of dialogue generation. Specifically, PAL employs a two-stage training method including Persona-aware Learning and Persona Alignment, equipped with an easy-to-use inference strategy Select then Generate, to improve persona sensitivity and generate more persona-relevant responses at the semantics level. Through extensive experiments, we demonstrate that our framework outperforms many state-of-the-art personalized dialogue methods and large language models.
Counterfactual Language Reasoning for Explainable Recommendation Systems
Mar 11, 2025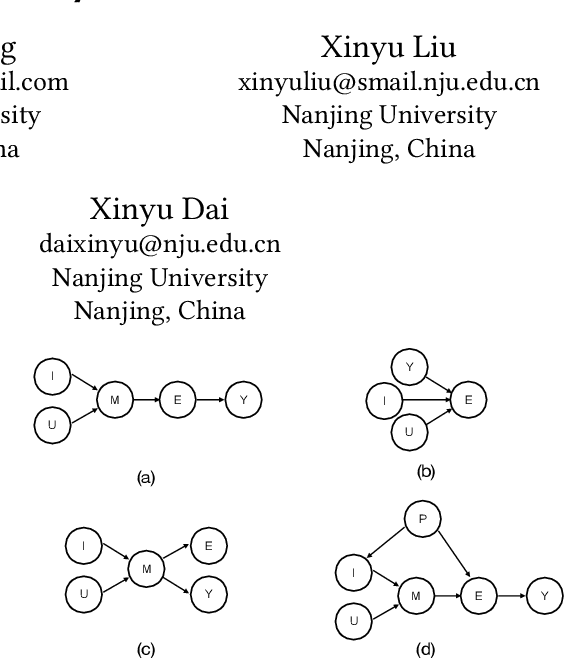
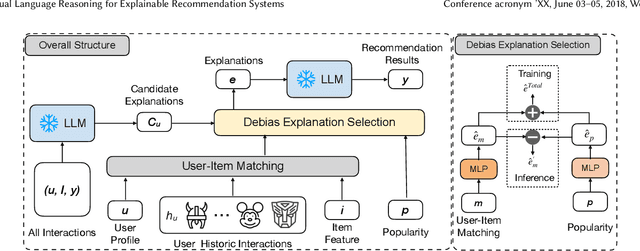

Explainable recommendation systems leverage transparent reasoning to foster user trust and improve decision-making processes. Current approaches typically decouple recommendation generation from explanation creation, violating causal precedence principles where explanatory factors should logically precede outcomes. This paper introduces a novel framework integrating structural causal models with large language models to establish causal consistency in recommendation pipelines. Our methodology enforces explanation factors as causal antecedents to recommendation predictions through causal graph construction and counterfactual adjustment. We particularly address the confounding effect of item popularity that distorts personalization signals in explanations, developing a debiasing mechanism that disentangles genuine user preferences from conformity bias. Through comprehensive experiments across multiple recommendation scenarios, we demonstrate that CausalX achieves superior performance in recommendation accuracy, explanation plausibility, and bias mitigation compared to baselines.
PersuasiveToM: A Benchmark for Evaluating Machine Theory of Mind in Persuasive Dialogues
Feb 28, 2025The ability to understand and predict the mental states of oneself and others, known as the Theory of Mind (ToM), is crucial for effective social interactions. Recent research has emerged to evaluate whether Large Language Models (LLMs) exhibit a form of ToM. Although recent studies have evaluated ToM in LLMs, existing benchmarks focus predominantly on physical perception with principles guided by the Sally-Anne test in synthetic stories and conversations, failing to capture the complex psychological activities of mental states in real-life social interactions. To mitigate this gap, we propose PersuasiveToM, a benchmark designed to evaluate the ToM abilities of LLMs in persuasive dialogues. Our framework introduces two categories of questions: (1) ToM Reasoning, assessing the capacity of LLMs to track evolving mental states (e.g., desire shifts in persuadees), and (2) ToM Application, evaluating whether LLMs can take advantage of inferred mental states to select effective persuasion strategies (e.g., emphasize rarity) and evaluate the effectiveness of persuasion strategies. Experiments across eight state-of-the-art LLMs reveal that while models excel on multiple questions, they struggle to answer questions that need tracking the dynamics and shifts of mental states and understanding the mental states in the whole dialogue comprehensively. Our aim with PersuasiveToM is to allow an effective evaluation of the ToM reasoning ability of LLMs with more focus on complex psychological activities. Our code is available at https://github.com/Yu-Fangxu/PersuasiveToM.
