 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeB2LoRa: Boosting LoRa Transmission for Satellite-IoT Systems with Blind Coherent Combining
May 30, 2025With the rapid growth of Low Earth Orbit (LEO) satellite networks, satellite-IoT systems using the LoRa technique have been increasingly deployed to provide widespread Internet services to low-power and low-cost ground devices. However, the long transmission distance and adverse environments from IoT satellites to ground devices pose a huge challenge to link reliability, as evidenced by the measurement results based on our real-world setup. In this paper, we propose a blind coherent combining design named B2LoRa to boost LoRa transmission performance. The intuition behind B2LoRa is to leverage the repeated broadcasting mechanism inherent in satellite-IoT systems to achieve coherent combining under the low-power and low-cost constraints, where each re-transmission at different times is regarded as the same packet transmitted from different antenna elements within an antenna array. Then, the problem is translated into aligning these packets at a fine granularity despite the time, frequency, and phase offsets between packets in the case of frequent packet loss. To overcome this challenge, we present three designs - joint packet sniffing, frequency shift alignment, and phase drift mitigation to deal with ultra-low SNRs and Doppler shifts featured in satellite-IoT systems, respectively. Finally, experiment results based on our real-world deployments demonstrate the high efficiency of B2LoRa.
Modeling Multi-aspect Preferences and Intents for Multi-behavioral Sequential Recommendation
Sep 26, 2023Multi-behavioral sequential recommendation has recently attracted increasing attention. However, existing methods suffer from two major limitations. Firstly, user preferences and intents can be described in fine-grained detail from multiple perspectives; yet, these methods fail to capture their multi-aspect nature. Secondly, user behaviors may contain noises, and most existing methods could not effectively deal with noises. In this paper, we present an attentive recurrent model with multiple projections to capture Multi-Aspect preferences and INTents (MAINT in short). To extract multi-aspect preferences from target behaviors, we propose a multi-aspect projection mechanism for generating multiple preference representations from multiple aspects. To extract multi-aspect intents from multi-typed behaviors, we propose a behavior-enhanced LSTM and a multi-aspect refinement attention mechanism. The attention mechanism can filter out noises and generate multiple intent representations from different aspects. To adaptively fuse user preferences and intents, we propose a multi-aspect gated fusion mechanism. Extensive experiments conducted on real-world datasets have demonstrated the effectiveness of our model.
Privacy-Utility Balanced Voice De-Identification Using Adversarial Examples
Nov 10, 2022



Faced with the threat of identity leakage during voice data publishing, users are engaged in a privacy-utility dilemma when enjoying convenient voice services. Existing studies employ direct modification or text-based re-synthesis to de-identify users' voices, but resulting in inconsistent audibility in the presence of human participants. In this paper, we propose a voice de-identification system, which uses adversarial examples to balance the privacy and utility of voice services. Instead of typical additive examples inducing perceivable distortions, we design a novel convolutional adversarial example that modulates perturbations into real-world room impulse responses. Benefit from this, our system could preserve user identity from exposure by Automatic Speaker Identification (ASI) while remaining the voice perceptual quality for non-intrusive de-identification. Moreover, our system learns a compact speaker distribution through a conditional variational auto-encoder to sample diverse target embeddings on demand. Combining diverse target generation and input-specific perturbation construction, our system enables any-to-any identify transformation for adaptive de-identification. Experimental results show that our system could achieve 98% and 79% successful de-identification on mainstream ASIs and commercial systems with an objective Mel cepstral distortion of 4.31dB and a subjective mean opinion score of 4.48.
