 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Expert-Attention Allocation in Mixture-of-Experts: A Scalable Law for Dynamic Model Design
Mar 11, 2026This paper presents a novel extension of neural scaling laws to Mixture-of-Experts (MoE) models, focusing on the optimal allocation of compute between expert and attention sub-layers. As MoE architectures have emerged as an efficient method for scaling model capacity without proportionally increasing computation, determining the optimal expert-attention compute ratio becomes critical. We define the ratio $r$ as the fraction of total FLOPs per token dedicated to the expert layers versus the attention layers, and explore how this ratio interacts with the overall compute budget and model sparsity. Through extensive experiments with GPT-style MoE Transformers, we empirically find that the optimal ratio $r^*$ follows a power-law relationship with total compute and varies with sparsity. Our analysis leads to an explicit formula for $r^*$, enabling precise control over the expert-attention compute allocation. We generalize the Chinchilla scaling law by incorporating this architectural parameter, providing a new framework for tuning MoE models beyond size and data. Our findings offer practical guidelines for designing efficient MoE models, optimizing performance while respecting fixed compute budgets.
MergeMix: Optimizing Mid-Training Data Mixtures via Learnable Model Merging
Jan 25, 2026Optimizing data mixtures is essential for unlocking the full potential of large language models (LLMs), yet identifying the optimal composition remains computationally prohibitive due to reliance on heuristic trials or expensive proxy training. To address this, we introduce \textbf{MergeMix}, a novel approach that efficiently determines optimal data mixing ratios by repurposing model merging weights as a high-fidelity, low-cost performance proxy. By training domain-specific experts on minimal tokens and optimizing their merging weights against downstream benchmarks, MergeMix effectively optimizes the performance of data mixtures without incurring the cost of full-scale training. Extensive experiments on models with 8B and 16B parameters validate that MergeMix achieves performance comparable to or surpassing exhaustive manual tuning while drastically reducing search costs. Furthermore, MergeMix exhibits high rank consistency (Spearman $ρ> 0.9$) and strong cross-scale transferability, offering a scalable, automated solution for data mixture optimization.
Arrows of Math Reasoning Data Synthesis for Large Language Models: Diversity, Complexity and Correctness
Aug 26, 2025Enhancing the mathematical reasoning of large language models (LLMs) demands high-quality training data, yet conventional methods face critical challenges in scalability, cost, and data reliability. To address these limitations, we propose a novel program-assisted synthesis framework that systematically generates a high-quality mathematical corpus with guaranteed diversity, complexity, and correctness. This framework integrates mathematical knowledge systems and domain-specific tools to create executable programs. These programs are then translated into natural language problem-solution pairs and vetted by a bilateral validation mechanism that verifies solution correctness against program outputs and ensures program-problem consistency. We have generated 12.3 million such problem-solving triples. Experiments demonstrate that models fine-tuned on our data significantly improve their inference capabilities, achieving state-of-the-art performance on several benchmark datasets and showcasing the effectiveness of our synthesis approach.
Towards Greater Leverage: Scaling Laws for Efficient Mixture-of-Experts Language Models
Jul 24, 2025Mixture-of-Experts (MoE) has become a dominant architecture for scaling Large Language Models (LLMs) efficiently by decoupling total parameters from computational cost. However, this decoupling creates a critical challenge: predicting the model capacity of a given MoE configurations (e.g., expert activation ratio and granularity) remains an unresolved problem. To address this gap, we introduce Efficiency Leverage (EL), a metric quantifying the computational advantage of an MoE model over a dense equivalent. We conduct a large-scale empirical study, training over 300 models up to 28B parameters, to systematically investigate the relationship between MoE architectural configurations and EL. Our findings reveal that EL is primarily driven by the expert activation ratio and the total compute budget, both following predictable power laws, while expert granularity acts as a non-linear modulator with a clear optimal range. We integrate these discoveries into a unified scaling law that accurately predicts the EL of an MoE architecture based on its configuration. To validate our derived scaling laws, we designed and trained Ling-mini-beta, a pilot model for Ling-2.0 series with only 0.85B active parameters, alongside a 6.1B dense model for comparison. When trained on an identical 1T high-quality token dataset, Ling-mini-beta matched the performance of the 6.1B dense model while consuming over 7x fewer computational resources, thereby confirming the accuracy of our scaling laws. This work provides a principled and empirically-grounded foundation for the scaling of efficient MoE models.
