 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Cell Segmentation: Benchmark and Framework for Reference-Guided Cell Type Segmentation
Mar 15, 2026Accurate cell segmentation is critical for biological and medical imaging studies. Although recent deep learning models have advanced this task, most methods are limited to generic cell segmentation, lacking the ability to differentiate specific cell types. In this work, we introduce the Personalized Cell Segmentation (PerCS) task, which aims to segment all cells of a specific type given a reference cell. To support this task, we establish a benchmark by reorganizing publicly available datasets, yielding 1,372 images and over 110,000 annotated cells. As a pioneering solution, we propose PerCS-DINO, a framework built on the DINOv2 backbone. By integrating image features and reference embeddings via a cross-attention transformer and contrastive learning, PerCS-DINO effectively segments cells matching the reference. Extensive experiments demonstrate the effectiveness of the proposed PerCS-DINO and highlight the challenges of this new task. We expect PerCS to serve as a useful testbed for advancing research in cell-based applications.
Towards a Science of Collective AI: LLM-based Multi-Agent Systems Need a Transition from Blind Trial-and-Error to Rigorous Science
Feb 05, 2026Recent advancements in Large Language Models (LLMs) have greatly extended the capabilities of Multi-Agent Systems (MAS), demonstrating significant effectiveness across a wide range of complex and open-ended domains. However, despite this rapid progress, the field still relies heavily on empirical trial-and-error. It lacks a unified and principled scientific framework necessary for systematic optimization and improvement. This bottleneck stems from the ambiguity of attribution: first, the absence of a structured taxonomy of factors leaves researchers restricted to unguided adjustments; second, the lack of a unified metric fails to distinguish genuine collaboration gain from mere resource accumulation. In this paper, we advocate for a transition to design science through an integrated framework. We advocate to establish the collaboration gain metric ($Γ$) as the scientific standard to isolate intrinsic gains from increased budgets. Leveraging $Γ$, we propose a factor attribution paradigm to systematically identify collaboration-driving factors. To support this, we construct a systematic MAS factor library, structuring the design space into control-level presets and information-level dynamics. Ultimately, this framework facilitates the transition from blind experimentation to rigorous science, paving the way towards a true science of Collective AI.
SegMo: Segment-aligned Text to 3D Human Motion Generation
Dec 24, 2025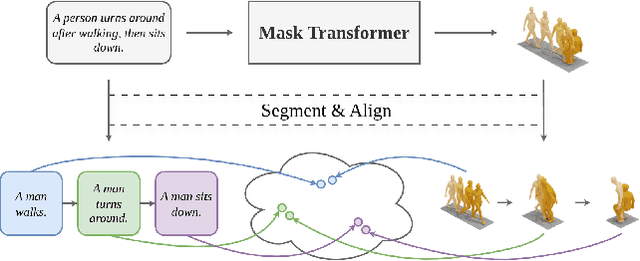
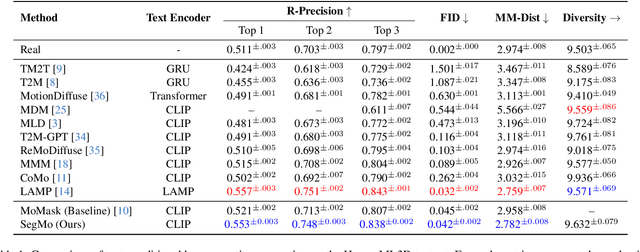
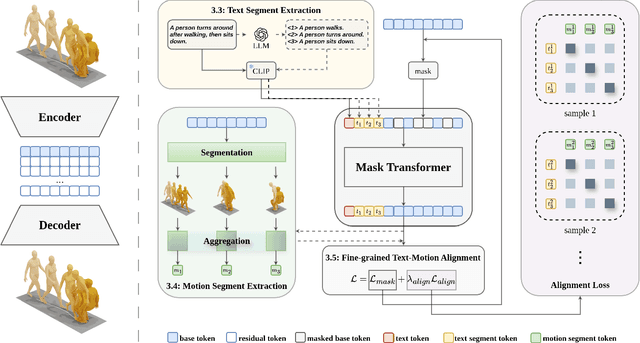
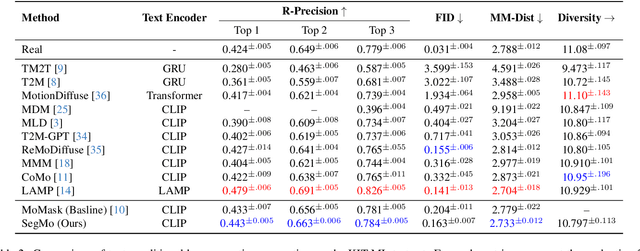
Generating 3D human motions from textual descriptions is an important research problem with broad applications in video games, virtual reality, and augmented reality. Recent methods align the textual description with human motion at the sequence level, neglecting the internal semantic structure of modalities. However, both motion descriptions and motion sequences can be naturally decomposed into smaller and semantically coherent segments, which can serve as atomic alignment units to achieve finer-grained correspondence. Motivated by this, we propose SegMo, a novel Segment-aligned text-conditioned human Motion generation framework to