 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Specific Data Synthesis for LLMs via Minimal Sufficient Representation Learning
May 28, 2026Large Language Models have demonstrated remarkable progress in general-purpose capabilities and can achieve strong performance in specific domains through fine-tuning on domain-specific data. However, acquiring high-quality data for target domains remains a significant challenge. Existing data synthesis approaches follow a deductive paradigm, heavily relying on explicit domain descriptions expressed in natural language and careful prompt engineering, limiting their applicability in real-world scenarios where domains are difficult to describe or formally articulate. In this work, we tackle the underexplored problem of domain-specific data synthesis through an inductive paradigm, where the target domain is defined only through a set of reference examples, particularly when domain characteristics are difficult to articulate in natural language. We propose a novel framework, DOMINO, that learns a minimal sufficient domain representation from reference samples and leverages it to guide the generation of domain-aligned synthetic data. DOMINO integrates prompt tuning with a contrastive disentanglement objective to separate domain-level patterns from sample-specific noise, mitigating overfitting while preserving core domain characteristics. Theoretically, we prove that DOMINO expands the support of the synthetic data distribution, ensuring greater diversity. Empirically, on challenging coding benchmarks where domain definitions are implicit, fine-tuning on data synthesized by DOMINO improves Pass@1 accuracy by up to 4.63\% over strong, instruction-tuned backbones, demonstrating its effectiveness and robustness. This work establishes a new paradigm for domain-specific data synthesis, enabling practical and scalable domain adaptation without manual prompt design or natural language domain specifications.
A Scalable Benchmark Test Suite for Dynamic Multi-Objective Optimization with a Changing Number of Objectives
May 25, 2026Dynamic multi-objective optimization with a changing number of objectives has recently attracted increasing attention due to its relevance to real-world problems whose evaluation criteria may evolve over time. However, existing benchmark test suites for this problem setting suffer from a fundamental limitation: when the number of objectives changes, the objective functions themselves also change implicitly. This makes it difficult to isolate and evaluate an algorithm's capability to handle dynamics in the number of objectives alone. In this paper, we analyze this issue in detail and show that several theoretical properties claimed in prior studies rely on an assumption that is violated by commonly used test suites. To address this problem, we propose a scalable benchmark test suite in which the objective functions are fixed throughout the optimization process, while the number of active objectives changes over time. Our benchmark is constructed by defining a maximum-objective problem and dynamically selecting subsets of objectives. To avoid degeneracy issues in classical DTLZ and WFG problems, we adopt Minus-DTLZ and Minus-WFG formulations, in which all objectives are mutually conflicting. Extensive benchmark studies using representative algorithms from the literature demonstrate the usefulness and flexibility of the proposed test suite.
WebGen-R1: Incentivizing Large Language Models to Generate Functional and Aesthetic Websites with Reinforcement Learning
Apr 22, 2026While Large Language Models (LLMs) excel at function-level code generation, project-level tasks such as generating functional and visually aesthetic multi-page websites remain highly challenging. Existing works are often limited to single-page static websites, while agentic frameworks typically rely on multi-turn execution with proprietary models, leading to substantial token costs, high latency, and brittle integration. Training a small LLM end-to-end with reinforcement learning (RL) is a promising alternative, yet it faces a critical bottleneck in designing reliable and computationally feasible rewards for website generation. Unlike single-file coding tasks that can be verified by unit tests, website generation requires evaluating inherently subjective aesthetics, cross-page interactions, and functional correctness. To this end, we propose WebGen-R1, an end-to-end RL framework tailored for project-level website generation. We first introduce a scaffold-driven structured generation paradigm that constrains the large open-ended action space and preserves architectural integrity. We then design a novel cascaded multimodal reward that seamlessly couples structural guarantees with execution-grounded functional feedback and vision-based aesthetic supervision. Extensive experiments demonstrate that our WebGen-R1 substantially transforms a 7B base model from generating nearly nonfunctional websites into producing deployable, aesthetically aligned multi-page websites. Remarkably, our WebGen-R1 not only consistently outperforms heavily scaled open-source models (up to 72B), but also rivals the state-of-the-art DeepSeek-R1 (671B) in functional success, while substantially exceeding it in valid rendering and aesthetic alignment. These results position WebGen-R1 as a viable path for scaling small open models from function-level code generation to project-level web application generation.
