 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken-level Collaborative Alignment for LLM-based Generative Recommendation
Jan 26, 2026Large Language Models (LLMs) have demonstrated strong potential for generative recommendation by leveraging rich semantic knowledge. However, existing LLM-based recommender systems struggle to effectively incorporate collaborative filtering (CF) signals, due to a fundamental mismatch between item-level preference modeling in CF and token-level next-token prediction (NTP) optimization in LLMs. Prior approaches typically treat CF as contextual hints or representation bias, and resort to multi-stage training to reduce behavioral semantic space discrepancies, leaving CF unable to explicitly regulate LLM generation. In this work, we propose Token-level Collaborative Alignment for Recommendation (TCA4Rec), a model-agnostic and plug-and-play framework that establishes an explicit optimization-level interface between CF supervision and LLM generation. TCA4Rec consists of (i) Collaborative Tokenizer, which projects raw item-level CF logits into token-level distributions aligned with the LLM token space, and (ii) Soft Label Alignment, which integrates these CF-informed distributions with one-hot supervision to optimize a soft NTP objective. This design preserves the generative nature of LLM training while enabling collaborative alignment with essential user preference of CF models. We highlight TCA4Rec is compatible with arbitrary traditional CF models and generalizes across a wide range of decoder-based LLM recommender architectures. Moreover, it provides an explicit mechanism to balance behavioral alignment and semantic fluency, yielding generative recommendations that are both accurate and controllable. Extensive experiments demonstrate that TCA4Rec consistently improves recommendation performance across a broad spectrum of CF models and LLM-based recommender systems.
Arrows of Math Reasoning Data Synthesis for Large Language Models: Diversity, Complexity and Correctness
Aug 26, 2025Enhancing the mathematical reasoning of large language models (LLMs) demands high-quality training data, yet conventional methods face critical challenges in scalability, cost, and data reliability. To address these limitations, we propose a novel program-assisted synthesis framework that systematically generates a high-quality mathematical corpus with guaranteed diversity, complexity, and correctness. This framework integrates mathematical knowledge systems and domain-specific tools to create executable programs. These programs are then translated into natural language problem-solution pairs and vetted by a bilateral validation mechanism that verifies solution correctness against program outputs and ensures program-problem consistency. We have generated 12.3 million such problem-solving triples. Experiments demonstrate that models fine-tuned on our data significantly improve their inference capabilities, achieving state-of-the-art performance on several benchmark datasets and showcasing the effectiveness of our synthesis approach.
POLYRAG: Integrating Polyviews into Retrieval-Augmented Generation for Medical Applications
Apr 21, 2025



Large language models (LLMs) have become a disruptive force in the industry, introducing unprecedented capabilities in natural language processing, logical reasoning and so on. However, the challenges of knowledge updates and hallucination issues have limited the application of LLMs in medical scenarios, where retrieval-augmented generation (RAG) can offer significant assistance. Nevertheless, existing retrieve-then-read approaches generally digest the retrieved documents, without considering the timeliness, authoritativeness and commonality of retrieval. We argue that these approaches can be suboptimal, especially in real-world applications where information from different sources might conflict with each other and even information from the same source in different time scale might be different, and totally relying on this would deteriorate the performance of RAG approaches. We propose PolyRAG that carefully incorporate judges from different perspectives and finally integrate the polyviews for retrieval augmented generation in medical applications. Due to the scarcity of real-world benchmarks for evaluation, to bridge the gap we propose PolyEVAL, a benchmark consists of queries and documents collected from real-world medical scenarios (including medical policy, hospital & doctor inquiry and healthcare) with multiple tagging (e.g., timeliness, authoritativeness) on them. Extensive experiments and analysis on PolyEVAL have demonstrated the superiority of PolyRAG.