Incorporating Heterogeneous User Behaviors and Social Influences for Predictive Analysis
Jul 24, 2022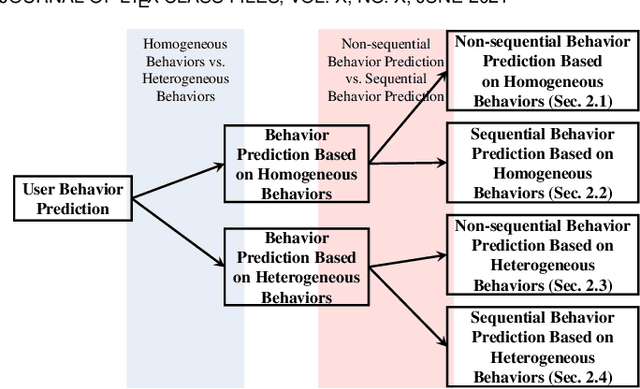

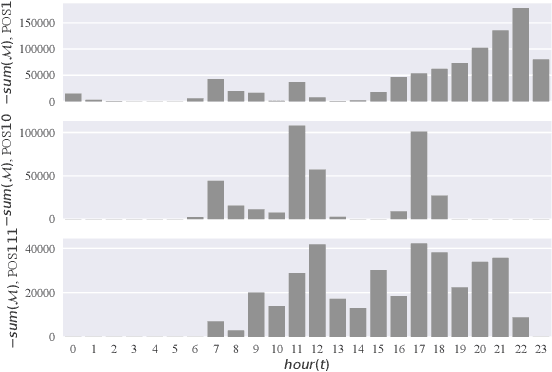
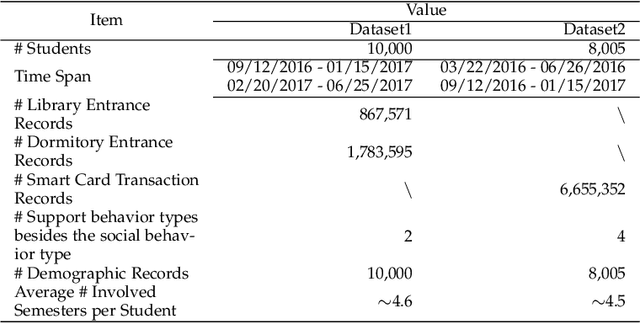
Behavior prediction based on historical behavioral data have practical real-world significance. It has been applied in recommendation, predicting academic performance, etc. With the refinement of user data description, the development of new functions, and the fusion of multiple data sources, heterogeneous behavioral data which contain multiple types of behaviors become more and more common. In this paper, we aim to incorporate heterogeneous user behaviors and social influences for behavior predictions. To this end, this paper proposes a variant of Long-Short Term Memory (LSTM) which can consider context information while modeling a behavior sequence, a projection mechanism which can model multi-faceted relationships among different types of behaviors, and a multi-faceted attention mechanism which can dynamically find out informative periods from different facets. Many kinds of behavioral data belong to spatio-temporal data. An unsupervised way to construct a social behavior graph based on spatio-temporal data and to model social influences is proposed. Moreover, a residual learning-based decoder is designed to automatically construct multiple high-order cross features based on social behavior representation and other types of behavior representations. Qualitative and quantitative experiments on real-world datasets have demonstrated the effectiveness of this model.
Deep Meta-learning in Recommendation Systems: A Survey
Jun 09, 2022
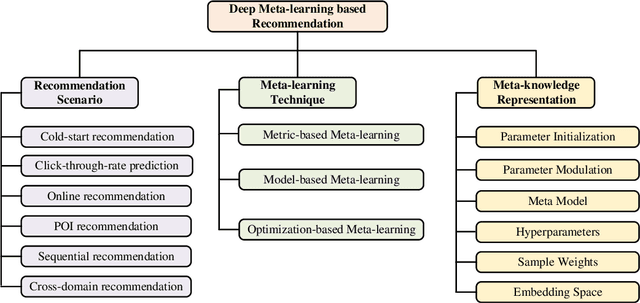
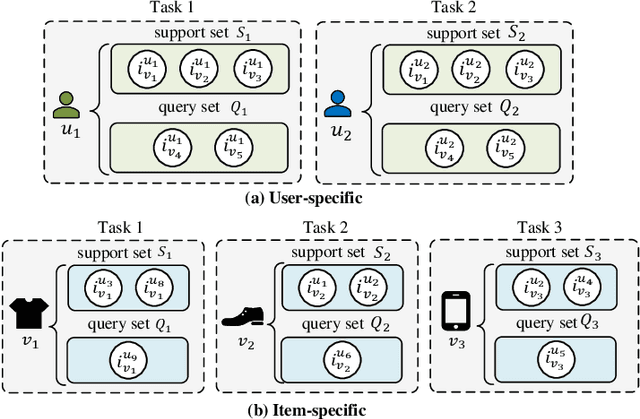
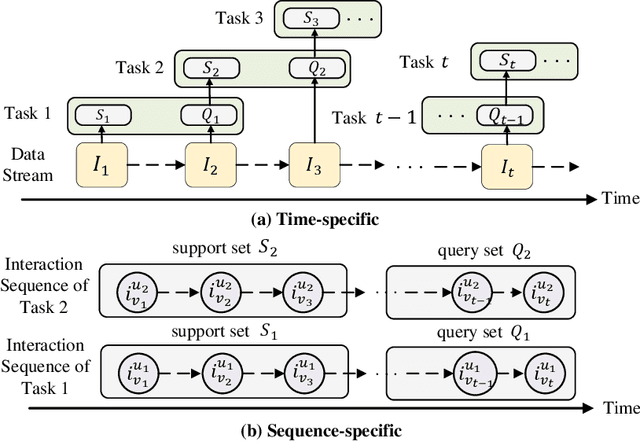
Deep neural network based recommendation systems have achieved great success as information filtering techniques in recent years. However, since model training from scratch requires sufficient data, deep learning-based recommendation methods still face the bottlenecks of insufficient data and computational inefficiency. Meta-learning, as an emerging paradigm that learns to improve the learning efficiency and generalization ability of algorithms, has shown its strength in tackling the data sparsity issue. Recently, a