WSM: Decay-Free Learning Rate Schedule via Checkpoint Merging for LLM Pre-training
Jul 23, 2025Recent advances in learning rate (LR) scheduling have demonstrated the effectiveness of decay-free approaches that eliminate the traditional decay phase while maintaining competitive performance. Model merging techniques have emerged as particularly promising solutions in this domain. We present Warmup-Stable and Merge (WSM), a general framework that establishes a formal connection between learning rate decay and model merging. WSM provides a unified theoretical foundation for emulating various decay strategies-including cosine decay, linear decay and inverse square root decay-as principled model averaging schemes, while remaining fully compatible with diverse optimization methods. Through extensive experiments, we identify merge duration-the training window for checkpoint aggregation-as the most critical factor influencing model performance, surpassing the importance of both checkpoint interval and merge quantity. Our framework consistently outperforms the widely-adopted Warmup-Stable-Decay (WSD) approach across multiple benchmarks, achieving significant improvements of +3.5% on MATH, +2.9% on HumanEval, and +5.5% on MMLU-Pro. The performance advantages extend to supervised fine-tuning scenarios, highlighting WSM's potential for long-term model refinement.
Every FLOP Counts: Scaling a 300B Mixture-of-Experts LING LLM without Premium GPUs
Mar 07, 2025



In this technical report, we tackle the challenges of training large-scale Mixture of Experts (MoE) models, focusing on overcoming cost inefficiency and resource limitations prevalent in such systems. To address these issues, we present two differently sized MoE large language models (LLMs), namely Ling-Lite and Ling-Plus (referred to as "Bailing" in Chinese, spelled B\v{a}il\'ing in Pinyin). Ling-Lite contains 16.8 billion parameters with 2.75 billion activated parameters, while Ling-Plus boasts 290 billion parameters with 28.8 billion activated parameters. Both models exhibit comparable performance to leading industry benchmarks. This report offers actionable insights to improve the efficiency and accessibility of AI development in resource-constrained settings, promoting more scalable and sustainable technologies. Specifically, to reduce training costs for large-scale MoE models, we propose innovative methods for (1) optimization of model architecture and training processes, (2) refinement of training anomaly handling, and (3) enhancement of model evaluation efficiency. Additionally, leveraging high-quality data generated from knowledge graphs, our models demonstrate superior capabilities in tool use compared to other models. Ultimately, our experimental findings demonstrate that a 300B MoE LLM can be effectively trained on lower-performance devices while achieving comparable performance to models of a similar scale, including dense and MoE models. Compared to high-performance devices, utilizing a lower-specification hardware system during the pre-training phase demonstrates significant cost savings, reducing computing costs by approximately 20%. The models can be accessed at https://huggingface.co/inclusionAI.
Can Small Language Models be Good Reasoners for Sequential Recommendation?
