 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Pore-scale Multiphase Flow from 4D Velocimetry
Mar 12, 2026Multiphase flow in porous media underpins subsurface energy and environmental technologies, including geological CO$_2$ storage and underground hydrogen storage, yet pore-scale dynamics in realistic three-dimensional materials remain difficult to characterize and predict. Here we introduce a multimodal learning framework that infers multiphase pore-scale flow directly from time-resolved four-dimensional (4D) micro-velocimetry measurements. The model couples a graph network simulator for Lagrangian tracer-particle motion with a 3D U-Net for voxelized interface evolution. The imaged pore geometry serves as a boundary constraint to the flow velocity and the multiphase interface predictions, which are coupled and updated iteratively at each time step. Trained autoregressively on experimental sequences in capillary-dominated conditions ($Ca\approx10^{-6}$), the learned surrogate captures transient, nonlocal flow perturbations and abrupt interface rearrangements (Haines jumps) over rollouts spanning seconds of physical time, while reducing hour-to-day--scale direct numerical simulations to seconds of inference. By providing rapid, experimentally informed predictions, the framework opens a route to ''digital experiments'' to replicate pore-scale physics observed in multiphase flow experiments, offering an efficient tool for exploring injection conditions and pore-geometry effects relevant to subsurface carbon and hydrogen storage.
Adaptive Dual-Weighted Gravitational Point Cloud Denoising Method
Dec 11, 2025High-quality point cloud data is a critical foundation for tasks such as autonomous driving and 3D reconstruction. However, LiDAR-based point cloud acquisition is often affected by various disturbances, resulting in a large number of noise points that degrade the accuracy of subsequent point cloud object detection and recognition. Moreover, existing point cloud denoising methods typically sacrifice computational efficiency in pursuit of higher denoising accuracy, or, conversely, improve processing speed at the expense of preserving object boundaries and fine structural details, making it difficult to simultaneously achieve high denoising accuracy, strong edge preservation, and real-time performance. To address these limitations, this paper proposes an adaptive dual-weight gravitational-based point cloud denoising method. First, an octree is employed to perform spatial partitioning of the global point cloud, enabling parallel acceleration. Then, within each leaf node, adaptive voxel-based occupancy statistics and k-nearest neighbor (kNN) density estimation are applied to rapidly remove clearly isolated and low-density noise points, thereby reducing the effective candidate set. Finally, a gravitational scoring function that combines density weights with adaptive distance weights is constructed to finely distinguish noise points from object points. Experiments conducted on the Stanford 3D Scanning Repository, the Canadian Adverse Driving Conditions (CADC) dataset, and in-house FMCW LiDAR point clouds acquired in our laboratory demonstrate that, compared with existing methods, the proposed approach achieves consistent improvements in F1, PSNR, and Chamfer Distance (CD) across various noise conditions while reducing the single-frame processing time, thereby validating its high accuracy, robustness, and real-time performance in multi-noise scenarios.
Hybrid-Emba3D: Geometry-Aware and Cross-Path Feature Hybrid Enhanced State Space Model for Point Cloud Classification
May 16, 2025The point cloud classification tasks face the dual challenge of efficiently extracting local geometric features while maintaining model complexity. The Mamba architecture utilizes the linear complexity advantage of state space models (SSMs) to overcome the computational bottleneck of Transformers while balancing global modeling capabilities. However, the inherent contradiction between its unidirectional dependency and the unordered nature of point clouds impedes modeling spatial correlation in local neighborhoods, thus constraining geometric feature extraction. This paper proposes Hybrid-Emba3D, a bidirectional Mamba model enhanced by geometry-feature coupling and cross-path feature hybridization. The Local geometric pooling with geometry-feature coupling mechanism significantly enhances local feature discriminative power via coordinated propagation and dynamic aggregation of geometric information between local center points and their neighborhoods, without introducing additional parameters. The designed Collaborative feature enhancer adopts dual-path hybridization, effectively handling local mutations and sparse key signals, breaking through the limitations of traditional SSM long-range modeling. Experimental results demonstrate that the proposed model achieves a new SOTA classification accuracy of 95.99% on ModelNet40 with only 0.03M additional.