Unlocking General Long Chain-of-Thought Reasoning Capabilities of Large Language Models via Representation Engineering
Mar 14, 2025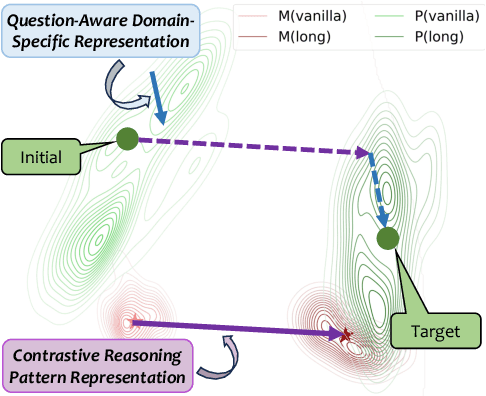



Recent advancements in long chain-of-thoughts(long CoTs) have significantly improved the reasoning capabilities of large language models(LLMs). Existing work finds that the capability of long CoT reasoning can be efficiently elicited by tuning on only a few examples and can easily transfer to other tasks. This motivates us to investigate whether long CoT reasoning is a general capability for LLMs. In this work, we conduct an empirical analysis for this question from the perspective of representation. We find that LLMs do encode long CoT reasoning as a general capability, with a clear distinction from vanilla CoTs. Furthermore, domain-specific representations are also required for the effective transfer of long CoT reasoning. Inspired by these findings, we propose GLoRE, a novel representation engineering method to unleash the general long CoT reasoning capabilities of LLMs. Extensive experiments demonstrate the effectiveness and efficiency of GLoRE in both in-domain and cross-domain scenarios.
Have We Designed Generalizable Structural Knowledge Promptings? Systematic Evaluation and Rethinking
Dec 31, 2024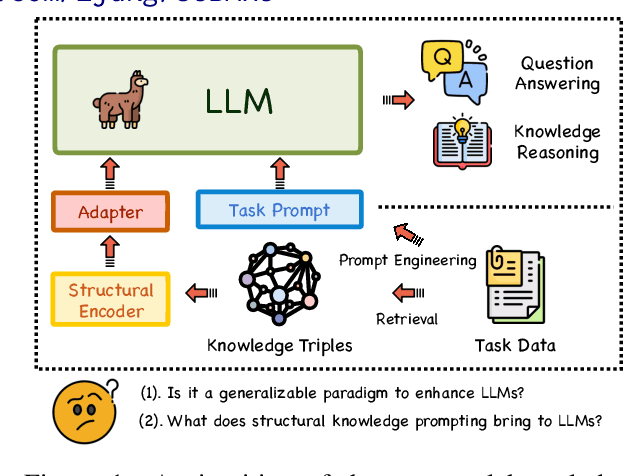
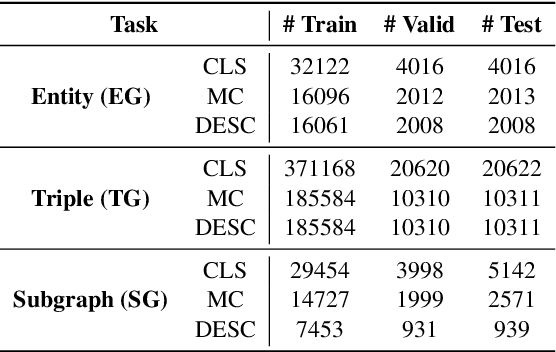
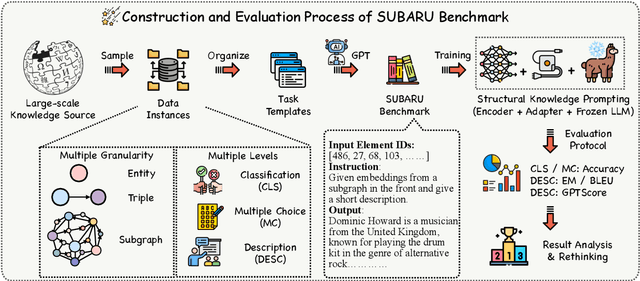
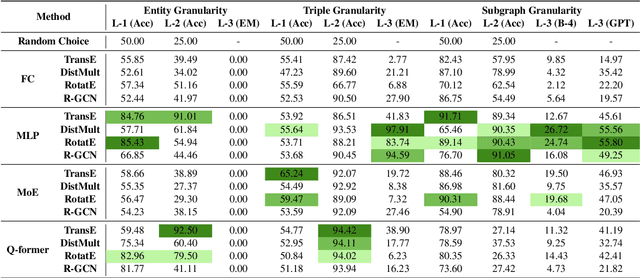
Large language models (LLMs) have demonstrated exceptional performance in text generation within current NLP research. However, the lack of factual accuracy is still a dark cloud hanging over the LLM skyscraper. Structural knowledge prompting (SKP) is a prominent paradigm to integrate external knowledge into LLMs by incorporating structural representations, achieving state-of-the-art results in many knowledge-intensive tasks. However, existing methods often focus on specific problems, lacking a comprehensive exploration of the generalization and capability boundaries of SKP. This paper aims to evaluate and rethink the generalization capability of the SKP paradigm from four perspectives including Granularity, Transferability, Scalability, and Universality. To provide a thorough evaluation, we introduce a novel multi-granular, multi-level benchmark called SUBARU, consisting of 9 different tasks with varying levels of granularity and difficulty.