Rethinking Relation Extraction: Beyond Shortcuts to Generalization with a Debiased Benchmark
Jan 02, 2025



Benchmarks are crucial for evaluating machine learning algorithm performance, facilitating comparison and identifying superior solutions. However, biases within datasets can lead models to learn shortcut patterns, resulting in inaccurate assessments and hindering real-world applicability. This paper addresses the issue of entity bias in relation extraction tasks, where models tend to rely on entity mentions rather than context. We propose a debiased relation extraction benchmark DREB that breaks the pseudo-correlation between entity mentions and relation types through entity replacement. DREB utilizes Bias Evaluator and PPL Evaluator to ensure low bias and high naturalness, providing a reliable and accurate assessment of model generalization in entity bias scenarios. To establish a new baseline on DREB, we introduce MixDebias, a debiasing method combining data-level and model training-level techniques. MixDebias effectively improves model performance on DREB while maintaining performance on the original dataset. Extensive experiments demonstrate the effectiveness and robustness of MixDebias compared to existing methods, highlighting its potential for improving the generalization ability of relation extraction models. We will release DREB and MixDebias publicly.
GePBench: Evaluating Fundamental Geometric Perception for Multimodal Large Language Models
Dec 30, 2024
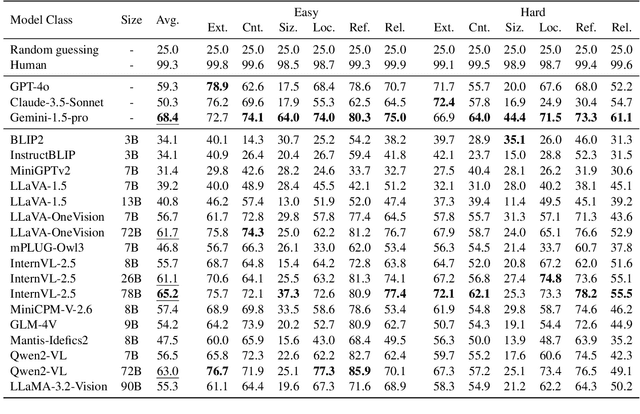


Multimodal large language models (MLLMs) have achieved significant advancements in integrating visual and linguistic understanding. While existing benchmarks evaluate these models in context-rich, real-life scenarios, they often overlook fundamental perceptual skills essential for environments deviating from everyday realism. In particular, geometric perception, the ability to interpret spatial relationships and abstract visual patterns, remains underexplored. To address this limitation, we introduce GePBench, a novel benchmark designed to assess the geometric perception capabilities of MLLMs. Results from extensive evaluations reveal that current state-of-the-art MLLMs exhibit significant deficiencies in such tasks. Additionally, we demonstrate that models trained with data sourced from GePBench show notable improvements on a wide range of downstream tasks, underscoring the importance of geometric perception as a foundation for advanced multimodal applications. Our code and datasets will be publicly available.
