 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaDA2.0-Uni: Unifying Multimodal Understanding and Generation with Diffusion Large Language Model
Apr 22, 2026We present LLaDA2.0-Uni, a unified discrete diffusion large language model (dLLM) that supports multimodal understanding and generation within a natively integrated framework. Its architecture combines a fully semantic discrete tokenizer, a MoE-based dLLM backbone, and a diffusion decoder. By discretizing continuous visual inputs via SigLIP-VQ, the model enables block-level masked diffusion for both text and vision inputs within the backbone, while the decoder reconstructs visual tokens into high-fidelity images. Inference efficiency is enhanced beyond parallel decoding through prefix-aware optimizations in the backbone and few-step distillation in the decoder. Supported by carefully curated large-scale data and a tailored multi-stage training pipeline, LLaDA2.0-Uni matches specialized VLMs in multimodal understanding while delivering strong performance in image generation and editing. Its native support for interleaved generation and reasoning establishes a promising and scalable paradigm for next-generation unified foundation models. Codes and models are available at https://github.com/inclusionAI/LLaDA2.0-Uni.
Adaptive and Balanced Re-initialization for Long-timescale Continual Test-time Domain Adaptation
Feb 06, 2026Continual test-time domain adaptation (CTTA) aims to adjust models so that they can perform well over time across non-stationary environments. While previous methods have made considerable efforts to optimize the adaptation process, a crucial question remains: Can the model adapt to continually changing environments over a long time? In this work, we explore facilitating better CTTA in the long run using a re-initialization (or reset) based method. First, we observe that the long-term performance is associated with the trajectory pattern in label flip. Based on this observed correlation, we propose a simple yet effective policy, Adaptive-and-Balanced Re-initialization (ABR), towards preserving the model's long-term performance. In particular, ABR performs weight re-initialization using adaptive intervals. The adaptive interval is determined based on the change in label flip. The proposed method is validated on extensive CTTA benchmarks, achieving superior performance.
dMLLM-TTS: Self-Verified and Efficient Test-Time Scaling for Diffusion Multi-Modal Large Language Models
Dec 22, 2025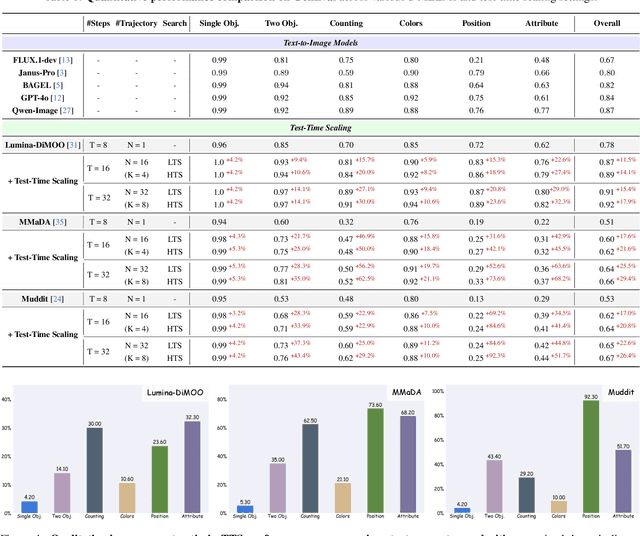

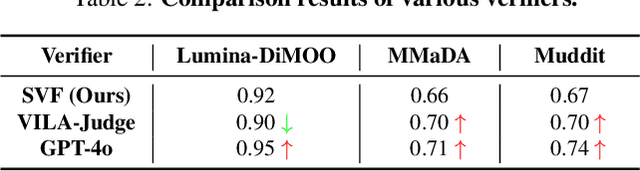
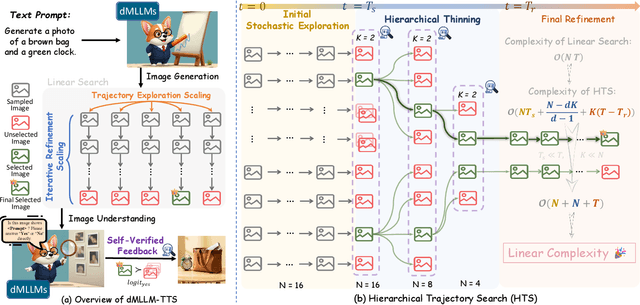
Diffusion Multi-modal Large Language Models (dMLLMs) have recently emerged as a novel architecture unifying image generation and understanding. However, developing effective and efficient Test-Time Scaling (TTS) methods to unlock their full generative potential remains an underexplored challenge. To address this, we propose dMLLM-TTS, a novel framework operating on two complementary scaling axes: (1) trajectory exploration scaling to enhance the diversity of generated hypotheses, and (2) iterative refinement scaling for stable generation. Conventional TTS approaches typically perform linear search across these two dimensions, incurring substantial computational costs of O(NT) and requiring an external verifier for best-of-N selection. To overcome these limitations, we propose two innovations. First, we design an efficient hierarchical search algorithm with O(N+T) complexity that adaptively expands and prunes sampling trajectories. Second, we introduce a self-verified feedback mechanism that leverages the dMLLMs' intrinsic image understanding capabilities to assess text-image alignment, eliminating the need for external verifier. Extensive experiments on the GenEval benchmark across three representative dMLLMs (e.g., Lumina-DiMOO, MMaDA, Muddit) show that our framework substantially improves generation quality while achieving up to 6x greater efficiency than linear search. Project page: https://github.com/Alpha-VLLM/Lumina-DiMOO.