growing number of studies on deep meta-learning based recommenddation systems have emerged for improving the performance under recommendation scenarios where available data is limited, e.g. user cold-start and item cold-start. Therefore, this survey provides a timely and comprehensive overview of current deep meta-learning based recommendation methods. Specifically, we propose a taxonomy to discuss existing methods according to recommendation scenarios, meta-learning techniques, and meta-knowledge representations, which could provide the design space for meta-learning based recommendation methods. For each recommendation scenario, we further discuss technical details about how existing methods apply meta-learning to improve the generalization ability of recommendation models. Finally, we also point out several limitations in current research and highlight some promising directions for future research in this area.
A Survey on Cross-domain Recommendation: Taxonomies, Methods, and Future Directions
Aug 07, 2021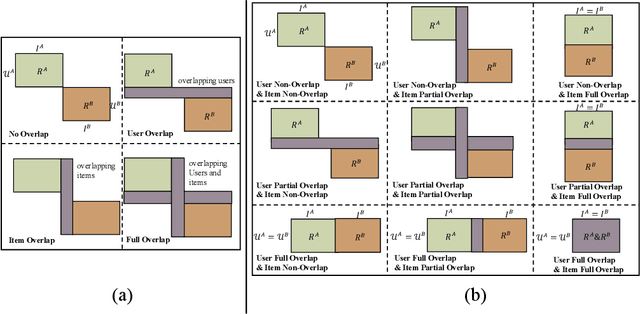
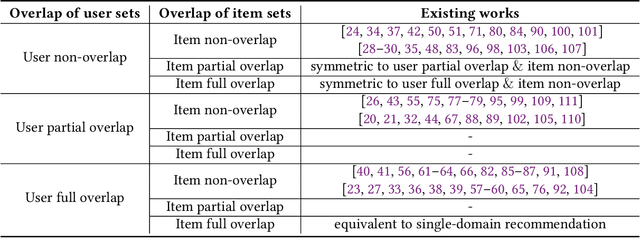

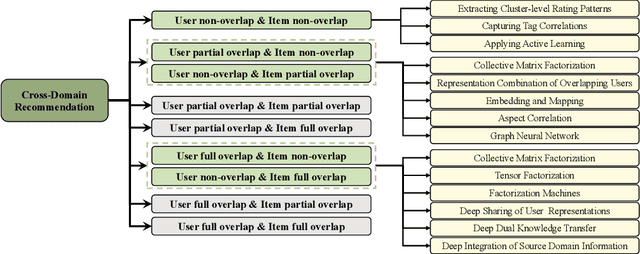
Traditional recommendation systems are faced with two long-standing obstacles, namely, data sparsity and cold-start problems, which promote the emergence and development of Cross-Domain Recommendation (CDR). The core idea of CDR is to leverage information collected from other domains to alleviate the two problems in one domain. Over the last decade, many efforts have been engaged for cross-domain recommendation. Recently, with the development of deep learning and neural networks, a large number of methods have emerged. However, there is a limited number of systematic surveys on CDR, especially regarding the latest proposed methods as well as the recommendation scenarios and recommendation tasks they address. In this survey paper, we first proposed a two-level taxonomy of cross-domain recommendation which classifies different recommendation scenarios and recommendation tasks. We then introduce and summarize existing cross-domain recommendation approaches under different recommendation scenarios in a structured manner. We also organize datasets commonly used. We conclude this survey by providing several potential research directions about this field.
