 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond a Single Perspective: Text Anomaly Detection with Multi-View Language Representations
Jan 25, 2026Text anomaly detection (TAD) plays a critical role in various language-driven real-world applications, including harmful content moderation, phishing detection, and spam review filtering. While two-step "embedding-detector" TAD methods have shown state-of-the-art performance, their effectiveness is often limited by the use of a single embedding model and the lack of adaptability across diverse datasets and anomaly types. To address these limitations, we propose to exploit the embeddings from multiple pretrained language models and integrate them into $MCA^2$, a multi-view TAD framework. $MCA^2$ adopts a multi-view reconstruction model to effectively extract normal textual patterns from multiple embedding perspectives. To exploit inter-view complementarity, a contrastive collaboration module is designed to leverage and strengthen the interactions across different views. Moreover, an adaptive allocation module is developed to automatically assign the contribution weight of each view, thereby improving the adaptability to diverse datasets. Extensive experiments on 10 benchmark datasets verify the effectiveness of $MCA^2$ against strong baselines. The source code of $MCA^2$ is available at https://github.com/yankehan/MCA2.
OFA-MAS: One-for-All Multi-Agent System Topology Design based on Mixture-of-Experts Graph Generative Models
Jan 19, 2026Multi-Agent Systems (MAS) offer a powerful paradigm for solving complex problems, yet their performance is critically dependent on the design of their underlying collaboration topology. As MAS become increasingly deployed in web services (e.g., search engines), designing adaptive topologies for diverse cross-domain user queries becomes essential. Current graph learning-based design methodologies often adhere to a "one-for-one" paradigm, where a specialized model is trained for each specific task domain. This approach suffers from poor generalization to unseen domains and fails to leverage shared structural knowledge across different tasks. To address this, we propose OFA-TAD, a one-for-all framework that generates adaptive collaboration graphs for any task described in natural language through a single universal model. Our approach integrates a Task-Aware Graph State Encoder (TAGSE) that filters task-relevant node information via sparse gating, and a Mixture-of-Experts (MoE) architecture that dynamically selects specialized sub-networks to drive node and edge prediction. We employ a three-stage training strategy: unconditional pre-training on canonical topologies for structural priors, large-scale conditional pre-training on LLM-generated datasets for task-topology mappings, and supervised fine-tuning on empirically validated graphs. Experiments across six diverse benchmarks show that OFA-TAD significantly outperforms specialized one-for-one models, generating highly adaptive MAS topologies. Code: https://github.com/Shiy-Li/OFA-MAS.
Uncertainty-Aware Graph Neural Networks: A Multi-Hop Evidence Fusion Approach
Jun 16, 2025Graph neural networks (GNNs) excel in graph representation learning by integrating graph structure and node features. Existing GNNs, unfortunately, fail to account for the uncertainty of class probabilities that vary with the depth of the model, leading to unreliable and risky predictions in real-world scenarios. To bridge the gap, in this paper, we propose a novel Evidence Fusing Graph Neural Network (EFGNN for short) to achieve trustworthy prediction, enhance node classification accuracy, and make explicit the risk of wrong predictions. In particular, we integrate the evidence theory with multi-hop propagation-based GNN architecture to quantify the prediction uncertainty of each node with the consideration of multiple receptive fields. Moreover, a parameter-free cumulative belief fusion (CBF) mechanism is developed to leverage the changes in prediction uncertainty and fuse the evidence to improve the trustworthiness of the final prediction. To effectively optimize the EFGNN model, we carefully design a joint learning objective composed of evidence cross-entropy, dissonance coefficient, and false confident penalty. The experimental results on various datasets and theoretical analyses demonstrate the effectiveness of the proposed model in terms of accuracy and trustworthiness, as well as its robustness to potential attacks. The source code of EFGNN is available at https://github.com/Shiy-Li/EFGNN.