LLaDA2.0-Uni: Unifying Multimodal Understanding and Generation with Diffusion Large Language Model
Apr 22, 2026We present LLaDA2.0-Uni, a unified discrete diffusion large language model (dLLM) that supports multimodal understanding and generation within a natively integrated framework. Its architecture combines a fully semantic discrete tokenizer, a MoE-based dLLM backbone, and a diffusion decoder. By discretizing continuous visual inputs via SigLIP-VQ, the model enables block-level masked diffusion for both text and vision inputs within the backbone, while the decoder reconstructs visual tokens into high-fidelity images. Inference efficiency is enhanced beyond parallel decoding through prefix-aware optimizations in the backbone and few-step distillation in the decoder. Supported by carefully curated large-scale data and a tailored multi-stage training pipeline, LLaDA2.0-Uni matches specialized VLMs in multimodal understanding while delivering strong performance in image generation and editing. Its native support for interleaved generation and reasoning establishes a promising and scalable paradigm for next-generation unified foundation models. Codes and models are available at https://github.com/inclusionAI/LLaDA2.0-Uni.
QuitoBench: A High-Quality Open Time Series Forecasting Benchmark
Mar 27, 2026Time series forecasting is critical across finance, healthcare, and cloud computing, yet progress is constrained by a fundamental bottleneck: the scarcity of large-scale, high-quality benchmarks. To address this gap, we introduce \textsc{QuitoBench}, a regime-balanced benchmark for time series forecasting with coverage across eight trend$\times$seasonality$\times$forecastability (TSF) regimes, designed to capture forecasting-relevant properties rather than application-defined domain labels. The benchmark is built upon \textsc{Quito}, a billion-scale time series corpus of application traffic from Alipay spanning nine business domains. Benchmarking 10 models from deep learning, foundation models, and statistical baselines across 232,200 evaluation instances, we report four key findings: (i) a context-length crossover where deep learning models lead at short context ($L=96$) but foundation models dominate at long context ($L \ge 576$); (ii) forecastability is the dominant difficulty driver, producing a $3.64 \times$ MAE gap across regimes; (iii) deep learning models match or surpass foundation models at $59 \times$ fewer parameters; and (iv) scaling the amount of training data provides substantially greater benefit than scaling model size for both model families. These findings are validated by strong cross-benchmark and cross-metric consistency. Our open-source release enables reproducible, regime-aware evaluation for time series forecasting research.
TAROT: Test-driven and Capability-adaptive Curriculum Reinforcement Fine-tuning for Code Generation with Large Language Models
Feb 17, 2026Large Language Models (LLMs) are changing the coding paradigm, known as vibe coding, yet synthesizing algorithmically sophisticated and robust code still remains a critical challenge. Incentivizing the deep reasoning capabilities of LLMs is essential to overcoming this hurdle. Reinforcement Fine-Tuning (RFT) has emerged as a promising strategy to address this need. However, most existing approaches overlook the heterogeneous difficulty and granularity inherent in test cases, leading to an imbalanced distribution of reward signals and consequently biased gradient updates during training. To address this, we propose Test-driven and cApability-adaptive cuRriculum reinfOrcement fine-Tuning (TAROT). TAROT systematically constructs, for each problem, a four-tier test suite (basic, intermediate, complex, edge), providing a controlled difficulty landscape for curriculum design and evaluation. Crucially, TAROT decouples curriculum progression from raw reward scores, enabling capability-conditioned evaluation and principled selection from a portfolio of curriculum policies rather than incidental test-case difficulty composition. This design fosters stable optimization and more efficient competency acquisition. Extensive experimental results reveal that the optimal curriculum for RFT in code generation is closely tied to a model's inherent capability, with less capable models achieving greater gains with an easy-to-hard progression, whereas more competent models excel under a hard-first curriculum. TAROT provides a reproducible method that adaptively tailors curriculum design to a model's capability, thereby consistently improving the functional correctness and robustness of the generated code. All code and data are released to foster reproducibility and advance community research at https://github.com/deep-diver/TAROT.