achieve fine-grained text-motion alignment. Our framework consists of three modules: (1) Text Segment Extraction, which decomposes complex textual descriptions into temporally ordered phrases, each representing a simple atomic action; (2) Motion Segment Extraction, which partitions complete motion sequences into corresponding motion segments; and (3) Fine-grained Text-Motion Alignment, which aligns text and motion segments with contrastive learning. Extensive experiments demonstrate that SegMo improves the strong baseline on two widely used datasets, achieving an improved TOP 1 score of 0.553 on the HumanML3D test set. Moreover, thanks to the learned shared embedding space for text and motion segments, SegMo can also be applied to retrieval-style tasks such as motion grounding and motion-to-text retrieval.
PrefPoE: Advantage-Guided Preference Fusion for Learning Where to Explore
Nov 11, 2025Exploration in reinforcement learning remains a critical challenge, as naive entropy maximization often results in high variance and inefficient policy updates. We introduce \textbf{PrefPoE}, a novel \textit{Preference-Product-of-Experts} framework that performs intelligent, advantage-guided exploration via the first principled application of product-of-experts (PoE) fusion for single-task exploration-exploitation balancing. By training a preference network to concentrate probability mass on high-advantage actions and fusing it with the main policy through PoE, PrefPoE creates a \textbf{soft trust region} that stabilizes policy updates while maintaining targeted exploration. Across diverse control tasks spanning both continuous and discrete action spaces, PrefPoE demonstrates consistent improvements: +321\% on HalfCheetah-v4 (1276~$\rightarrow$~5375), +69\% on Ant-v4, +276\% on LunarLander-v2, with consistently enhanced training stability and sample efficiency. Unlike standard PPO, which suffers from entropy collapse, PrefPoE sustains adaptive exploration through its unique dynamics, thereby preventing premature convergence and enabling superior performance. Our results establish that learning \textit{where to explore} through advantage-guided preferences is as crucial as learning how to act, offering a general framework for enhancing policy gradient methods across the full spectrum of reinforcement learning domains. Code and pretrained models are available in supplementary materials.
HOI-Dyn: Learning Interaction Dynamics for Human-Object Motion Diffusion
Jul 03, 2025Generating realistic 3D human-object interactions (HOIs) remains a challenging task due to the difficulty of modeling detailed interaction dynamics. Existing methods treat human and object motions independently, resulting in physically implausible and causally inconsistent behaviors. In this work, we present HOI-Dyn, a novel framework that formulates HOI generation as a driver-responder system, where human actions drive object responses. At the core of our method is a lightweight transformer-based interaction dynamics model that explicitly predicts how objects should react to human motion. To further enforce consistency, we introduce a residual-based dynamics loss that mitigates the impact of dynamics prediction errors and prevents misleading optimization signals. The dynamics model is used only during training, preserving inference efficiency. Through extensive qualitative and quantitative experiments, we demonstrate that our approach not only enhances the quality of HOI generation but also establishes a feasible metric for evaluating the quality of generated interactions.
