 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Non-Expert Customized Congestion Control
Jan 30, 2026General-purpose congestion control algorithms (CCAs) are designed to achieve general congestion control goals, but they may not meet the specific requirements of certain users. Customized CCAs can meet certain users' specific requirements; however, non-expert users often lack the expertise to implement them. In this paper, we present an exploratory non-expert customized CCA framework, named NECC, which enables non-expert users to easily model, implement, and deploy their customized CCAs by leveraging Large Language Models and the Berkeley Packet Filter (BPF) interface. To the best of our knowledge, we are the first to address the customized CCA implementation problem. Our evaluations using real-world CCAs show that the performance of NECC is very promising, and we discuss the insights that we find and possible future research directions.
* Accepted manuscript (AAM) of IEEE ICC 2025 paper. DOI: 10.1109/ICC52391.2025.11160790
Fairness-aware organ exchange and kidney paired donation
Mar 09, 2025The kidney paired donation (KPD) program provides an innovative solution to overcome incompatibility challenges in kidney transplants by matching incompatible donor-patient pairs and facilitating kidney exchanges. To address unequal access to transplant opportunities, there are two widely used fairness criteria: group fairness and individual fairness. However, these criteria do not consider protected patient features, which refer to characteristics legally or ethically recognized as needing protection from discrimination, such as race and gender. Motivated by the calibration principle in machine learning, we introduce a new fairness criterion: the matching outcome should be conditionally independent of the protected feature, given the sensitization level. We integrate this fairness criterion as a constraint within the KPD optimization framework and propose a computationally efficient solution. Theoretically, we analyze the associated price of fairness using random graph models. Empirically, we compare our fairness criterion with group fairness and individual fairness through both simulations and a real-data example.
Machine learning for modelling unstructured grid data in computational physics: a review
Feb 13, 2025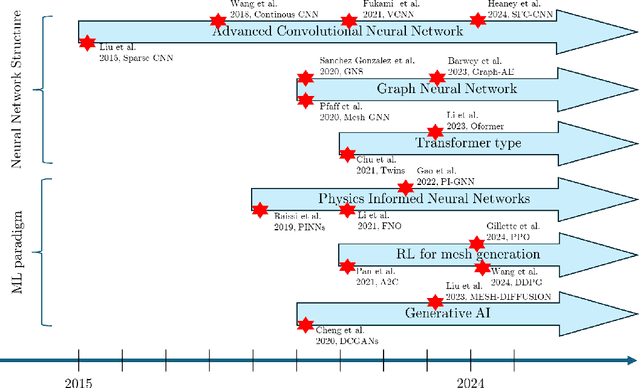
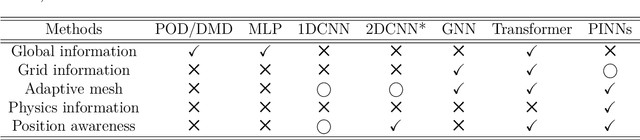
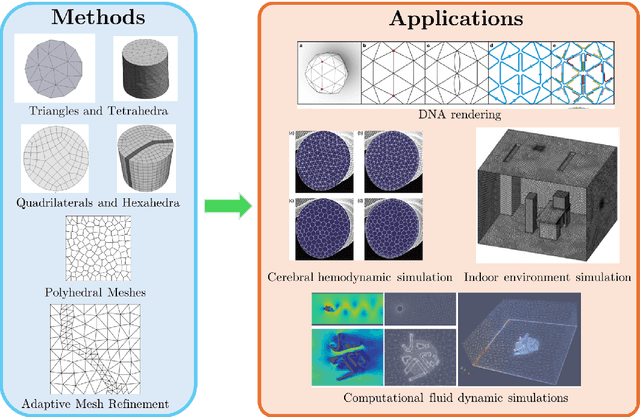

Unstructured grid data are essential for modelling complex geometries and dynamics in computational physics. Yet, their inherent irregularity presents significant challenges for conventional machine learning (ML) techniques. This paper provides a comprehensive review of advanced ML methodologies designed to handle unstructured grid data in high-dimensional dynamical systems. Key approaches discussed include graph neural networks, transformer models with spatial attention mechanisms, interpolation-integrated ML methods, and meshless techniques such as physics-informed neural networks. These methodologies have proven effective across diverse fields, including fluid dynamics and environmental simulations. This review is intended as a guidebook for computational scientists seeking to apply ML approaches to unstructured grid data in their domains, as well as for ML researchers looking to address challenges in computational physics. It places special focus on how ML methods can overcome the inherent limitations of traditional numerical techniques and, conversely, how insights from computational physics can inform ML development. To support benchmarking, this review also provides a summary of open-access datasets of unstructured grid data in computational physics. Finally, emerging directions such as generative models with unstructured data, reinforcement learning for mesh generation, and hybrid physics-data-driven paradigms are discussed to inspire future advancements in this evolving field.
BAG: Body-Aligned 3D Wearable Asset Generation
Jan 27, 2025