Towards Universal Mesh Movement Networks
Jul 02, 2024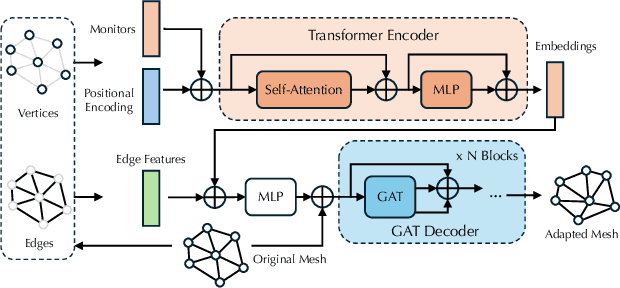



Solving complex Partial Differential Equations (PDEs) accurately and efficiently is an essential and challenging problem in all scientific and engineering disciplines. Mesh movement methods provide the capability to improve the accuracy of the numerical solution without increasing the overall mesh degree of freedom count. Conventional sophisticated mesh movement methods are extremely expensive and struggle to handle scenarios with complex boundary geometries. However, existing learning-based methods require re-training from scratch given a different PDE type or boundary geometry, which limits their applicability, and also often suffer from robustness issues in the form of inverted elements. In this paper, we introduce the Universal Mesh Movement Network (UM2N), which -- once trained -- can be applied in a non-intrusive, zero-shot manner to move meshes with different size distributions and structures, for solvers applicable to different PDE types and boundary geometries. UM2N consists of a Graph Transformer (GT) encoder for extracting features and a Graph Attention Network (GAT) based decoder for moving the mesh. We evaluate our method on advection and Navier-Stokes based examples, as well as a real-world tsunami simulation case. Our method outperforms existing learning-based mesh movement methods in terms of the benchmarks described above. In comparison to the conventional sophisticated Monge-Amp\`ere PDE-solver based method, our approach not only significantly accelerates mesh movement, but also proves effective in scenarios where the conventional method fails. Our project page is at https://erizmr.github.io/UM2N/.
Spatio-Temporal Bi-directional Cross-frame Memory for Distractor Filtering Point Cloud Single Object Tracking
Mar 23, 20243D single object tracking within LIDAR point clouds is a pivotal task in computer vision, with profound implications for autonomous driving and robotics. However, existing methods, which depend solely on appearance matching via Siamese networks or utilize motion information from successive frames, encounter significant challenges. Issues such as similar objects nearby or occlusions can result in tracker drift. To mitigate these challenges, we design an innovative spatio-temporal bi-directional cross-frame distractor filtering tracker, named STMD-Tracker. Our first step involves the creation of a 4D multi-frame spatio-temporal graph convolution backbone. This design separates KNN graph spatial embedding and incorporates 1D temporal convolution, effectively capturing temporal fluctuations and spatio-temporal information. Subsequently, we devise a novel bi-directional cross-frame memory procedure. This integrates future and synthetic past frame memory to enhance the current memory, thereby improving the accuracy of iteration-based tracking. This iterative memory update mechanism allows our tracker to dynamically compensate for information in the current frame, effectively reducing tracker drift. Lastly, we construct spatially reliable Gaussian masks on the fused features to eliminate distractor points. This is further supplemented by an object-aware sampling strategy, which bolsters the efficiency and precision of object localization, thereby reducing tracking errors caused by distractors. Our extensive experiments on KITTI, NuScenes and Waymo datasets demonstrate that our approach significantly surpasses the current state-of-the-art methods.
PiPAD: Pipelined and Parallel Dynamic GNN Training on GPUs
Jan 05, 2023Dynamic Graph Neural Networks (DGNNs) have been broadly applied in various real-life applications, such as link prediction and pandemic forecast, to capture both static structural information and temporal characteristics from dynamic graphs. Combining both time-dependent and -independent components, DGNNs manifest substantial parallel computation and data reuse potentials, but suffer from severe memory access inefficiency and data transfer overhead under the canonical one-graph-at-a-time training pattern. To tackle the challenges, we propose PiPAD, a $\underline{\textbf{Pi}}pelined$ and $\underline{\textbf{PA}}rallel$ $\underline{\textbf{D}}GNN$ training framework for the end-to-end performance optimization on GPUs. From both the algorithm and runtime level, PiPAD holistically reconstructs the overall training paradigm from the data organization to computation manner. Capable of processing multiple graph snapshots in parallel, PiPAD eliminates the unnecessary data transmission and alleviates memory access inefficiency to improve the overall performance. Our evaluation across various datasets shows PiPAD achieves $1.22\times$-$9.57\times$ speedup over the state-of-the-art DGNN frameworks on three representative models.