Knocking-Heads Attention
Oct 27, 2025Multi-head attention (MHA) has become the cornerstone of modern large language models, enhancing representational capacity through parallel attention heads. However, increasing the number of heads inherently weakens individual head capacity, and existing attention mechanisms - whether standard MHA or its variants like grouped-query attention (GQA) and grouped-tied attention (GTA) - simply concatenate outputs from isolated heads without strong interaction. To address this limitation, we propose knocking-heads attention (KHA), which enables attention heads to "knock" on each other - facilitating cross-head feature-level interactions before the scaled dot-product attention. This is achieved by applying a shared, diagonally-initialized projection matrix across all heads. The diagonal initialization preserves head-specific specialization at the start of training while allowing the model to progressively learn integrated cross-head representations. KHA adds only minimal parameters and FLOPs and can be seamlessly integrated into MHA, GQA, GTA, and other attention variants. We validate KHA by training a 6.1B parameter MoE model (1.01B activated) on 1T high-quality tokens. Compared to baseline attention mechanisms, KHA brings superior and more stable training dynamics, achieving better performance across downstream tasks.
MultiEdit: Advancing Instruction-based Image Editing on Diverse and Challenging Tasks
Sep 18, 2025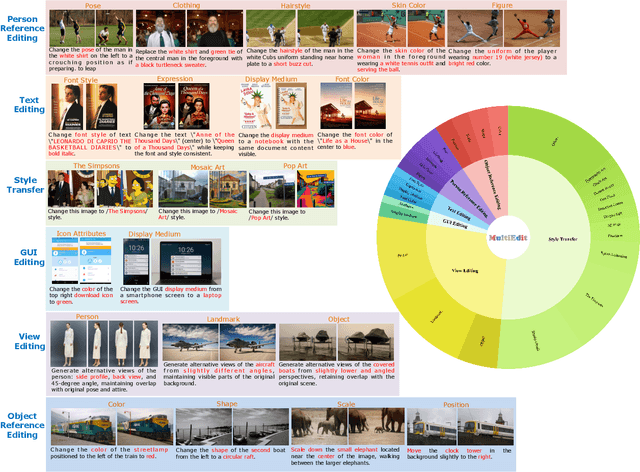
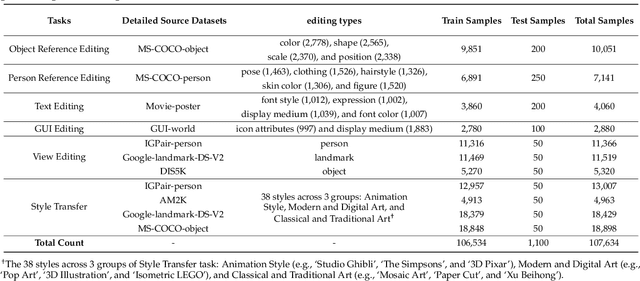
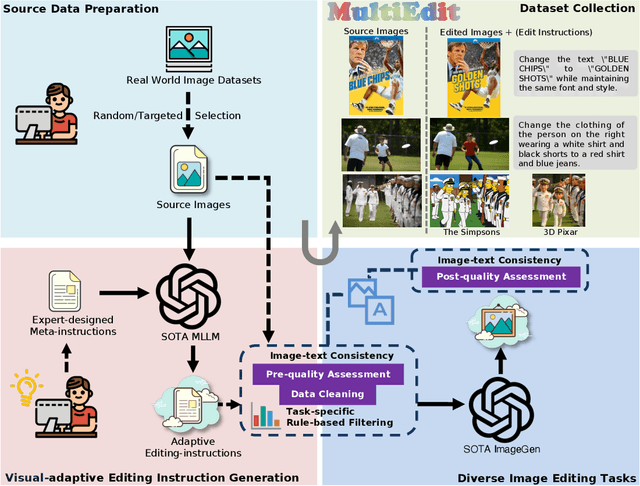
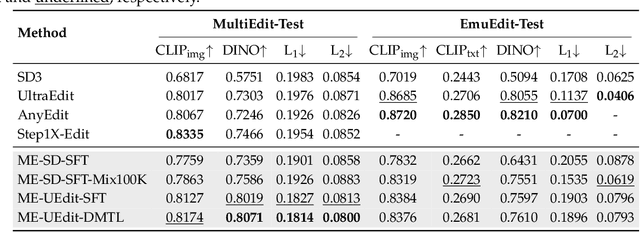
Current instruction-based image editing (IBIE) methods struggle with challenging editing tasks, as both editing types and sample counts of existing datasets are limited. Moreover, traditional dataset construction often contains noisy image-caption pairs, which may introduce biases and limit model capabilities in complex editing scenarios. To address these limitations, we introduce MultiEdit, a comprehensive dataset featuring over 107K high-quality image editing samples. It encompasses 6 challenging editing tasks through a diverse collection of 18 non-style-transfer editing types and 38 style transfer operations, covering a spectrum from sophisticated style transfer to complex semantic operations like person reference editing and in-image text editing. We employ a novel dataset construction pipeline that utilizes two multi-modal large language models (MLLMs) to generate visual-adaptive editing instructions and produce high-fidelity edited images, respectively. Extensive experiments demonstrate that