 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA cross-modal network for facial expression recognition
May 06, 2026Deep neural networks enriched with structural information have been widely employed for facial expression recognition tasks. However, these methods often depend on hierarchical information rather than face property to finish expression recognition. In this paper, we propose a cross-modal network with strong biological and structural information for facial expression recognition (CMNet). CMNet can respectively learn expression information via face symmetry on a whole face, left and right half faces to extract complementary facial features. To prevent negative effect of biological and structural information fusion, a salient facial information refinement module can obtain salient facial expression information to improve stability of an obtained facial expression classifier. To reduce reliance on unilateral facial features, a half-face alignment optimization mechanism is designed to align obtained expression information of learned left and right half faces. Our experimental results demonstrate that CMNet outperforms several novel methods, i.e., SCN and LAENet-SA for facial expression recognition. Codes can be obtained at https://github.com/hellloxiaotian/CMNet.
Dehallu3D: Hallucination-Mitigated 3D Generation from Single Image via Cyclic View Consistency Refinement
Mar 02, 2026Large 3D reconstruction models have revolutionized the 3D content generation field, enabling broad applications in virtual reality and gaming. Just like other large models, large 3D reconstruction models suffer from hallucinations as well, introducing structural outliers (e.g., odd holes or protrusions) that deviate from the input data. However, unlike other large models, hallucinations in large 3D reconstruction models remain severely underexplored, leading to malformed 3D-printed objects or insufficient immersion in virtual scenes. Such hallucinations majorly originate from that existing methods reconstruct 3D content from sparsely generated multi-view images which suffer from large viewpoint gaps and discontinuities. To mitigate hallucinations by eliminating the outliers, we propose Dehallu3D for 3D mesh generation. Our key idea is to design a balanced multi-view continuity constraint to enforce smooth transitions across dense intermediate viewpoints, while avoiding over-smoothing that could erase sharp geometric features. Therefore, Dehallu3D employs a plug-and-play optimization module with two key constraints: (i) adjacent consistency to ensure geometric continuity across views, and (ii) adaptive smoothness to retain fine details.We further propose the Outlier Risk Measure (ORM) metric to quantify geometric fidelity in 3D generation from the perspective of outliers. Extensive experiments show that Dehallu3D achieves high-fidelity 3D generation by effectively preserving structural details while removing hallucinated outliers.
Disentangled Instrumental Variables for Causal Inference with Networked Observational Data
Feb 08, 2026Instrumental variables (IVs) are crucial for addressing unobservable confounders, yet their stringent exogeneity assumptions pose significant challenges in networked data. Existing methods typically rely on modelling neighbour information when recovering IVs, thereby inevitably mixing shared environment-induced endogenous correlations and individual-specific exogenous variation, leading the resulting IVs to inherit dependence on unobserved confounders and to violate exogeneity. To overcome this challenge, we propose $\underline{Dis}$entangled $\underline{I}$nstrumental $\underline{V}$ariables (DisIV) framework, a novel method for causal inference based on networked observational data with latent confounders. DisIV exploits network homogeneity as an inductive bias and employs a structural disentanglement mechanism to extract individual-specific components that serve as latent IVs. The causal validity of the extracted IVs is constrained through explicit orthogonality and exclusion conditions. Extensive semi-synthetic experiments on real-world datasets demonstrate that DisIV consistently outperforms state-of-the-art baselines in causal effect estimation under network-induced confounding.
kNN-Graph: An adaptive graph model for $k$-nearest neighbors
Jan 23, 2026The k-nearest neighbors (kNN) algorithm is a cornerstone of non-parametric classification in artificial intelligence, yet its deployment in large-scale applications is persistently constrained by the computational trade-off between inference speed and accuracy. Existing approximate nearest neighbor solutions accelerate retrieval but often degrade classification precision and lack adaptability in selecting the optimal neighborhood size (k). Here, we present an adaptive graph model that decouples inference latency from computational complexity. By integrating a Hierarchical Navigable Small World (HNSW) graph with a pre-computed voting mechanism, our framework completely transfers the computational burden of neighbor selection and weighting to the training phase. Within this topological structure, higher graph layers enable rapid navigation, while lower layers encode precise, node-specific decision boundaries with adaptive neighbor counts. Benchmarking against eight state-of-the-art baselines across six diverse datasets, we demonstrate that this architecture significantly accelerates inference speeds, achieving real-time performance, without compromising classification accuracy. These findings offer a scalable, robust solution to the long-standing inference bottleneck of kNN, establishing a new structural paradigm for graph-based nonparametric learning.