Graph Disentangle Causal Model: Enhancing Causal Inference in Networked Observational Data
Dec 05, 2024



Estimating individual treatment effects (ITE) from observational data is a critical task across various domains. However, many existing works on ITE estimation overlook the influence of hidden confounders, which remain unobserved at the individual unit level. To address this limitation, researchers have utilized graph neural networks to aggregate neighbors' features to capture the hidden confounders and mitigate confounding bias by minimizing the discrepancy of confounder representations between the treated and control groups. Despite the success of these approaches, practical scenarios often treat all features as confounders and involve substantial differences in feature distributions between the treated and control groups. Confusing the adjustment and confounder and enforcing strict balance on the confounder representations could potentially undermine the effectiveness of outcome prediction. To mitigate this issue, we propose a novel framework called the \textit{Graph Disentangle Causal model} (GDC) to conduct ITE estimation in the network setting. GDC utilizes a causal disentangle module to separate unit features into adjustment and confounder representations. Then we design a graph aggregation module consisting of three distinct graph aggregators to obtain adjustment, confounder, and counterfactual confounder representations. Finally, a causal constraint module is employed to enforce the disentangled representations as true causal factors. The effectiveness of our proposed method is demonstrated by conducting comprehensive experiments on two networked datasets.
PSL: Rethinking and Improving Softmax Loss from Pairwise Perspective for Recommendation
Oct 31, 2024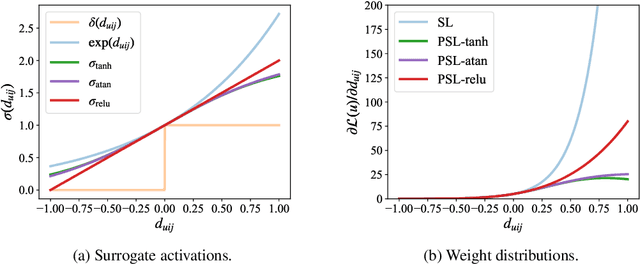
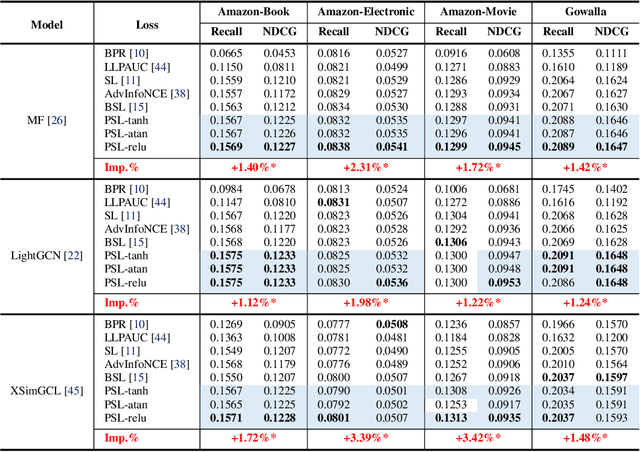
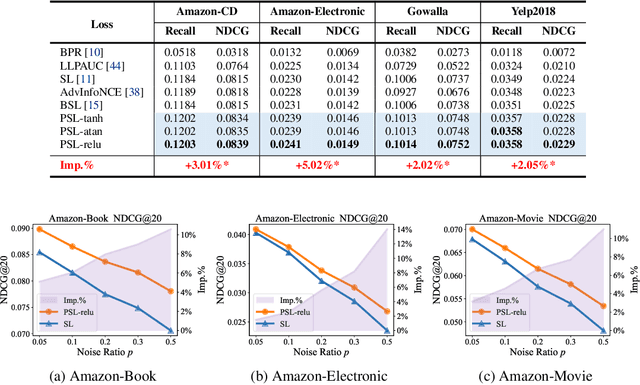
