 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Devil is in the Few Shots: Iterative Visual Knowledge Completion for Few-shot Learning
Paper and Code
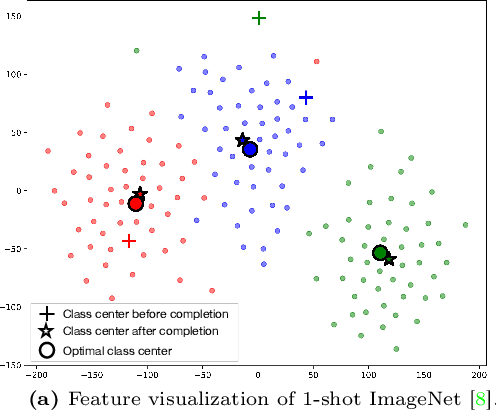
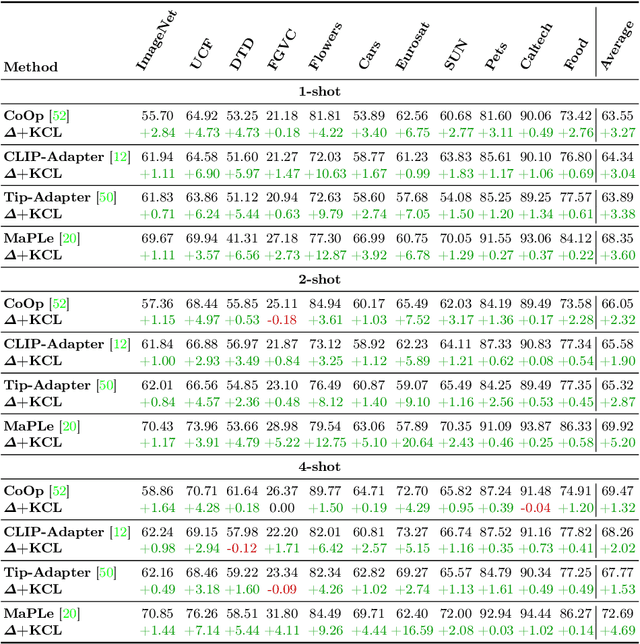
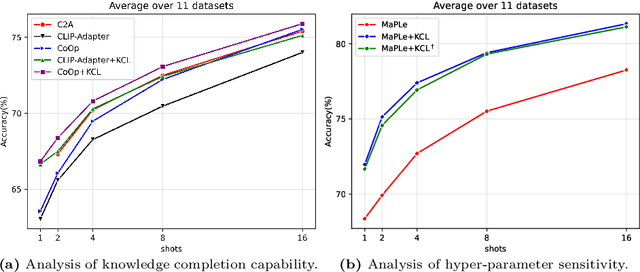
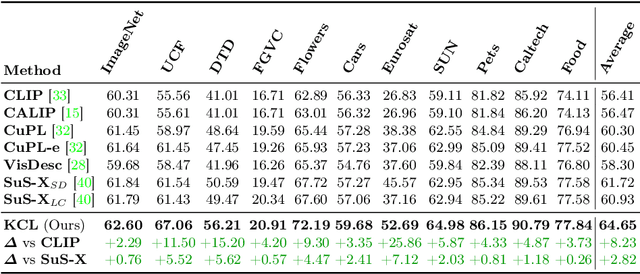
Contrastive Language-Image Pre-training (CLIP) has shown powerful zero-shot learning performance. Few-shot learning aims to further enhance the transfer capability of CLIP by giving few images in each class, aka 'few shots'. Most existing methods either implicitly learn from the few shots by incorporating learnable prompts or adapters, or explicitly embed them in a cache model for inference. However, the narrow distribution of few shots often contains incomplete class information, leading to biased visual knowledge with high risk of misclassification. To tackle this problem, recent methods propose to supplement visual knowledge by generative models or extra databases, which can be costly and time-consuming. In this paper, we propose an Iterative Visual Knowledge CompLetion (KCL) method to complement visual knowledge by properly taking advantages of unlabeled samples without access to any auxiliary or synthetic data. Specifically, KCL first measures the similarities between unlabeled samples and each category. Then, the samples with top confidence to each category is selected and collected by a designed confidence criterion. Finally, the collected samples are treated as labeled ones and added to few shots to jointly re-estimate the remaining unlabeled ones. The above procedures will be repeated for a certain number of iterations with more and more samples being collected until convergence, ensuring a progressive and robust knowledge completion process. Extensive experiments on 11 benchmark datasets demonstrate the effectiveness and efficiency of KCL as a plug-and-play module under both few-shot and zero-shot learning settings. Code is available at https://github.com/Mark-Sky/KCL.