 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI3DM: Implicit 3D-aware Memory Retrieval and Injection for Consistent Video Scene Generation
Mar 24, 2026Despite remarkable progress in video generation, maintaining long-term scene consistency upon revisiting previously explored areas remains challenging. Existing solutions rely either on explicitly constructing 3D geometry, which suffers from error accumulation and scale ambiguity, or on naive camera Field-of-View (FoV) retrieval, which typically fails under complex occlusions. To overcome these limitations, we propose I3DM, a novel implicit 3D-aware memory mechanism for consistent video scene generation that bypasses explicit 3D reconstruction. At the core of our approach is a 3D-aware memory retrieval strategy, which leverages the intermediate features of a pre-trained Feed-Forward Novel View Synthesis (FF-NVS) model to score view relevance, enabling robust retrieval even in highly occluded scenarios. Furthermore, to fully utilize the retrieved historical frames, we introduce a 3D-aligned memory injection module. This module implicitly warps historical content to the target view and adaptively conditions the generation on reliable warping regions, leading to improved revisit consistency and accurate camera control. Extensive experiments demonstrate that our method outperforms state-of-the-art approaches, achieving superior revisit consistency, generation fidelity, and camera control precision.
MWM: Mobile World Models for Action-Conditioned Consistent Prediction
Mar 08, 2026World models enable planning in imagined future predicted space, offering a promising framework for embodied navigation. However, existing navigation world models often lack action-conditioned consistency, so visually plausible predictions can still drift under multi-step rollout and degrade planning. Moreover, efficient deployment requires few-step diffusion inference, but existing distillation methods do not explicitly preserve rollout consistency, creating a training-inference mismatch. To address these challenges, we propose MWM, a mobile world model for planning-based image-goal navigation. Specifically, we introduce a two-stage training framework that combines structure pretraining with Action-Conditioned Consistency (ACC) post-training to improve action-conditioned rollout consistency. We further introduce Inference-Consistent State Distillation (ICSD) for few-step diffusion distillation with improved rollout consistency. Our experiments on benchmark and real-world tasks demonstrate consistent gains in visual fidelity, trajectory accuracy, planning success, and inference efficiency. Code: https://github.com/AIGeeksGroup/MWM. Website: https://aigeeksgroup.github.io/MWM.
BachVid: Training-Free Video Generation with Consistent Background and Character
Oct 24, 2025Diffusion Transformers (DiTs) have recently driven significant progress in text-to-video (T2V) generation. However, generating multiple videos with consistent characters and backgrounds remains a significant challenge. Existing methods typically rely on reference images or extensive training, and often only address character consistency, leaving background consistency to image-to-video models. We introduce BachVid, the first training-free method that achieves consistent video generation without needing any reference images. Our approach is based on a systematic analysis of DiT's attention mechanism and intermediate features, revealing its ability to extract foreground masks and identify matching points during the denoising process. Our method leverages this finding by first generating an identity video and caching the intermediate variables, and then inject these cached variables into corresponding positions in newly generated videos, ensuring both foreground and background consistency across multiple videos. Experimental results demonstrate that BachVid achieves robust consistency in generated videos without requiring additional training, offering a novel and efficient solution for consistent video generation without relying on reference images or additional training.
BAG: Body-Aligned 3D Wearable Asset Generation
Jan 27, 2025



While recent advancements have shown remarkable progress in general 3D shape generation models, the challenge of leveraging these approaches to automatically generate wearable 3D assets remains unexplored. To this end, we present BAG, a Body-aligned Asset Generation method to output 3D wearable asset that can be automatically dressed on given 3D human bodies. This is achived by controlling the 3D generation process using human body shape and pose information. Specifically, we first build a general single-image to consistent multiview image diffusion model, and train it on the large Objaverse dataset to achieve diversity and generalizability. Then we train a Controlnet to guide the multiview generator to produce body-aligned multiview images. The control signal utilizes the multiview 2D projections of the target human body, where pixel values represent the XYZ coordinates of the body surface in a canonical space. The body-conditioned multiview diffusion generates body-aligned multiview images, which are then fed into a native 3D diffusion model to produce the 3D shape of the asset. Finally, by recovering the similarity transformation using multiview silhouette supervision and addressing asset-body penetration with physics simulators, the 3D asset can be accurately fitted onto the target human body. Experimental results demonstrate significant advantages over existing methods in terms of image prompt-following capability, shape diversity, and shape quality. Our project page is available at https://bag-3d.github.io/.