Softmax Loss (SL) is widely applied in recommender systems (RS) and has demonstrated effectiveness. This work analyzes SL from a pairwise perspective, revealing two significant limitations: 1) the relationship between SL and conventional ranking metrics like DCG is not sufficiently tight; 2) SL is highly sensitive to false negative instances. Our analysis indicates that these limitations are primarily due to the use of the exponential function. To address these issues, this work extends SL to a new family of loss functions, termed Pairwise Softmax Loss (PSL), which replaces the exponential function in SL with other appropriate activation functions. While the revision is minimal, we highlight three merits of PSL: 1) it serves as a tighter surrogate for DCG with suitable activation functions; 2) it better balances data contributions; and 3) it acts as a specific BPR loss enhanced by Distributionally Robust Optimization (DRO). We further validate the effectiveness and robustness of PSL through empirical experiments. The code is available at https://github.com/Tiny-Snow/IR-Benchmark.
The Devil is in the Sources! Knowledge Enhanced Cross-Domain Recommendation in an Information Bottleneck Perspective
Sep 29, 2024



Cross-domain Recommendation (CDR) aims to alleviate the data sparsity and the cold-start problems in traditional recommender systems by leveraging knowledge from an informative source domain. However, previously proposed CDR models pursue an imprudent assumption that the entire information from the source domain is equally contributed to the target domain, neglecting the evil part that is completely irrelevant to users' intrinsic interest. To address this concern, in this paper, we propose a novel knowledge enhanced cross-domain recommendation framework named CoTrans, which remolds the core procedures of CDR models with: Compression on the knowledge from the source domain and Transfer of the purity to the target domain. Specifically, following the theory of Graph Information Bottleneck, CoTrans first compresses the source behaviors with the perception of information from the target domain. Then to preserve all the important information for the CDR task, the feedback signals from both domains are utilized to promote the effectiveness of the transfer procedure. Additionally, a knowledge-enhanced encoder is employed to narrow gaps caused by the non-overlapped items across separate domains. Comprehensive experiments on three widely used cross-domain datasets demonstrate that CoTrans significantly outperforms both single-domain and state-of-the-art cross-domain recommendation approaches.