DeNoise: Learning Robust Graph Representations for Unsupervised Graph-Level Anomaly Detection
Nov 06, 2025With the rapid growth of graph-structured data in critical domains, unsupervised graph-level anomaly detection (UGAD) has become a pivotal task. UGAD seeks to identify entire graphs that deviate from normal behavioral patterns. However, most Graph Neural Network (GNN) approaches implicitly assume that the training set is clean, containing only normal graphs, which is rarely true in practice. Even modest contamination by anomalous graphs can distort learned representations and sharply degrade performance. To address this challenge, we propose DeNoise, a robust UGAD framework explicitly designed for contaminated training data. It jointly optimizes a graph-level encoder, an attribute decoder, and a structure decoder via an adversarial objective to learn noise-resistant embeddings. Further, DeNoise introduces an encoder anchor-alignment denoising mechanism that fuses high-information node embeddings from normal graphs into all graph embeddings, improving representation quality while suppressing anomaly interference. A contrastive learning component then compacts normal graph embeddings and repels anomalous ones in the latent space. Extensive experiments on eight real-world datasets demonstrate that DeNoise consistently learns reliable graph-level representations under varying noise intensities and significantly outperforms state-of-the-art UGAD baselines.
Uncertainty-Aware Graph Neural Networks: A Multi-Hop Evidence Fusion Approach
Jun 16, 2025Graph neural networks (GNNs) excel in graph representation learning by integrating graph structure and node features. Existing GNNs, unfortunately, fail to account for the uncertainty of class probabilities that vary with the depth of the model, leading to unreliable and risky predictions in real-world scenarios. To bridge the gap, in this paper, we propose a novel Evidence Fusing Graph Neural Network (EFGNN for short) to achieve trustworthy prediction, enhance node classification accuracy, and make explicit the risk of wrong predictions. In particular, we integrate the evidence theory with multi-hop propagation-based GNN architecture to quantify the prediction uncertainty of each node with the consideration of multiple receptive fields. Moreover, a parameter-free cumulative belief fusion (CBF) mechanism is developed to leverage the changes in prediction uncertainty and fuse the evidence to improve the trustworthiness of the final prediction. To effectively optimize the EFGNN model, we carefully design a joint learning objective composed of evidence cross-entropy, dissonance coefficient, and false confident penalty. The experimental results on various datasets and theoretical analyses demonstrate the effectiveness of the proposed model in terms of accuracy and trustworthiness, as well as its robustness to potential attacks. The source code of EFGNN is available at https://github.com/Shiy-Li/EFGNN.
A Novel Generative Model with Causality Constraint for Mitigating Biases in Recommender Systems
May 22, 2025Accurately predicting counterfactual user feedback is essential for building effective recommender systems. However, latent confounding bias can obscure the true causal relationship between user feedback and item exposure, ultimately degrading recommendation performance. Existing causal debiasing approaches often rely on strong assumptions-such as the availability of instrumental variables (IVs) or strong correlations between latent confounders and proxy variables-that are rarely satisfied in real-world scenarios. To address these limitations, we propose a novel generative framework called Latent Causality Constraints for Debiasing representation learning in Recommender Systems (LCDR). Specifically, LCDR leverages an identifiable Variational Autoencoder (iVAE) as a causal constraint to align the latent representations learned by a standard Variational Autoencoder (VAE) through a unified loss function. This alignment allows the model to leverage even weak or noisy proxy variables to recover latent confounders effectively. The resulting representations are then used to improve recommendation performance. Extensive experiments on three real-world datasets demonstrate that LCDR consistently outperforms existing methods in both mitigating bias and improving recommendation accuracy.
Generative Physical AI in Vision: A Survey
Jan 19, 2025



Generative Artificial Intelligence (AI) has rapidly advanced the field of computer vision by enabling machines to create and interpret visual data with unprecedented sophistication. This transformation builds upon a foundation of generative models to produce realistic images, videos, and 3D or 4D content. Traditionally, generative models primarily focus on visual fidelity while often neglecting the physical plausibility of generated content. This gap limits their effectiveness in applications requiring adherence to real-world physical laws, such as robotics, autonomous systems, and scientific simulations. As generative AI evolves to increasingly integrate physical realism and dynamic simulation, its potential to function as a "world simulator" expands-enabling the modeling of interactions governed by physics and bridging the divide between virtual and physical realities. This survey systematically reviews this emerging field of physics-aware generative AI in computer vision, categorizing methods based on how they incorporate physical knowledge-either through explicit simulation or implicit learning. We analyze key paradigms, discuss evaluation protocols, and identify future research directions. By offering a comprehensive overview, this survey aims to help future developments in physically grounded generation for vision. The reviewed papers are summarized at https://github.com/BestJunYu/Awesome-Physics-aware-Generation.