Jointly Modeling Heterogeneous Student Behaviors and Interactions Among Multiple Prediction Tasks
Mar 25, 2021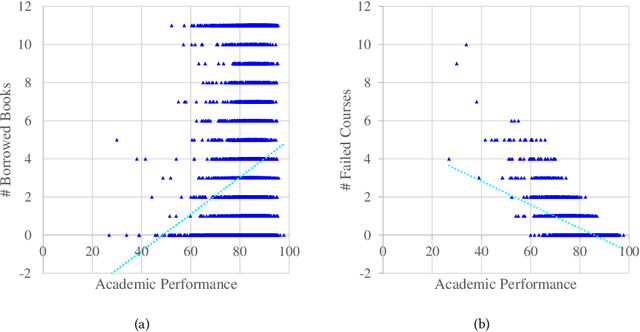

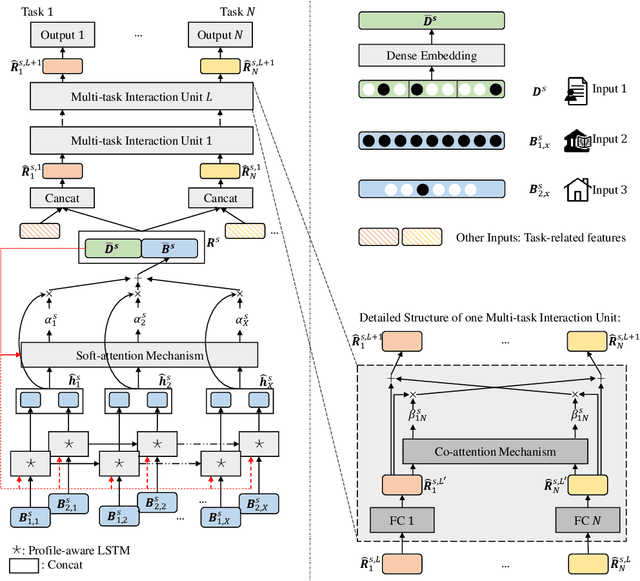
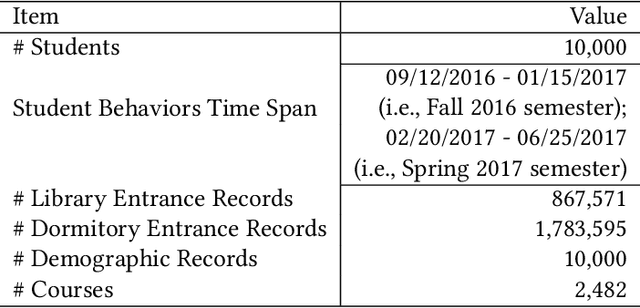
Prediction tasks about students have practical significance for both student and college. Making multiple predictions about students is an important part of a smart campus. For instance, predicting whether a student will fail to graduate can alert the student affairs office to take predictive measures to help the student improve his/her academic performance. With the development of information technology in colleges, we can collect digital footprints which encode heterogeneous behaviors continuously. In this paper, we focus on modeling heterogeneous behaviors and making multiple predictions together, since some prediction tasks are related and learning the model for a specific task may have the data sparsity problem. To this end, we propose a variant of LSTM and a soft-attention mechanism. The proposed LSTM is able to learn the student profile-aware representation from heterogeneous behavior sequences. The proposed soft-attention mechanism can dynamically learn different importance degrees of different days for every student. In this way, heterogeneous behaviors can be well modeled. In order to model interactions among multiple prediction tasks, we propose a co-attention mechanism based unit. With the help of the stacked units, we can explicitly control the knowledge transfer among multiple tasks. We design three motivating behavior prediction tasks based on a real-world dataset collected from a college. Qualitative and quantitative experiments on the three prediction tasks have demonstrated the effectiveness of our model.