Mar 07, 2024



Large language models (LLMs) open up new horizons for sequential recommendations, owing to their remarkable language comprehension and generation capabilities. However, there are still numerous challenges that should be addressed to successfully implement sequential recommendations empowered by LLMs. Firstly, user behavior patterns are often complex, and relying solely on one-step reasoning from LLMs may lead to incorrect or task-irrelevant responses. Secondly, the prohibitively resource requirements of LLM (e.g., ChatGPT-175B) are overwhelmingly high and impractical for real sequential recommender systems. In this paper, we propose a novel Step-by-step knowLedge dIstillation fraMework for recommendation (SLIM), paving a promising path for sequential recommenders to enjoy the exceptional reasoning capabilities of LLMs in a "slim" (i.e., resource-efficient) manner. We introduce CoT prompting based on user behavior sequences for the larger teacher model. The rationales generated by the teacher model are then utilized as labels to distill the downstream smaller student model (e.g., LLaMA2-7B). In this way, the student model acquires the step-by-step reasoning capabilities in recommendation tasks. We encode the generated rationales from the student model into a dense vector, which empowers recommendation in both ID-based and ID-agnostic scenarios. Extensive experiments demonstrate the effectiveness of SLIM over state-of-the-art baselines, and further analysis showcasing its ability to generate meaningful recommendation reasoning at affordable costs.
RecBole 2.0: Towards a More Up-to-Date Recommendation Library
Jun 16, 2022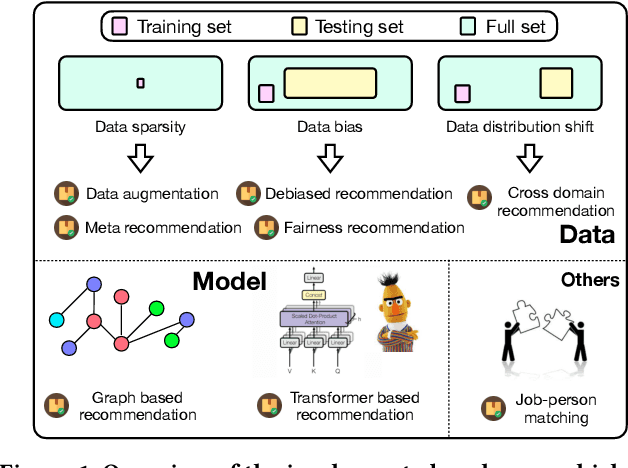
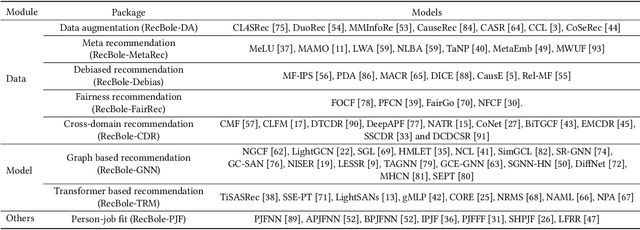

In order to support the study of recent advances in recommender systems, this paper presents an extended recommendation library consisting of eight packages for up-to-date topics and architectures. First of all, from a data perspective, we consider three important topics related to data issues (i.e., sparsity, bias and distribution shift), and develop five packages accordingly: meta-learning, data augmentation, debiasing, fairness and cross-domain recommendation. Furthermore, from a model perspective, we develop two benchmarking packages for Transformer-based and graph neural network (GNN)-based models, respectively. All the packages (consisting of 65 new models) are developed based on a popular recommendation framework RecBole, ensuring that both the implementation and interface are unified. For each package, we provide complete implementations from data loading, experimental setup, evaluation and algorithm implementation. This library provides a valuable resource to facilitate the up-to-date research in recommender systems. The project is released at the link: https://github.com/RUCAIBox/RecBole2.0.