Toward Fair Graph Neural Networks Via Dual-Teacher Knowledge Distillation
Nov 30, 2024Graph Neural Networks (GNNs) have demonstrated strong performance in graph representation learning across various real-world applications. However, they often produce biased predictions caused by sensitive attributes, such as religion or gender, an issue that has been largely overlooked in existing methods. Recently, numerous studies have focused on reducing biases in GNNs. However, these approaches often rely on training with partial data (e.g., using either node features or graph structure alone), which can enhance fairness but frequently compromises model utility due to the limited utilization of available graph information. To address this tradeoff, we propose an effective strategy to balance fairness and utility in knowledge distillation. Specifically, we introduce FairDTD, a novel Fair representation learning framework built on Dual-Teacher Distillation, leveraging a causal graph model to guide and optimize the design of the distillation process. Specifically, FairDTD employs two fairness-oriented teacher models: a feature teacher and a structure teacher, to facilitate dual distillation, with the student model learning fairness knowledge from the teachers while also leveraging full data to mitigate utility loss. To enhance information transfer, we incorporate graph-level distillation to provide an indirect supplement of graph information during training, as well as a node-specific temperature module to improve the comprehensive transfer of fair knowledge. Experiments on diverse benchmark datasets demonstrate that FairDTD achieves optimal fairness while preserving high model utility, showcasing its effectiveness in fair representation learning for GNNs.
Leaning Time-Varying Instruments for Identifying Causal Effects in Time-Series Data
Nov 26, 2024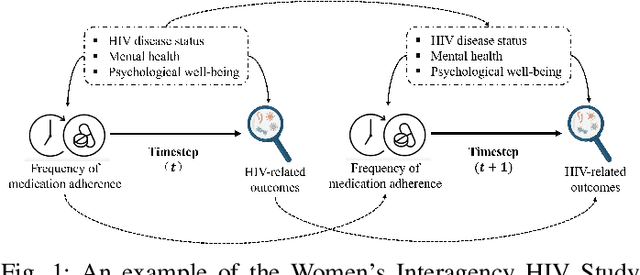
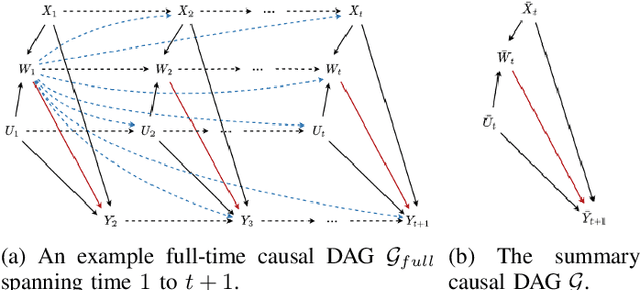
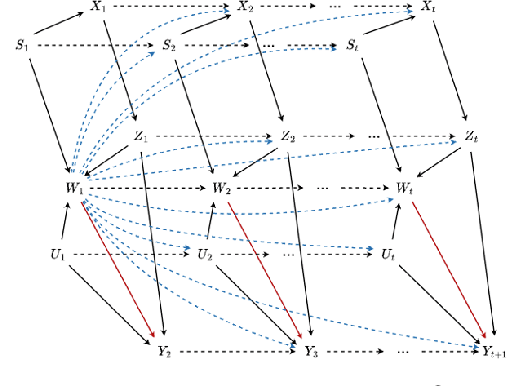
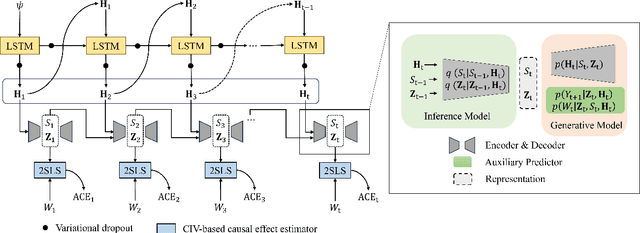
Querying causal effects from time-series data is important across various fields, including healthcare, economics, climate science, and epidemiology. However, this task becomes complex in the existence of time-varying latent confounders, which affect both treatment and outcome variables over time and can introduce bias in causal effect estimation. Traditional instrumental variable (IV) methods are limited in addressing such complexities due to the need for predefined IVs or strong assumptions that do not hold in dynamic settings. To tackle these issues, we develop a novel Time-varying Conditional Instrumental Variables (CIV) for Debiasing causal effect estimation, referred to as TDCIV. TDCIV leverages Long Short-Term Memory (LSTM) and Variational Autoencoder (VAE) models to disentangle and learn the representations of time-varying CIV and its conditioning set from proxy variables without prior knowledge. Under the assumptions of the Markov property and availability of proxy variables, we theoretically establish the validity of these learned representations for addressing the biases from time-varying latent confounders, thus enabling accurate causal effect estimation. Our proposed TDCIV is the first to effectively learn time-varying CIV and its associated conditioning set without relying on domain-specific knowledge.