B2LoRa: Boosting LoRa Transmission for Satellite-IoT Systems with Blind Coherent Combining
May 30, 2025With the rapid growth of Low Earth Orbit (LEO) satellite networks, satellite-IoT systems using the LoRa technique have been increasingly deployed to provide widespread Internet services to low-power and low-cost ground devices. However, the long transmission distance and adverse environments from IoT satellites to ground devices pose a huge challenge to link reliability, as evidenced by the measurement results based on our real-world setup. In this paper, we propose a blind coherent combining design named B2LoRa to boost LoRa transmission performance. The intuition behind B2LoRa is to leverage the repeated broadcasting mechanism inherent in satellite-IoT systems to achieve coherent combining under the low-power and low-cost constraints, where each re-transmission at different times is regarded as the same packet transmitted from different antenna elements within an antenna array. Then, the problem is translated into aligning these packets at a fine granularity despite the time, frequency, and phase offsets between packets in the case of frequent packet loss. To overcome this challenge, we present three designs - joint packet sniffing, frequency shift alignment, and phase drift mitigation to deal with ultra-low SNRs and Doppler shifts featured in satellite-IoT systems, respectively. Finally, experiment results based on our real-world deployments demonstrate the high efficiency of B2LoRa.
Phased Array Calibration based on Rotating-Element Harmonic Electric-Field Vector with Time Modulation
Apr 17, 2025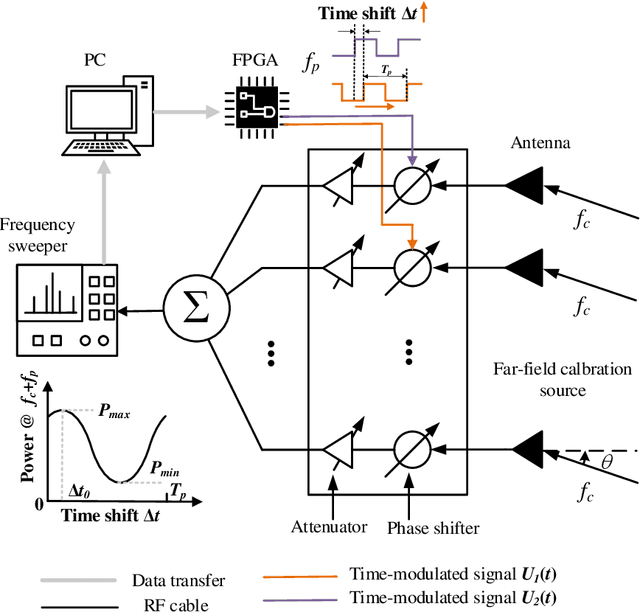
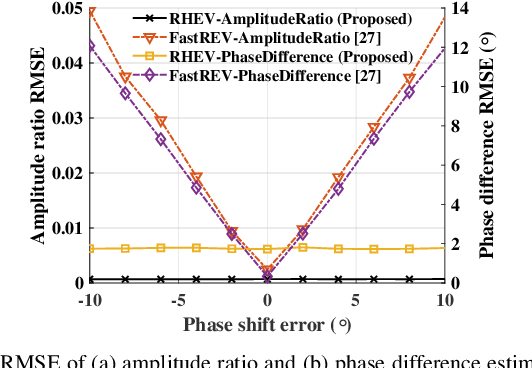
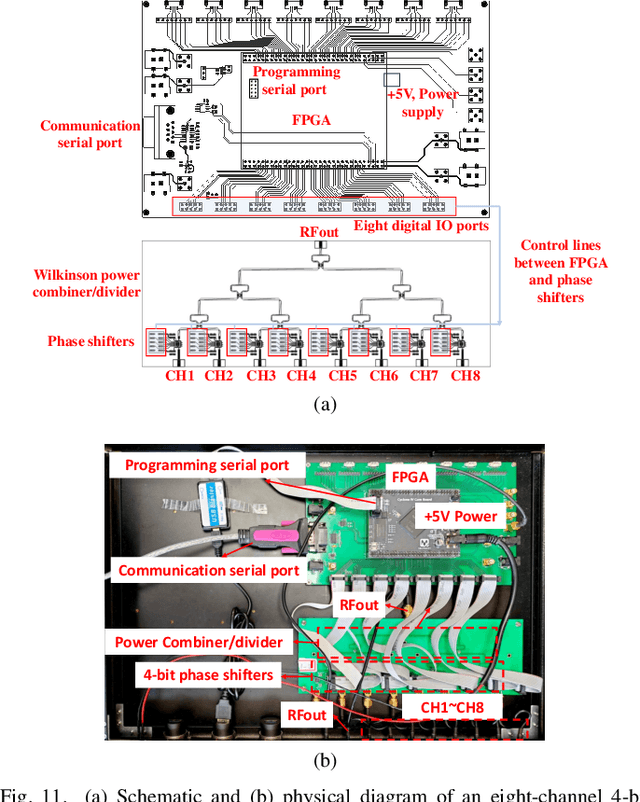
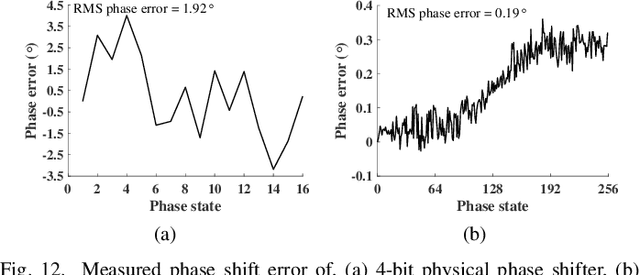
Calibration is crucial for ensuring the performance of phased array since amplitude-phase imbalance between elements results in significant performance degradation. While amplitude-only calibration methods offer advantages when phase measurements are impractical, conventional approaches face two key challenges: they typically require high-resolution phase shifters and remain susceptible to phase errors inherent in these components. To overcome these limitations, we propose a Rotating element Harmonic Electric-field Vector (RHEV) strategy, which enables precise calibration through time modulation principles. The proposed technique functions as follows. Two 1-bit phase shifters are periodically phase-switched at the same frequency, each generating corresponding harmonics. By adjusting the relative delay between their modulation timings, the phase difference between the $+1$st harmonics produced by the two elements can be precisely controlled, utilizing