Improving Graph Collaborative Filtering with Neighborhood-enriched Contrastive Learning
Feb 15, 2022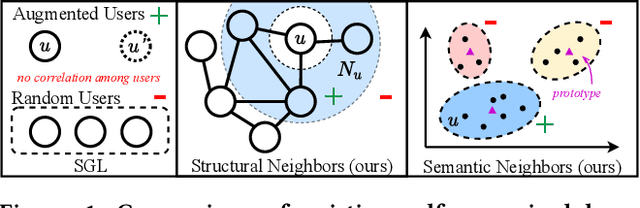
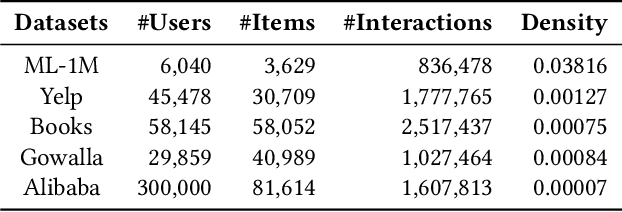
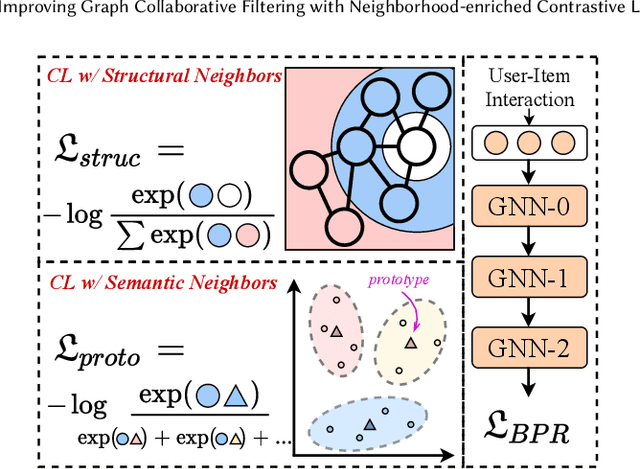
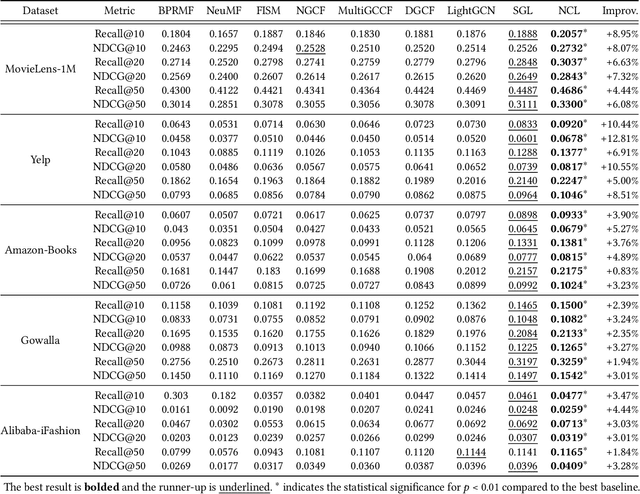
Recently, graph collaborative filtering methods have been proposed as an effective recommendation approach, which can capture users' preference over items by modeling the user-item interaction graphs. In order to reduce the influence of data sparsity, contrastive learning is adopted in graph collaborative filtering for enhancing the performance. However, these methods typically construct the contrastive pairs by random sampling, which neglect the neighboring relations among users (or items) and fail to fully exploit the potential of contrastive learning for recommendation. To tackle the above issue, we propose a novel contrastive learning approach, named Neighborhood-enriched Contrastive Learning, named NCL, which explicitly incorporates the potential neighbors into contrastive pairs. Specifically, we introduce the neighbors of a user (or an item) from graph structure and semantic space respectively. For the structural neighbors on the interaction graph, we develop a novel structure-contrastive objective that regards users (or items) and their structural neighbors as positive contrastive pairs. In implementation, the representations of users (or items) and neighbors correspond to the outputs of different GNN layers. Furthermore, to excavate the potential neighbor relation in semantic space, we assume that users with similar representations are within the semantic neighborhood, and incorporate these semantic neighbors into the prototype-contrastive objective. The proposed NCL can be optimized with EM algorithm and generalized to apply to graph collaborative filtering methods. Extensive experiments on five public datasets demonstrate the effectiveness of the proposed NCL, notably with 26% and 17% performance gain over a competitive graph collaborative filtering base model on the Yelp and Amazon-book datasets respectively. Our code is available at: https://github.com/RUCAIBox/NCL.