fine-tuning foundational open-source models with our MultiEdit-Train set substantially improves models' performance on sophisticated editing tasks in our proposed MultiEdit-Test benchmark, while effectively preserving their capabilities on the standard editing benchmark. We believe MultiEdit provides a valuable resource for advancing research into more diverse and challenging IBIE capabilities. Our dataset is available at https://huggingface.co/datasets/inclusionAI/MultiEdit.
Grove MoE: Towards Efficient and Superior MoE LLMs with Adjugate Experts
Aug 11, 2025The Mixture of Experts (MoE) architecture is a cornerstone of modern state-of-the-art (SOTA) large language models (LLMs). MoE models facilitate scalability by enabling sparse parameter activation. However, traditional MoE architecture uses homogeneous experts of a uniform size, activating a fixed number of parameters irrespective of input complexity and thus limiting computational efficiency. To overcome this limitation, we introduce Grove MoE, a novel architecture incorporating experts of varying sizes, inspired by the heterogeneous big.LITTLE CPU architecture. This architecture features novel adjugate experts with a dynamic activation mechanism, enabling model capacity expansion while maintaining manageable computational overhead. Building on this architecture, we present GroveMoE-Base and GroveMoE-Inst, 33B-parameter LLMs developed by applying an upcycling strategy to the Qwen3-30B-A3B-Base model during mid-training and post-training. GroveMoE models dynamically activate 3.14-3.28B parameters based on token complexity and achieve performance comparable to SOTA open-source models of similar or even larger size.
Towards Explainable Fake Image Detection with Multi-Modal Large Language Models
Apr 19, 2025
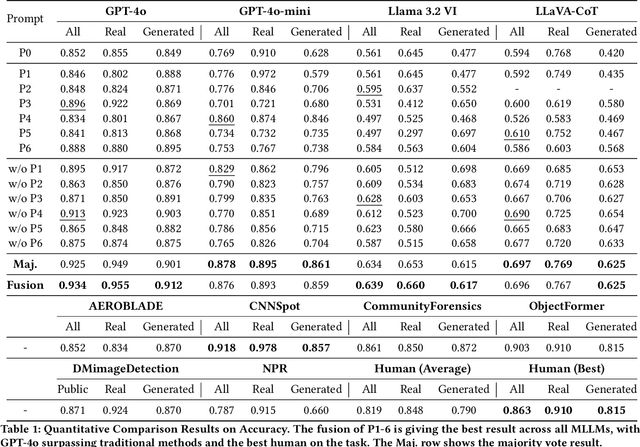

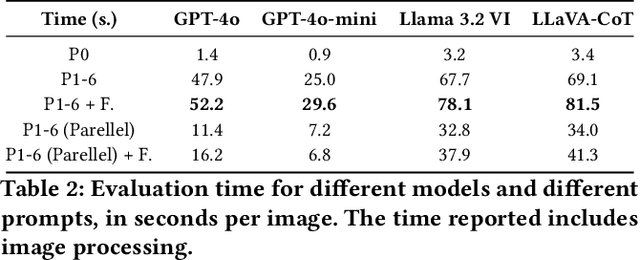
Progress in image generation raises significant public security concerns. We argue that fake image detection should not operate as a "black box". Instead, an ideal approach must ensure both strong generalization and transparency. Recent progress in Multi-modal Large Language Models (MLLMs) offers new opportunities for reasoning-based AI-generated image detection. In this work, we evaluate the capabilities of MLLMs in comparison to traditional detection methods and human evaluators, highlighting their strengths and limitations. Furthermore, we design six distinct prompts and propose a framework that integrates these prompts to develop a more robust, explainable, and reasoning-driven detection system. The code is available at https://github.com/Gennadiyev/mllm-defake.