PhyCAGE: Physically Plausible Compositional 3D Asset Generation from a Single Image
Nov 27, 2024



We present PhyCAGE, the first approach for physically plausible compositional 3D asset generation from a single image. Given an input image, we first generate consistent multi-view images for components of the assets. These images are then fitted with 3D Gaussian Splatting representations. To ensure that the Gaussians representing objects are physically compatible with each other, we introduce a Physical Simulation-Enhanced Score Distillation Sampling (PSE-SDS) technique to further optimize the positions of the Gaussians. It is achieved by setting the gradient of the SDS loss as the initial velocity of the physical simulation, allowing the simulator to act as a physics-guided optimizer that progressively corrects the Gaussians' positions to a physically compatible state. Experimental results demonstrate that the proposed method can generate physically plausible compositional 3D assets given a single image.
NeuSDFusion: A Spatial-Aware Generative Model for 3D Shape Completion, Reconstruction, and Generation
Mar 27, 2024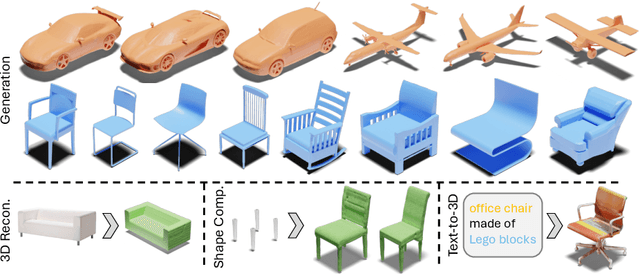
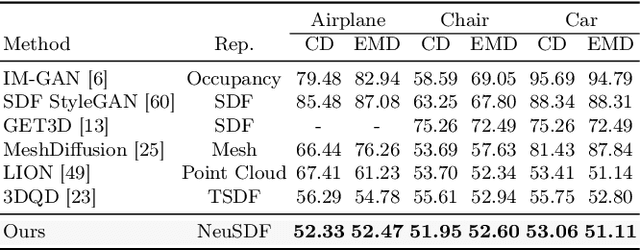

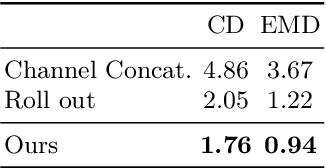
3D shape generation aims to produce innovative 3D content adhering to specific conditions and constraints. Existing methods often decompose 3D shapes into a sequence of localized components, treating each element in isolation without considering spatial consistency. As a result, these approaches exhibit limited versatility in 3D data representation and shape generation, hindering their ability to generate highly diverse 3D shapes that comply with the specified constraints. In this paper, we introduce a novel spatial-aware 3D shape generation framework that leverages 2D plane representations for enhanced 3D shape modeling. To ensure spatial coherence and reduce memory usage, we incorporate a hybrid shape representation technique that directly learns a continuous signed distance field representation of the 3D shape using orthogonal 2D planes. Additionally, we meticulously enforce spatial correspondences across distinct planes using a transformer-based autoencoder structure, promoting the preservation of spatial relationships in the generated 3D shapes. This yields an algorithm that consistently outperforms state-of-the-art 3D shape generation methods on various tasks, including unconditional shape generation, multi-modal shape completion, single-view reconstruction, and text-to-shape synthesis.