MSDet: Receptive Field Enhanced Multiscale Detection for Tiny Pulmonary Nodule
Sep 21, 2024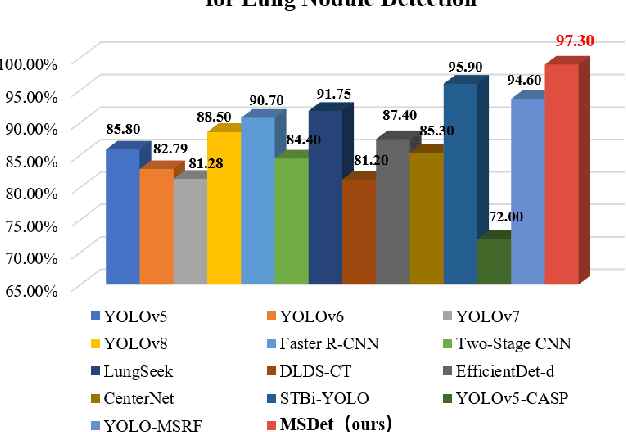
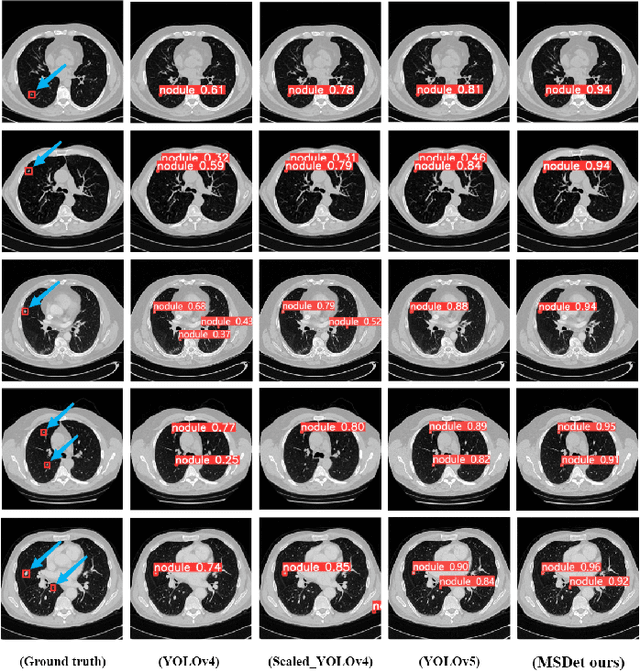
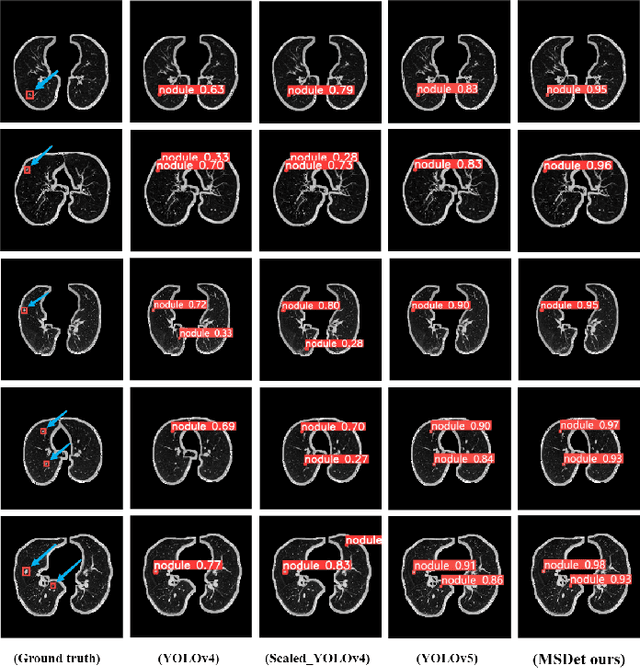
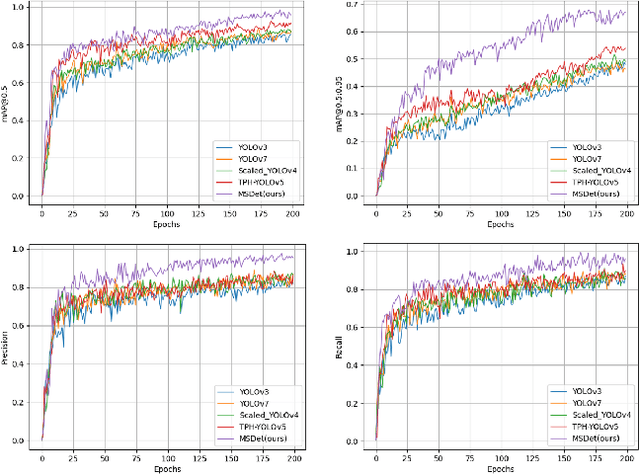
Pulmonary nodules are critical indicators for the early diagnosis of lung cancer, making their detection essential for timely treatment. However, traditional CT imaging methods suffered from cumbersome procedures, low detection rates, and poor localization accuracy. The subtle differences between pulmonary nodules and surrounding tissues in complex lung CT images, combined with repeated downsampling in feature extraction networks, often lead to missed or false detections of small nodules. Existing methods such as FPN, with its fixed feature fusion and limited receptive field, struggle to effectively overcome these issues. To address these challenges, our paper proposed three key contributions: Firstly, we proposed MSDet, a multiscale attention and receptive field network for detecting tiny pulmonary nodules. Secondly, we proposed the extended receptive domain (ERD) strategy to capture richer contextual information and reduce false positives caused by nodule occlusion. We also proposed the position channel attention mechanism (PCAM) to optimize feature learning and reduce multiscale detection errors, and designed the tiny object detection block (TODB) to enhance the detection of tiny nodules. Lastly, we conducted thorough experiments on the public LUNA16 dataset, achieving state-of-the-art performance, with an mAP improvement of 8.8% over the previous state-of-the-art method YOLOv8. These advancements significantly boosted detection accuracy and reliability, providing a more effective solution for early lung cancer diagnosis. The code will be available at https://github.com/CaiGuoHui123/MSDet