InterAnimate: Taming Region-aware Diffusion Model for Realistic Human Interaction Animation
Apr 15, 2025Recent video generation research has focused heavily on isolated actions, leaving interactive motions-such as hand-face interactions-largely unexamined. These interactions are essential for emerging biometric authentication systems, which rely on interactive motion-based anti-spoofing approaches. From a security perspective, there is a growing need for large-scale, high-quality interactive videos to train and strengthen authentication models. In this work, we introduce a novel paradigm for animating realistic hand-face interactions. Our approach simultaneously learns spatio-temporal contact dynamics and biomechanically plausible deformation effects, enabling natural interactions where hand movements induce anatomically accurate facial deformations while maintaining collision-free contact. To facilitate this research, we present InterHF, a large-scale hand-face interaction dataset featuring 18 interaction patterns and 90,000 annotated videos. Additionally, we propose InterAnimate, a region-aware diffusion model designed specifically for interaction animation. InterAnimate leverages learnable spatial and temporal latents to effectively capture dynamic interaction priors and integrates a region-aware interaction mechanism that injects these priors into the denoising process. To the best of our knowledge, this work represents the first large-scale effort to systematically study human hand-face interactions. Qualitative and quantitative results show InterAnimate produces highly realistic animations, setting a new benchmark. Code and data will be made public to advance research.
Maintain Plasticity in Long-timescale Continual Test-time Adaptation
Dec 28, 2024



Continual test-time domain adaptation (CTTA) aims to adjust pre-trained source models to perform well over time across non-stationary target environments. While previous methods have made considerable efforts to optimize the adaptation process, a crucial question remains: can the model adapt to continually-changing environments with preserved plasticity over a long time? The plasticity refers to the model's capability to adjust predictions in response to non-stationary environments continually. In this work, we explore plasticity, this essential but often overlooked aspect of continual adaptation to facilitate more sustained adaptation in the long run. First, we observe that most CTTA methods experience a steady and consistent decline in plasticity during the long-timescale continual adaptation phase. Moreover, we find that the loss of plasticity is strongly associated with the change in label flip. Based on this correlation, we propose a simple yet effective policy, Adaptive Shrink-Restore (ASR), towards preserving the model's plasticity. In particular, ASR does the weight re-initialization by the adaptive intervals. The adaptive interval is determined based on the change in label flipping. Our method is validated on extensive CTTA benchmarks, achieving excellent performance.
Explainable Tampered Text Detection via Multimodal Large Models
Dec 19, 2024



Recently, tampered text detection has attracted increasing attention due to its essential role in information security. Although existing methods can detect the tampered text region, the interpretation of such detection remains unclear, making the prediction unreliable. To address this black-box problem, we propose to explain the basis of tampered text detection with natural language via large multimodal models. To fill the data gap for this task, we propose a large-scale, comprehensive dataset, ETTD, which contains both pixel-level annotations indicating the tampered text region and natural language annotations describing the anomaly of the tampered text. Multiple methods are employed to improve the quality of the proposed data. For example, a fused mask prompt is proposed to reduce confusion when querying GPT4o to generate anomaly descriptions. By weighting the input image with the mask annotation, the tampered region can be clearly indicated and the content in and around the tampered region can also be preserved. We also propose prompting GPT4o to recognize tampered texts and filtering out the responses with low OCR accuracy, which can effectively improve annotation quality in an automatic manner. To further improve explainable tampered text detection, we propose a simple yet effective model called TTD, which benefits from improved fine-grained perception by paying attention to the suspected region with auxiliary reference grounding query. Extensive experiments on both the ETTD dataset and the public dataset have verified the effectiveness of the proposed methods. In-depth analysis is also provided to inspire further research. The dataset and code will be made publicly available.