Referring to Any Person
Mar 11, 2025
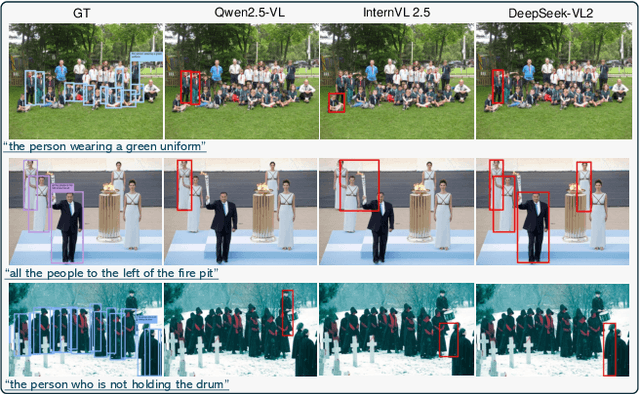
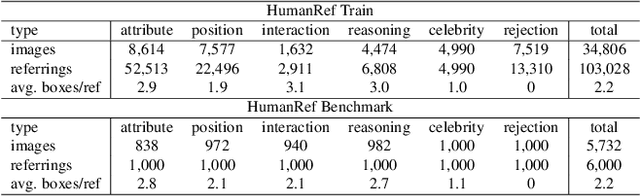
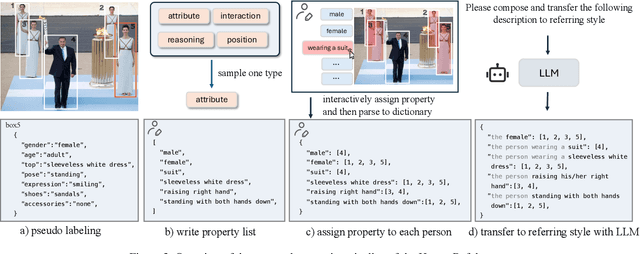
Humans are undoubtedly the most important participants in computer vision, and the ability to detect any individual given a natural language description, a task we define as referring to any person, holds substantial practical value. However, we find that existing models generally fail to achieve real-world usability, and current benchmarks are limited by their focus on one-to-one referring, that hinder progress in this area. In this work, we revisit this task from three critical perspectives: task definition, dataset design, and model architecture. We first identify five aspects of referable entities and three distinctive characteristics of this task. Next, we introduce HumanRef, a novel dataset designed to tackle these challenges and better reflect real-world applications. From a model design perspective, we integrate a multimodal large language model with an object detection framework, constructing a robust referring model named RexSeek. Experimental results reveal that state-of-the-art models, which perform well on commonly used benchmarks like RefCOCO/+/g, struggle with HumanRef due to their inability to detect multiple individuals. In contrast, RexSeek not only excels in human referring but also generalizes effectively to common object referring, making it broadly applicable across various perception tasks. Code is available at https://github.com/IDEA-Research/RexSeek
Refining CNN-based Heatmap Regression with Gradient-based Corner Points for Electrode Localization
Dec 24, 2024We propose a method for detecting the electrode positions in lithium-ion batteries. The process begins by identifying the region of interest (ROI) in the battery's X-ray image through corner point detection. A convolutional neural network is then used to regress the pole positions within this ROI. Finally, the regressed positions are optimized and corrected using corner point priors, significantly mitigating the loss of localization accuracy caused by operations such as feature map down-sampling and padding during network training. Our findings show that combining traditional pixel gradient analysis with CNN-based heatmap regression for keypoint extraction enhances both accuracy and efficiency, resulting in significant performance improvements.
UIFormer: A Unified Transformer-based Framework for Incremental Few-Shot Object Detection and Instance Segmentation
Nov 13, 2024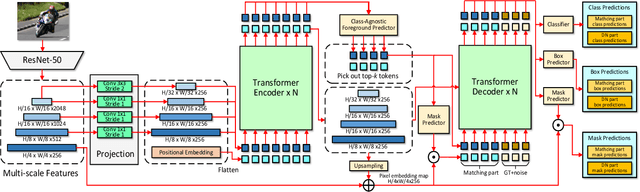



This paper introduces a novel framework for unified incremental few-shot object detection (iFSOD) and instance segmentation (iFSIS) using the Transformer architecture. Our goal is to create an optimal solution for situations where only a few examples of novel object classes are available, with no access to training data for base or old classes, while maintaining high performance across both base and novel classes. To achieve this, We extend Mask-DINO into a two-stage incremental learning framework. Stage 1 focuses on optimizing the model using the base dataset, while Stage 2 involves fine-tuning the model on novel classes. Besides, we incorporate a classifier selection strategy that assigns appropriate classifiers to the encoder and decoder according to their distinct functions. Empirical evidence indicates that this approach effectively mitigates the over-fitting on novel classes learning. Furthermore, we implement knowledge distillation to prevent catastrophic forgetting of base classes. Comprehensive evaluations on the COCO and LVIS datasets for both iFSIS and iFSOD tasks demonstrate that our method significantly outperforms state-of-the-art approaches.