SegStitch: Multidimensional Transformer for Robust and Efficient Medical Imaging Segmentation
Aug 01, 2024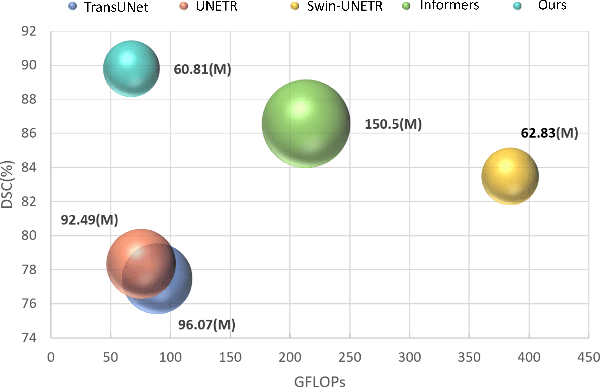

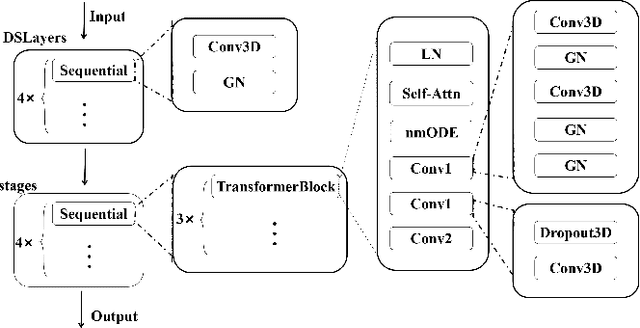
Medical imaging segmentation plays a significant role in the automatic recognition and analysis of lesions. State-of-the-art methods, particularly those utilizing transformers, have been prominently adopted in 3D semantic segmentation due to their superior performance in scalability and generalizability. However, plain vision transformers encounter challenges due to their neglect of local features and their high computational complexity. To address these challenges, we introduce three key contributions: Firstly, we proposed SegStitch, an innovative architecture that integrates transformers with denoising ODE blocks. Instead of taking whole 3D volumes as inputs, we adapt axial patches and customize patch-wise queries to ensure semantic consistency. Additionally, we conducted extensive experiments on the BTCV and ACDC datasets, achieving improvements up to 11.48% and 6.71% respectively in mDSC, compared to state-of-the-art methods. Lastly, our proposed method demonstrates outstanding efficiency, reducing the number of parameters by 36.7% and the number of FLOPS by 10.7% compared to UNETR. This advancement holds promising potential for adapting our method to real-world clinical practice. The code will be available at https://github.com/goblin327/SegStitch