Incorporating Heterogeneous User Behaviors and Social Influences for Predictive Analysis
Jul 24, 2022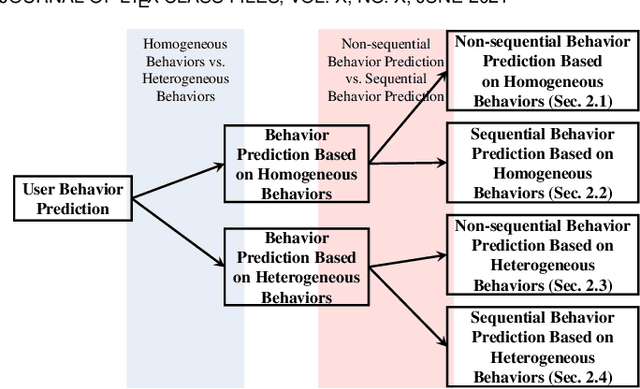

Behavior prediction based on historical behavioral data have practical real-world significance. It has been applied in recommendation, predicting academic performance, etc. With the refinement of user data description, the development of new functions, and the fusion of multiple data sources, heterogeneous behavioral data which contain multiple types of behaviors become more and more common. In this paper, we aim to incorporate heterogeneous user behaviors and social influences for behavior predictions. To this end, this paper proposes a variant of Long-Short Term Memory (LSTM) which can consider context information while modeling a behavior sequence, a projection mechanism which can model multi-faceted relationships among different types of behaviors, and a multi-faceted attention mechanism which can dynamically find out informative periods from different facets. Many kinds of behavioral data belong to spatio-temporal data. An unsupervised way to construct a social behavior graph based on spatio-temporal data and to model social influences is proposed. Moreover, a residual learning-based decoder is designed to automatically construct multiple high-order cross features based on social behavior representation and other types of behavior representations. Qualitative and quantitative experiments on real-world datasets have demonstrated the effectiveness of this model.
Deep Meta-learning in Recommendation Systems: A Survey
Jun 09, 2022
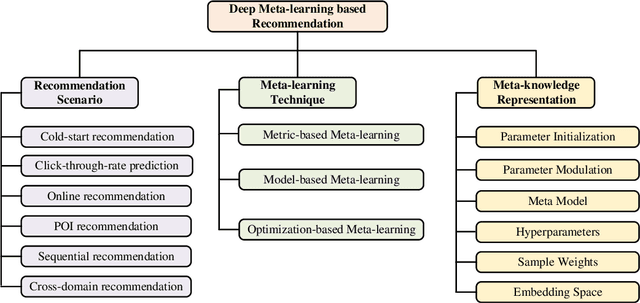
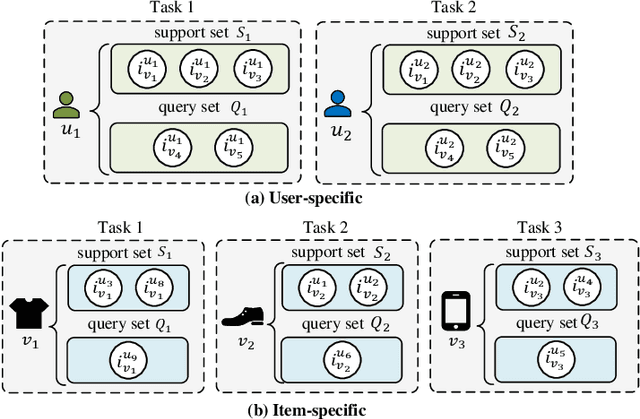
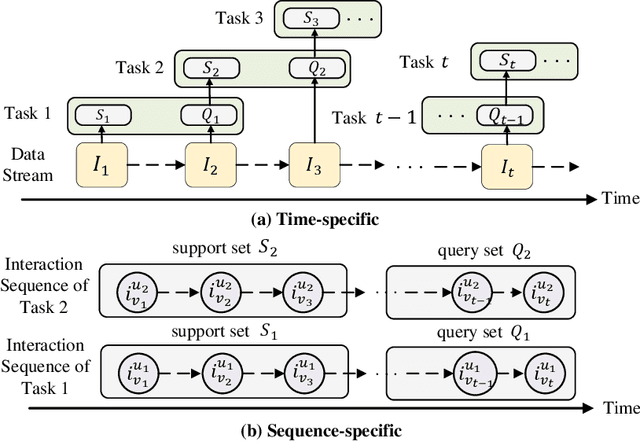
Deep neural network based recommendation systems have achieved great success as information filtering techniques in recent years. However, since model training from scratch requires sufficient data, deep learning-based recommendation methods still face the bottlenecks of insufficient data and computational inefficiency. Meta-learning, as an emerging paradigm that learns to improve the learning efficiency and generalization ability of algorithms, has shown its strength in tackling the data sparsity issue. Recently, a growing number of studies on deep meta-learning based recommenddation systems have emerged for improving the performance under recommendation scenarios where available data is limited, e.g. user cold-start and item