While recent advancements have shown remarkable progress in general 3D shape generation models, the challenge of leveraging these approaches to automatically generate wearable 3D assets remains unexplored. To this end, we present BAG, a Body-aligned Asset Generation method to output 3D wearable asset that can be automatically dressed on given 3D human bodies. This is achived by controlling the 3D generation process using human body shape and pose information. Specifically, we first build a general single-image to consistent multiview image diffusion model, and train it on the large Objaverse dataset to achieve diversity and generalizability. Then we train a Controlnet to guide the multiview generator to produce body-aligned multiview images. The control signal utilizes the multiview 2D projections of the target human body, where pixel values represent the XYZ coordinates of the body surface in a canonical space. The body-conditioned multiview diffusion generates body-aligned multiview images, which are then fed into a native 3D diffusion model to produce the 3D shape of the asset. Finally, by recovering the similarity transformation using multiview silhouette supervision and addressing asset-body penetration with physics simulators, the 3D asset can be accurately fitted onto the target human body. Experimental results demonstrate significant advantages over existing methods in terms of image prompt-following capability, shape diversity, and shape quality. Our project page is available at https://bag-3d.github.io/.
PhyCAGE: Physically Plausible Compositional 3D Asset Generation from a Single Image
Nov 27, 2024



We present PhyCAGE, the first approach for physically plausible compositional 3D asset generation from a single image. Given an input image, we first generate consistent multi-view images for components of the assets. These images are then fitted with 3D Gaussian Splatting representations. To ensure that the Gaussians representing objects are physically compatible with each other, we introduce a Physical Simulation-Enhanced Score Distillation Sampling (PSE-SDS) technique to further optimize the positions of the Gaussians. It is achieved by setting the gradient of the SDS loss as the initial velocity of the physical simulation, allowing the simulator to act as a physics-guided optimizer that progressively corrects the Gaussians' positions to a physically compatible state. Experimental results demonstrate that the proposed method can generate physically plausible compositional 3D assets given a single image.
Towards Universal Mesh Movement Networks
Jul 02, 2024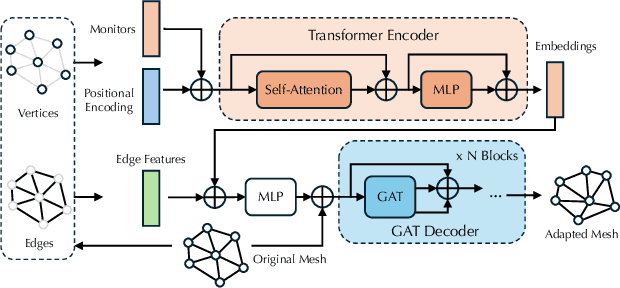



Solving complex Partial Differential Equations (PDEs) accurately and efficiently is an essential and challenging problem in all scientific and engineering disciplines. Mesh movement methods provide the capability to improve the accuracy of the numerical solution without increasing the overall mesh degree of freedom count. Conventional sophisticated mesh movement methods are extremely expensive and struggle to handle scenarios with complex boundary geometries. However, existing learning-based methods require re-training from scratch given a different PDE type or boundary geometry, which limits their applicability, and also often suffer from robustness issues in the form of inverted elements. In this paper, we introduce the Universal Mesh Movement Network (UM2N), which -- once trained -- can be applied in a non-intrusive, zero-shot manner to move meshes with different size distributions and structures, for solvers applicable to different PDE types and boundary geometries. UM2N consists of a Graph Transformer (GT) encoder for extracting features and a Graph Attention Network (GAT) based decoder for moving the mesh. We evaluate our method on advection and Navier-Stokes based examples, as well as a real-world tsunami simulation case. Our method outperforms existing learning-based mesh movement methods in terms of the benchmarks described above. In comparison to the conventional sophisticated Monge-Amp\`ere PDE-solver based method, our approach not only significantly accelerates mesh movement, but also proves effective in scenarios where the conventional method fails. Our project page is at https://erizmr.github.io/UM2N/.
End-to-end Wind Turbine Wake Modelling with Deep Graph Representation Learning
Dec 17, 2022