LLaDA2.1: Speeding Up Text Diffusion via Token Editing
Feb 09, 2026While LLaDA2.0 showcased the scaling potential of 100B-level block-diffusion models and their inherent parallelization, the delicate equilibrium between decoding speed and generation quality has remained an elusive frontier. Today, we unveil LLaDA2.1, a paradigm shift designed to transcend this trade-off. By seamlessly weaving Token-to-Token (T2T) editing into the conventional Mask-to-Token (M2T) scheme, we introduce a joint, configurable threshold-decoding scheme. This structural innovation gives rise to two distinct personas: the Speedy Mode (S Mode), which audaciously lowers the M2T threshold to bypass traditional constraints while relying on T2T to refine the output; and the Quality Mode (Q Mode), which leans into conservative thresholds to secure superior benchmark performances with manageable efficiency degrade. Furthering this evolution, underpinned by an expansive context window, we implement the first large-scale Reinforcement Learning (RL) framework specifically tailored for dLLMs, anchored by specialized techniques for stable gradient estimation. This alignment not only sharpens reasoning precision but also elevates instruction-following fidelity, bridging the chasm between diffusion dynamics and complex human intent. We culminate this work by releasing LLaDA2.1-Mini (16B) and LLaDA2.1-Flash (100B). Across 33 rigorous benchmarks, LLaDA2.1 delivers strong task performance and lightning-fast decoding speed. Despite its 100B volume, on coding tasks it attains an astounding 892 TPS on HumanEval+, 801 TPS on BigCodeBench, and 663 TPS on LiveCodeBench.
LLaDA2.0: Scaling Up Diffusion Language Models to 100B
Dec 24, 2025This paper presents LLaDA2.0 -- a tuple of discrete diffusion large language models (dLLM) scaling up to 100B total parameters through systematic conversion from auto-regressive (AR) models -- establishing a new paradigm for frontier-scale deployment. Instead of costly training from scratch, LLaDA2.0 upholds knowledge inheritance, progressive adaption and efficiency-aware design principle, and seamless converts a pre-trained AR model into dLLM with a novel 3-phase block-level WSD based training scheme: progressive increasing block-size in block diffusion (warm-up), large-scale full-sequence diffusion (stable) and reverting back to compact-size block diffusion (decay). Along with post-training alignment with SFT and DPO, we obtain LLaDA2.0-mini (16B) and LLaDA2.0-flash (100B), two instruction-tuned Mixture-of-Experts (MoE) variants optimized for practical deployment. By preserving the advantages of parallel decoding, these models deliver superior performance and efficiency at the frontier scale. Both models were open-sourced.
Knocking-Heads Attention
Oct 27, 2025Multi-head attention (MHA) has become the cornerstone of modern large language models, enhancing representational capacity through parallel attention heads. However, increasing the number of heads inherently weakens individual head capacity, and existing attention mechanisms - whether standard MHA or its variants like grouped-query attention (GQA) and grouped-tied attention (GTA) - simply concatenate outputs from isolated heads without strong interaction. To address this limitation, we propose knocking-heads attention (KHA), which enables attention heads to "knock" on each other - facilitating cross-head feature-level interactions before the scaled dot-product attention. This is achieved by applying a shared, diagonally-initialized projection matrix across all heads. The diagonal initialization preserves head-specific specialization at the start of training while allowing the model to progressively learn integrated cross-head representations. KHA adds only minimal parameters and FLOPs and can be seamlessly integrated into MHA, GQA, GTA, and other attention variants. We validate KHA by training a 6.1B parameter MoE model (1.01B activated) on 1T high-quality tokens. Compared to baseline attention mechanisms, KHA brings superior and more stable training dynamics, achieving better performance across downstream tasks.