the time-shift property of the Fourier transform. Furthermore, the +1st harmonic generated by sequential modulation of individual elements exhibits a linear relationship with the amplitude of the modulated element, enabling amplitude ambiguity resolution. The proposed RHEV-based calibration method generates phase shifts through relative timing delays rather than physical phase shifter adjustments, rendering it less susceptible to phase shift errors. Additionally, since the calibration process exclusively utilizes the $+1$st harmonic, which is produced solely by the modulated unit, the method demonstrates consistent performance regardless of array size. Extensive numerical simulations, practical in-channel and over-the-air (OTA) calibration experiments demonstrate the effectiveness and distinct advantages of the proposed method.
Noise-Resilient Unsupervised Graph Representation Learning via Multi-Hop Feature Quality Estimation
Jul 29, 2024



Unsupervised graph representation learning (UGRL) based on graph neural networks (GNNs), has received increasing attention owing to its efficacy in handling graph-structured data. However, existing UGRL methods ideally assume that the node features are noise-free, which makes them fail to distinguish between useful information and noise when applied to real data with noisy features, thus affecting the quality of learned representations. This urges us to take node noisy features into account in real-world UGRL. With empirical analysis, we reveal that feature propagation, the essential operation in GNNs, acts as a "double-edged sword" in handling noisy features - it can both denoise and diffuse noise, leading to varying feature quality across nodes, even within the same node at different hops. Building on this insight, we propose a novel UGRL method based on Multi-hop feature Quality Estimation (MQE for short). Unlike most UGRL models that directly utilize propagation-based GNNs to generate representations, our approach aims to learn representations through estimating the quality of propagated features at different hops. Specifically, we introduce a Gaussian model that utilizes a learnable "meta-representation" as a condition to estimate the expectation and variance of multi-hop propagated features via neural networks. In this way, the "meta representation" captures the semantic and structural information underlying multiple propagated features but is naturally less susceptible to interference by noise, thereby serving as high-quality node representations beneficial for downstream tasks. Extensive experiments on multiple real-world datasets demonstrate that MQE in learning reliable node representations in scenarios with diverse types of feature noise.