Frankenstein: Generating Semantic-Compositional 3D Scenes in One Tri-Plane
Mar 24, 2024



We present Frankenstein, a diffusion-based framework that can generate semantic-compositional 3D scenes in a single pass. Unlike existing methods that output a single, unified 3D shape, Frankenstein simultaneously generates multiple separated shapes, each corresponding to a semantically meaningful part. The 3D scene information is encoded in one single tri-plane tensor, from which multiple Singed Distance Function (SDF) fields can be decoded to represent the compositional shapes. During training, an auto-encoder compresses tri-planes into a latent space, and then the denoising diffusion process is employed to approximate the distribution of the compositional scenes. Frankenstein demonstrates promising results in generating room interiors as well as human avatars with automatically separated parts. The generated scenes facilitate many downstream applications, such as part-wise re-texturing, object rearrangement in the room or avatar cloth re-targeting.
RIS-Enabled Joint Near-Field 3D Localization and Synchronization in SISO Multipath Environments
Mar 11, 2024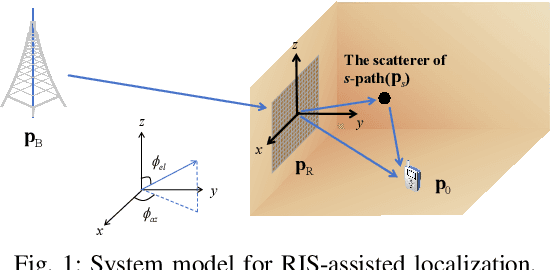
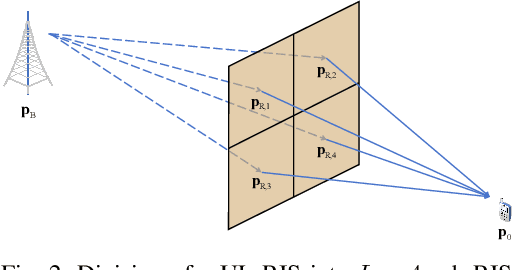
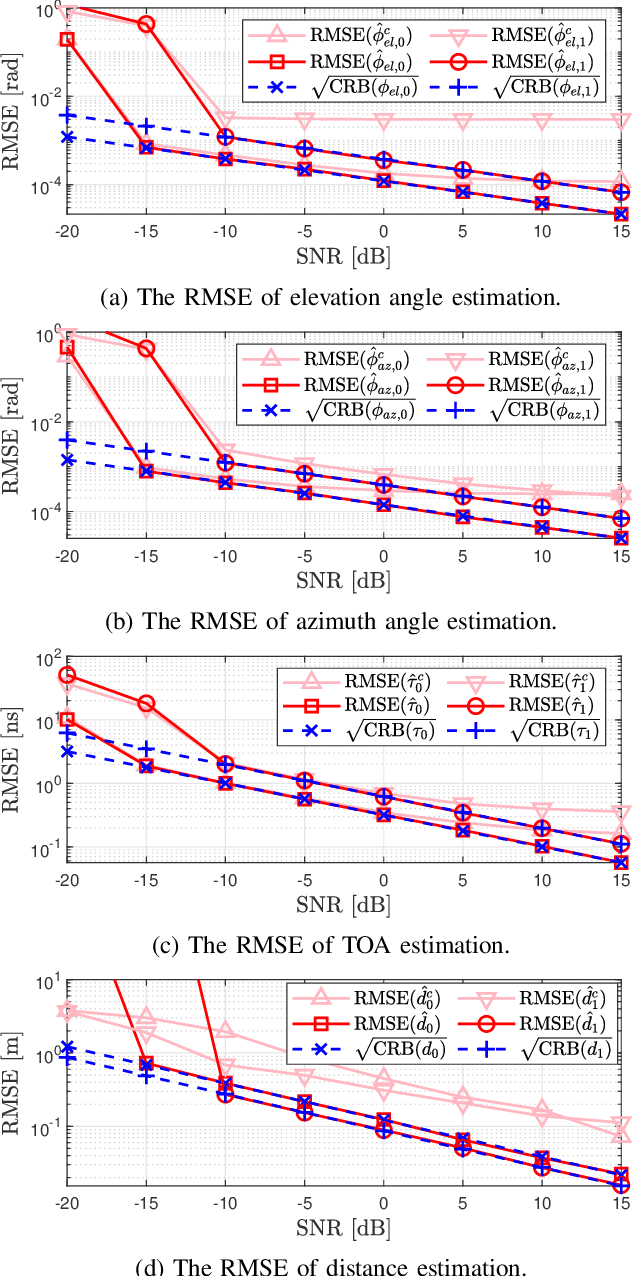
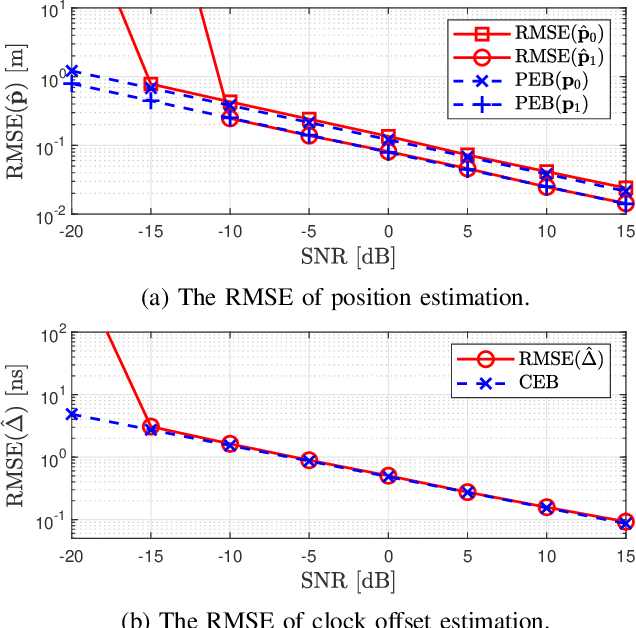
Reconfigurable Intelligent Surfaces (RIS) show great promise in the realm of 6th generation (6G) wireless systems, particularly in the areas of localization and communication. Their cost-effectiveness and energy efficiency enable the integration of numerous passive and reflective elements, enabling near-field propagation. In this paper, we tackle the challenges of RIS-aided 3D localization and synchronization in multipath environments, focusing