Medical AI for Early Detection of Lung Cancer: A Survey
Oct 18, 2024



Lung cancer remains one of the leading causes of morbidity and mortality worldwide, making early diagnosis critical for improving therapeutic outcomes and patient prognosis. Computer-aided diagnosis (CAD) systems, which analyze CT images, have proven effective in detecting and classifying pulmonary nodules, significantly enhancing the detection rate of early-stage lung cancer. Although traditional machine learning algorithms have been valuable, they exhibit limitations in handling complex sample data. The recent emergence of deep learning has revolutionized medical image analysis, driving substantial advancements in this field. This review focuses on recent progress in deep learning for pulmonary nodule detection, segmentation, and classification. Traditional machine learning methods, such as SVM and KNN, have shown limitations, paving the way for advanced approaches like Convolutional Neural Networks (CNN), Recurrent Neural Networks (RNN), and Generative Adversarial Networks (GAN). The integration of ensemble models and novel techniques is also discussed, emphasizing the latest developments in lung cancer diagnosis. Deep learning algorithms, combined with various analytical techniques, have markedly improved the accuracy and efficiency of pulmonary nodule analysis, surpassing traditional methods, particularly in nodule classification. Although challenges remain, continuous technological advancements are expected to further strengthen the role of deep learning in medical diagnostics, especially for early lung cancer detection and diagnosis. A comprehensive list of lung cancer detection models reviewed in this work is available at https://github.com/CaiGuoHui123/Awesome-Lung-Cancer-Detection
SegStitch: Multidimensional Transformer for Robust and Efficient Medical Imaging Segmentation
Aug 01, 2024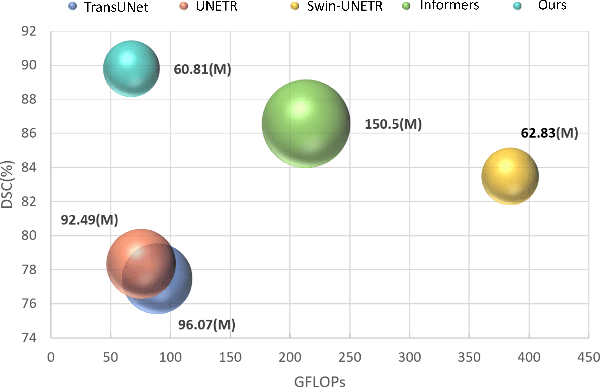

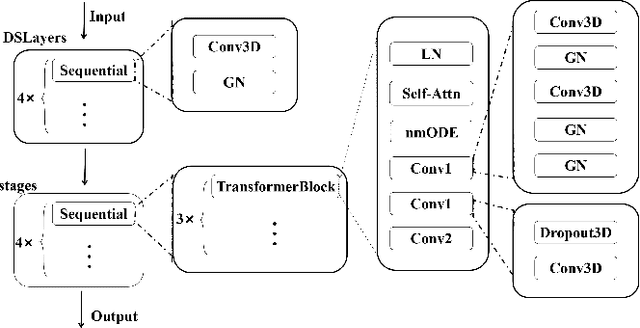
Medical imaging segmentation plays a significant role in the automatic recognition and analysis of lesions. State-of-the-art methods, particularly those utilizing transformers, have been prominently adopted in 3D semantic segmentation due to their superior performance in scalability and generalizability. However, plain vision transformers encounter challenges due to their neglect of local features and their high computational complexity. To address these challenges, we introduce three key contributions: Firstly, we proposed SegStitch, an innovative architecture that integrates transformers with denoising ODE blocks. Instead of taking whole 3D volumes as inputs, we adapt axial patches and customize patch-wise queries to ensure semantic consistency. Additionally, we conducted extensive experiments on the BTCV and ACDC datasets, achieving improvements up to 11.48% and 6.71% respectively in mDSC, compared to state-of-the-art methods. Lastly, our proposed method demonstrates outstanding efficiency, reducing the number of parameters by 36.7% and the number of FLOPS by 10.7% compared to UNETR. This advancement holds promising potential for adapting our method to real-world clinical practice. The code will be available at https://github.com/goblin327/SegStitch