ARC: A Generalist Graph Anomaly Detector with In-Context Learning
May 27, 2024

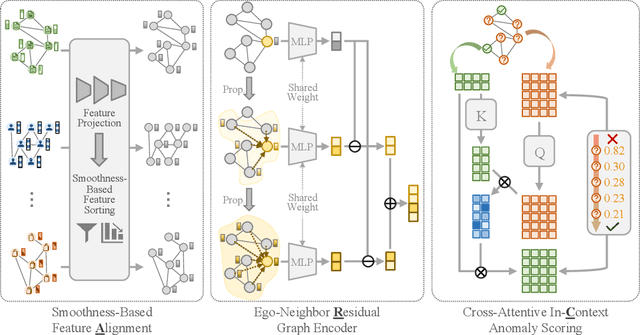
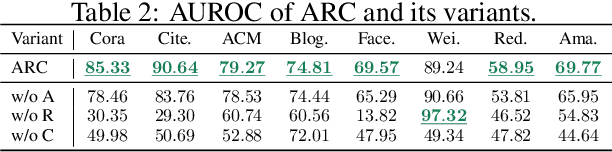
Graph anomaly detection (GAD), which aims to identify abnormal nodes that differ from the majority within a graph, has garnered significant attention. However, current GAD methods necessitate training specific to each dataset, resulting in high training costs, substantial data requirements, and limited generalizability when being applied to new datasets and domains. To address these limitations, this paper proposes ARC, a generalist GAD approach that enables a ``one-for-all'' GAD model to detect anomalies across various graph datasets on-the-fly. Equipped with in-context learning, ARC can directly extract dataset-specific patterns from the target dataset using few-shot normal samples at the inference stage, without the need for retraining or fine-tuning on the target dataset. ARC comprises three components that are well-crafted for capturing universal graph anomaly patterns: 1) smoothness-based feature Alignment module that unifies the features of different datasets into a common and anomaly-sensitive space; 2) ego-neighbor Residual graph encoder that learns abnormality-related node embeddings; and 3) cross-attentive in-Context anomaly scoring module that predicts node abnormality by leveraging few-shot normal samples. Extensive experiments on multiple benchmark datasets from various domains demonstrate the superior anomaly detection performance, efficiency, and generalizability of ARC.
MSTDP: A More Biologically Plausible Learning
Nov 29, 2019
Spike-timing dependent plasticity (STDP) which observed in the brain has proven to be important in biological learning. On the other hand, artificial neural networks use a different way to learn, such as Back-Propagation or Contrastive Hebbian Learning. In this work, we propose MSTDP, a new framework that uses only STDP rules for supervised and unsupervised learning. The framework works like an auto-encoder by making each input neuron also an output neuron. It can make predictions or generate patterns in one model without additional configuration. We also brought a new iterative inference method using momentum to make the framework more efficient, which can be used in training and testing phases. Finally, we verified our framework on MNIST dataset for classification and generation task.
Rotation Invariance Neural Network
Jun 17, 2017



Rotation invariance and translation invariance have great values in image recognition tasks. In this paper, we bring a new architecture in convolutional neural network (CNN) named cyclic convolutional layer to achieve rotation invariance in 2-D symbol recognition. We can also get the position and orientation of the 2-D symbol by the network to achieve detection purpose for multiple non-overlap target. Last but not least, this architecture can achieve one-shot learning in some cases using those invariance.