RAGLAB: A Modular and Research-Oriented Unified Framework for Retrieval-Augmented Generation
Aug 21, 2024
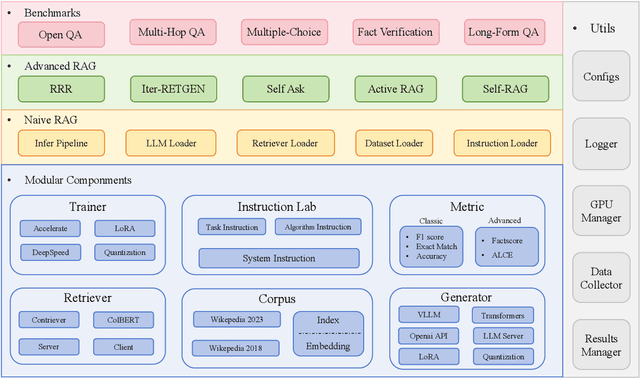

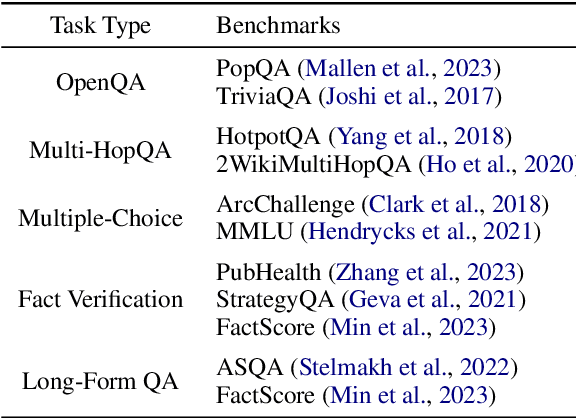
Large Language Models (LLMs) demonstrate human-level capabilities in dialogue, reasoning, and knowledge retention. However, even the most advanced LLMs face challenges such as hallucinations and real-time updating of their knowledge. Current research addresses this bottleneck by equipping LLMs with external knowledge, a technique known as Retrieval Augmented Generation (RAG). However, two key issues constrained the development of RAG. First, there is a growing lack of comprehensive and fair comparisons between novel RAG algorithms. Second, open-source tools such as LlamaIndex and LangChain employ high-level abstractions, which results in a lack of transparency and limits the ability to develop novel algorithms and evaluation metrics. To close this gap, we introduce RAGLAB, a modular and research-oriented open-source library. RAGLAB reproduces 6 existing algorithms and provides a comprehensive ecosystem for investigating RAG algorithms. Leveraging RAGLAB, we conduct a fair comparison of 6 RAG algorithms across 10 benchmarks. With RAGLAB, researchers can efficiently compare the performance of various algorithms and develop novel algorithms.
PreAlign: Boosting Cross-Lingual Transfer by Early Establishment of Multilingual Alignment
Jul 23, 2024Large language models demonstrate reasonable multilingual abilities, despite predominantly English-centric pretraining. However, the spontaneous multilingual alignment in these models is shown to be weak, leading to unsatisfactory cross-lingual transfer and knowledge sharing. Previous works attempt to address this issue by explicitly injecting multilingual alignment information during or after pretraining. Thus for the early stage in pretraining, the alignment is weak for sharing information or knowledge across languages. In this paper, we propose PreAlign, a framework that establishes multilingual alignment prior to language model pretraining. PreAlign injects multilingual alignment by initializing the model to generate similar representations of aligned words and preserves this alignment using a code-switching strategy during pretraining. Extensive experiments in a synthetic English to English-Clone setting demonstrate that PreAlign significantly outperforms standard multilingual joint training in language modeling, zero-shot cross-lingual transfer, and cross-lingual knowledge application. Further experiments in real-world scenarios further validate PreAlign's effectiveness across various model sizes.