MultiEdit: Advancing Instruction-based Image Editing on Diverse and Challenging Tasks
Sep 18, 2025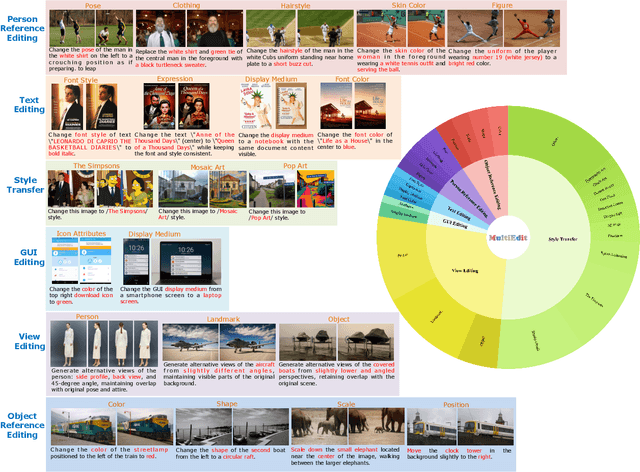
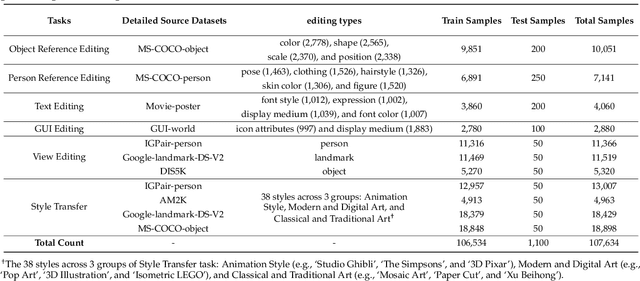
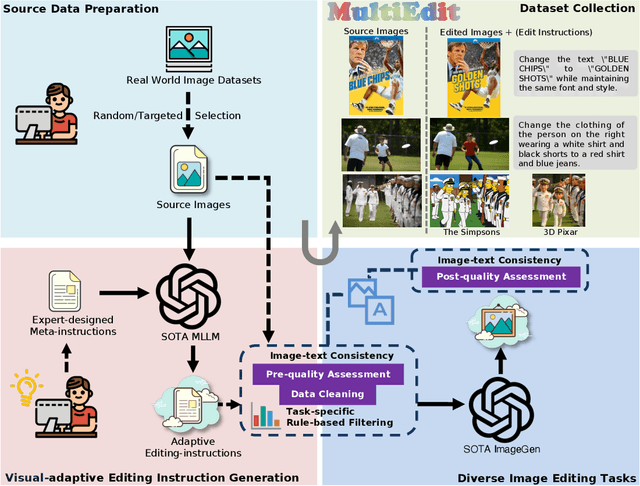
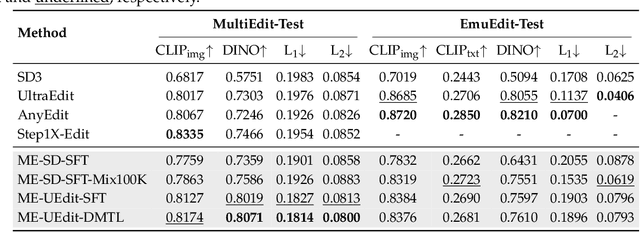
Current instruction-based image editing (IBIE) methods struggle with challenging editing tasks, as both editing types and sample counts of existing datasets are limited. Moreover, traditional dataset construction often contains noisy image-caption pairs, which may introduce biases and limit model capabilities in complex editing scenarios. To address these limitations, we introduce MultiEdit, a comprehensive dataset featuring over 107K high-quality image editing samples. It encompasses 6 challenging editing tasks through a diverse collection of 18 non-style-transfer editing types and 38 style transfer operations, covering a spectrum from sophisticated style transfer to complex semantic operations like person reference editing and in-image text editing. We employ a novel dataset construction pipeline that utilizes two multi-modal large language models (MLLMs) to generate visual-adaptive editing instructions and produce high-fidelity edited images, respectively. Extensive experiments demonstrate that fine-tuning foundational open-source models with our MultiEdit-Train set substantially improves models' performance on sophisticated editing tasks in our proposed MultiEdit-Test benchmark, while effectively preserving their capabilities on the standard editing benchmark. We believe MultiEdit provides a valuable resource for advancing research into more diverse and challenging IBIE capabilities. Our dataset is available at https://huggingface.co/datasets/inclusionAI/MultiEdit.