cold-start. Therefore, this survey provides a timely and comprehensive overview of current deep meta-learning based recommendation methods. Specifically, we propose a taxonomy to discuss existing methods according to recommendation scenarios, meta-learning techniques, and meta-knowledge representations, which could provide the design space for meta-learning based recommendation methods. For each recommendation scenario, we further discuss technical details about how existing methods apply meta-learning to improve the generalization ability of recommendation models. Finally, we also point out several limitations in current research and highlight some promising directions for future research in this area.
TEMImageNet and AtomSegNet Deep Learning Training Library and Models for High-Precision Atom Segmentation, Localization, Denoising, and Super-resolution Processing of Atom-Resolution Scanning TEM Images
Dec 16, 2020


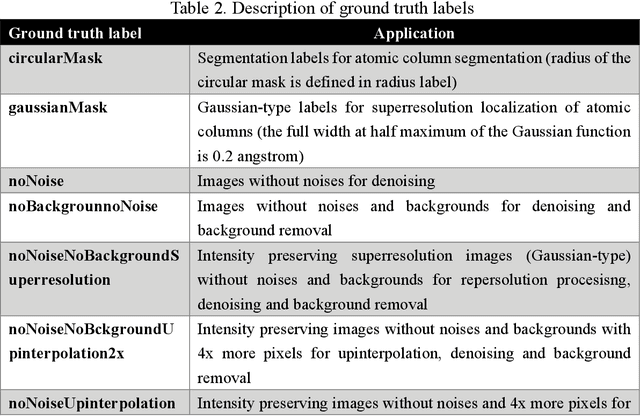
Atom segmentation and localization, noise reduction and super-resolution processing of atomic-resolution scanning transmission electron microscopy (STEM) images with high precision and robustness is a challenging task. Although several conventional algorithms, such has thresholding, edge detection and clustering, can achieve reasonable performance in some predefined sceneries, they tend to fail when interferences from the background are strong and unpredictable. Particularly, for atomic-resolution STEM images, so far there is no well-established algorithm that is robust enough to segment or detect all atomic columns when there is large thickness variation in a recorded image. Herein, we report the development of a training library and a deep learning method that can perform robust and precise atom segmentation, localization, denoising, and super-resolution processing of experimental images. Despite using simulated images as training datasets, the deep-learning model can self-adapt to experimental STEM images and shows outstanding performance in atom detection and localization in challenging contrast conditions and the precision is consistently better than the state-of-the-art two-dimensional Gaussian fit method. Taking a step further, we have deployed our deep-learning models to a desktop app with a graphical user interface and the app is free and open-source. We have also built a TEM ImageNet project website for easy browsing and downloading of the training data.