AutoSurvey: Large Language Models Can Automatically Write Surveys
Jun 18, 2024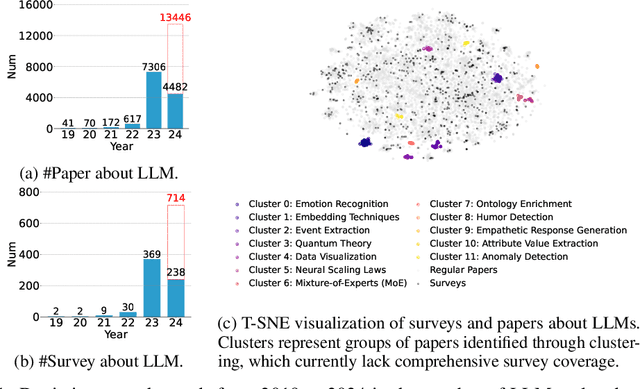
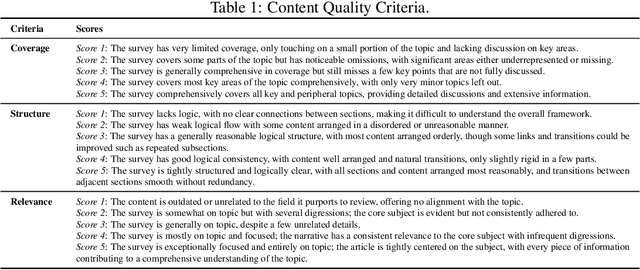
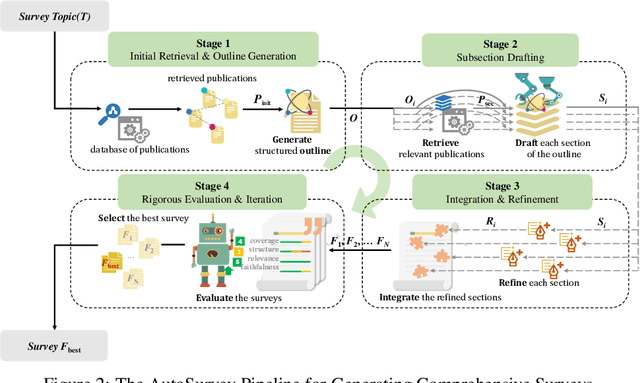
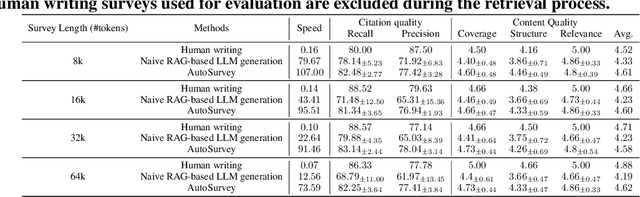
This paper introduces AutoSurvey, a speedy and well-organized methodology for automating the creation of comprehensive literature surveys in rapidly evolving fields like artificial intelligence. Traditional survey paper creation faces challenges due to the vast volume and complexity of information, prompting the need for efficient survey methods. While large language models (LLMs) offer promise in automating this process, challenges such as context window limitations, parametric knowledge constraints, and the lack of evaluation benchmarks remain. AutoSurvey addresses these challenges through a systematic approach that involves initial retrieval and outline generation, subsection drafting by specialized LLMs, integration and refinement, and rigorous evaluation and iteration. Our contributions include a comprehensive solution to the survey problem, a reliable evaluation method, and experimental validation demonstrating AutoSurvey's effectiveness.We open our resources at \url{https://github.com/AutoSurveys/AutoSurvey}.
Extroversion or Introversion? Controlling The Personality of Your Large Language Models
Jun 07, 2024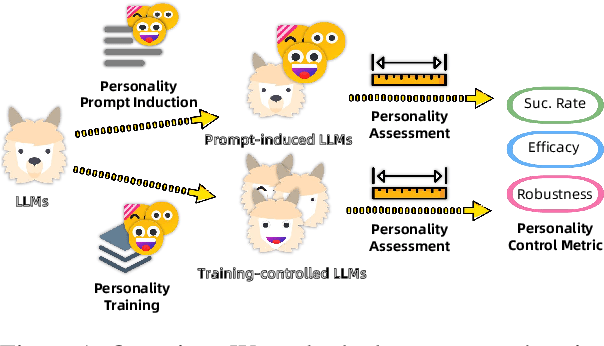
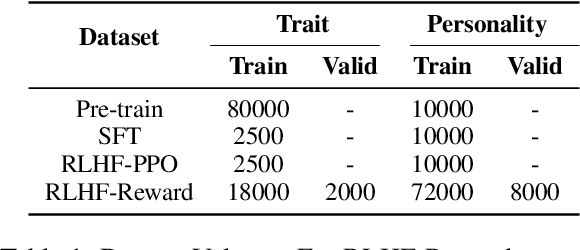
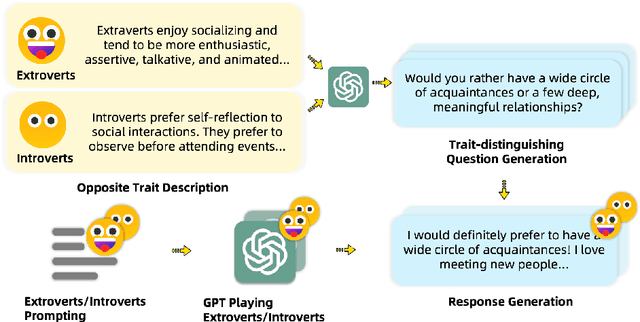

Large language models (LLMs) exhibit robust capabilities in text generation and comprehension, mimicking human behavior and exhibiting synthetic personalities. However, some LLMs have displayed offensive personality, propagating toxic discourse. Existing literature neglects the origin and evolution of LLM personalities, as well as the effective personality control. To fill these gaps, our study embarked on a comprehensive investigation into LLM personality control. We investigated several typical methods to influence LLMs, including three training methods: Continual Pre-training, Supervised Fine-Tuning (SFT), and Reinforcement Learning from Human Feedback (RLHF), along with inference phase considerations (prompts). Our investigation revealed a hierarchy of effectiveness in control: Prompt > SFT > RLHF > Continual Pre-train. Notably, SFT exhibits a