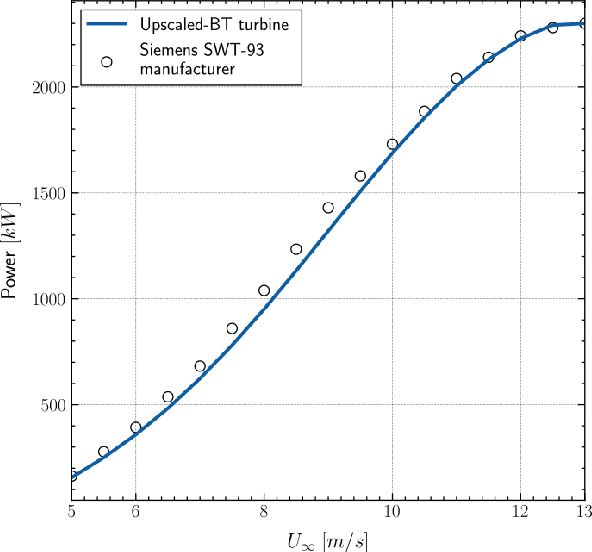

Wind turbine wake modelling is of crucial importance to accurate resource assessment, to layout optimisation, and to the operational control of wind farms. This work proposes a surrogate model for the representation of wind turbine wakes based on a state-of-the-art graph representation learning method termed a graph neural network. The proposed end-to-end deep learning model operates directly on unstructured meshes and has been validated against high-fidelity data, demonstrating its ability to rapidly make accurate 3D flow field predictions for various inlet conditions and turbine yaw angles. The specific graph neural network model employed here is shown to generalise well to unseen data and is less sensitive to over-smoothing compared to common graph neural networks. A case study based upon a real world wind farm further demonstrates the capability of the proposed approach to predict farm scale power generation. Moreover, the proposed graph neural network framework is flexible and highly generic and as formulated here can be applied to any steady state computational fluid dynamics simulations on unstructured meshes.
E2N: Error Estimation Networks for Goal-Oriented Mesh Adaptation
Jul 22, 2022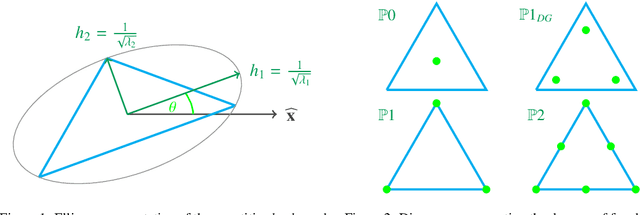


