 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegStitch: Multidimensional Transformer for Robust and Efficient Medical Imaging Segmentation
Aug 01, 2024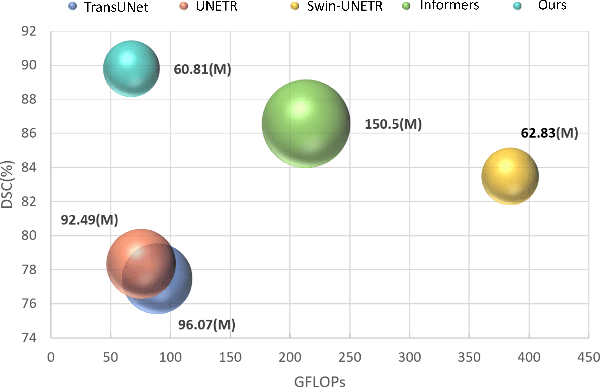

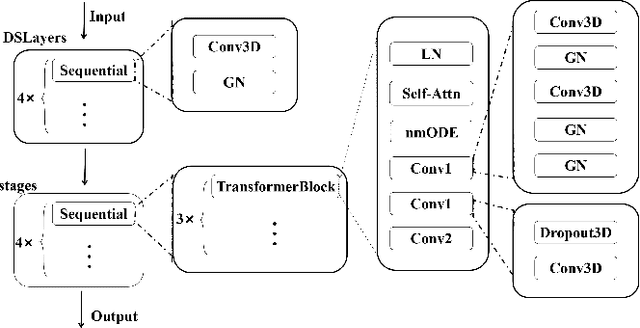
Medical imaging segmentation plays a significant role in the automatic recognition and analysis of lesions. State-of-the-art methods, particularly those utilizing transformers, have been prominently adopted in 3D semantic segmentation due to their superior performance in scalability and generalizability. However, plain vision transformers encounter challenges due to their neglect of local features and their high computational complexity. To address these challenges, we introduce three key contributions: Firstly, we proposed SegStitch, an innovative architecture that integrates transformers with denoising ODE blocks. Instead of taking whole 3D volumes as inputs, we adapt axial patches and customize patch-wise queries to ensure semantic consistency. Additionally, we conducted extensive experiments on the BTCV and ACDC datasets, achieving improvements up to 11.48% and 6.71% respectively in mDSC, compared to state-of-the-art methods. Lastly, our proposed method demonstrates outstanding efficiency, reducing the number of parameters by 36.7% and the number of FLOPS by 10.7% compared to UNETR. This advancement holds promising potential for adapting our method to real-world clinical practice. The code will be available at https://github.com/goblin327/SegStitch