higher control success rate compared to prompt induction. While prompts prove highly effective, we found that prompt-induced personalities are less robust than those trained, making them more prone to showing conflicting personalities under reverse personality prompt induction. Besides, harnessing the strengths of both SFT and prompt, we proposed $\underline{\text{P}}$rompt $\underline{\text{I}}$nduction post $\underline{\text{S}}$upervised $\underline{\text{F}}$ine-tuning (PISF), which emerges as the most effective and robust strategy for controlling LLMs' personality, displaying high efficacy, high success rates, and high robustness. Even under reverse personality prompt induction, LLMs controlled by PISF still exhibit stable and robust personalities.
AlignGPT: Multi-modal Large Language Models with Adaptive Alignment Capability
May 23, 2024

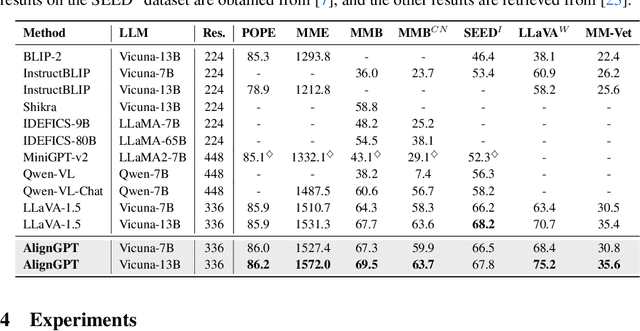
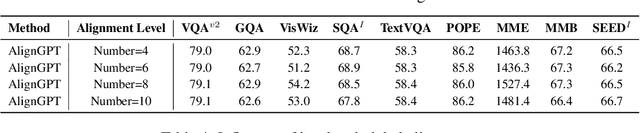
Multimodal Large Language Models (MLLMs) are widely regarded as crucial in the exploration of Artificial General Intelligence (AGI). The core of MLLMs lies in their capability to achieve cross-modal alignment. To attain this goal, current MLLMs typically follow a two-phase training paradigm: the pre-training phase and the instruction-tuning phase. Despite their success, there are shortcomings in the modeling of alignment capabilities within these models. Firstly, during the pre-training phase, the model usually assumes that all image-text pairs are uniformly aligned, but in fact the degree of alignment between different image-text pairs is inconsistent. Secondly, the instructions currently used for finetuning incorporate a variety of tasks, different tasks's instructions usually require different levels of alignment capabilities, but previous MLLMs overlook these differentiated alignment needs. To tackle these issues, we propose a new multimodal large language model AlignGPT. In the pre-training stage, instead of treating all image-text pairs equally, we assign different levels of alignment capabilities to different image-text pairs. Then, in the instruction-tuning phase, we adaptively combine these different levels of alignment capabilities to meet the dynamic alignment needs of different instructions. Extensive experimental results show that our model achieves competitive performance on 12 benchmarks.