Given a partial differential equation (PDE), goal-oriented error estimation allows us to understand how errors in a diagnostic quantity of interest (QoI), or goal, occur and accumulate in a numerical approximation, for example using the finite element method. By decomposing the error estimates into contributions from individual elements, it is possible to formulate adaptation methods, which modify the mesh with the objective of minimising the resulting QoI error. However, the standard error estimate formulation involves the true adjoint solution, which is unknown in practice. As such, it is common practice to approximate it with an 'enriched' approximation (e.g. in a higher order space or on a refined mesh). Doing so generally results in a significant increase in computational cost, which can be a bottleneck compromising the competitiveness of (goal-oriented) adaptive simulations. The central idea of this paper is to develop a "data-driven" goal-oriented mesh adaptation approach through the selective replacement of the expensive error estimation step with an appropriately configured and trained neural network. In doing so, the error estimator may be obtained without even constructing the enriched spaces. An element-by-element construction is employed here, whereby local values of various parameters related to the mesh geometry and underlying problem physics are taken as inputs, and the corresponding contribution to the error estimator is taken as output. We demonstrate that this approach is able to obtain the same accuracy with a reduced computational cost, for adaptive mesh test cases related to flow around tidal turbines, which interact via their downstream wakes, and where the overall power output of the farm is taken as the QoI. Moreover, we demonstrate that the element-by-element approach implies reasonably low training costs.
Learning to Estimate and Refine Fluid Motion with Physical Dynamics
Jun 22, 2022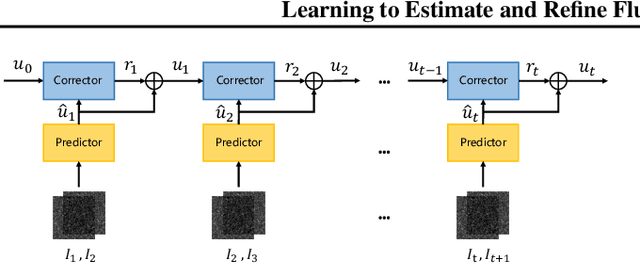
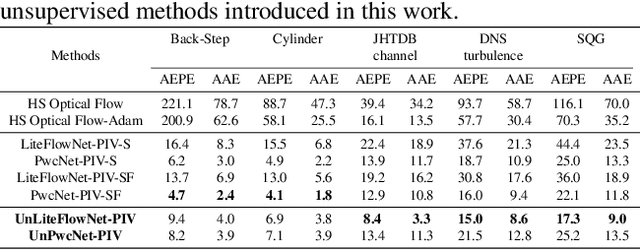
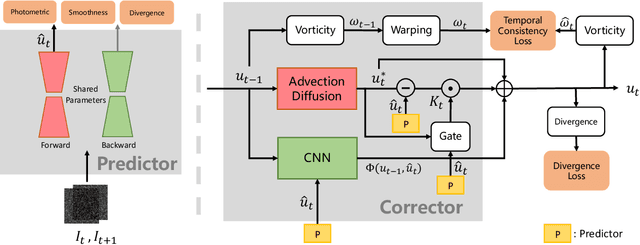
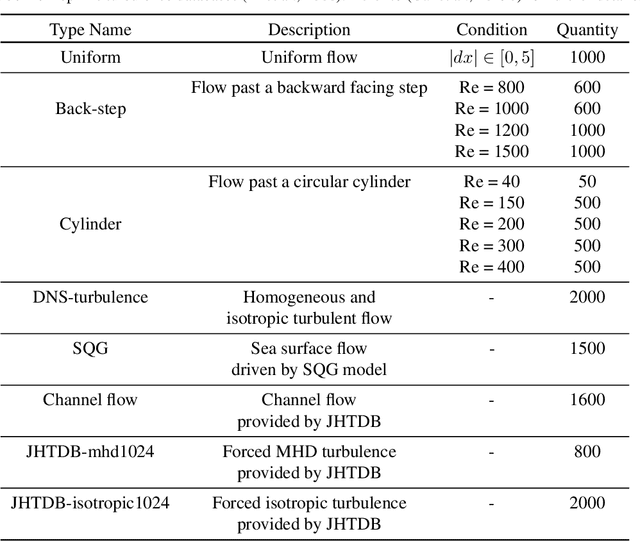
Extracting information on fluid motion directly from images is challenging. Fluid flow represents a complex dynamic system governed by the Navier-Stokes equations. General optical flow methods are typically designed for rigid body motion, and thus struggle if applied to fluid motion estimation directly. Further, optical flow methods only focus on two consecutive frames without utilising historical temporal information, while the fluid motion (velocity field) can be considered a continuous trajectory constrained by time-dependent partial differential equations (PDEs). This discrepancy has the potential to induce physically inconsistent estimations. Here we propose an unsupervised learning based prediction-correction scheme for fluid flow estimation. An estimate is first given by a PDE-constrained optical flow predictor, which is then refined by a physical based corrector. The proposed approach outperforms optical flow methods and shows competitive results compared to existing supervised learning based methods on a benchmark dataset. Furthermore, the proposed approach can generalize to complex real-world fluid scenarios where ground truth information is effectively unknowable. Finally, experiments demonstrate that the physical corrector can refine flow estimates by mimicking the operator splitting method commonly utilised in fluid dynamical simulation.
Complex Locomotion Skill Learning via Differentiable Physics
Jun 06, 2022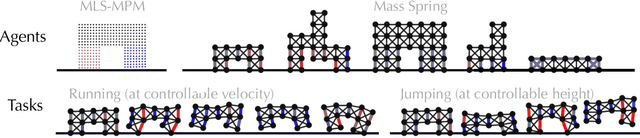



Differentiable physics enables efficient gradient-based optimizations of neural network (NN) controllers. However, existing work typically only delivers NN controllers with limited capability and generalizability. We present a practical learning framework that outputs unified NN controllers capable of tasks with significantly improved complexity and diversity. To systematically improve training robustness and efficiency, we investigated a suite of improvements over the baseline approach, including periodic activation functions, and tailored loss functions. In addition, we find our adoption of batching and an Adam optimizer effective in training complex locomotion tasks. We evaluate our framework on differentiable mass-spring and material point method (MPM) simulations, with challenging locomotion tasks and multiple robot designs. Experiments show that our learning framework, based on differentiable physics, delivers better results than reinforcement learning and converges much faster. We demonstrate that users can interactively control soft robot locomotion and switch among multiple goals with specified velocity, height, and direction instructions using a unified NN controller trained in our system.