on the near-field of mmWave systems. Specifically, our approach involves formulating a maximum likelihood (ML) estimation problem for the channel parameters. To initiate this process, we leverage a combination of canonical polyadic decomposition (CPD) and orthogonal matching pursuit (OMP) to obtain coarse estimates of the time of arrival (ToA) and angle of departure (AoD) under the far-field approximation. Subsequently, distances are estimated using $l_{1}$-regularization based on a near-field model. Additionally, we introduce a refinement phase employing the spatial alternating generalized expectation maximization (SAGE) algorithm. Finally, a weighted least squares approach is applied to convert channel parameters into position and clock offset estimates. To extend the estimation algorithm to ultra-large (UL) RIS-assisted localization scenarios, it is further enhanced to reduce errors associated with far-field approximations, especially in the presence of significant near-field effects, achieved by narrowing the RIS aperture. Moreover, the Cram\'er-Rao Bound (CRB) is derived and the RIS phase shifts are optimized to improve the positioning accuracy. Numerical results affirm the efficacy of the proposed estimation algorithm.
BlockFusion: Expandable 3D Scene Generation using Latent Tri-plane Extrapolation
Jan 31, 2024



We present BlockFusion, a diffusion-based model that generates 3D scenes as unit blocks and seamlessly incorporates new blocks to extend the scene. BlockFusion is trained using datasets of 3D blocks that are randomly cropped from complete 3D scene meshes. Through per-block fitting, all training blocks are converted into the hybrid neural fields: with a tri-plane containing the geometry features, followed by a Multi-layer Perceptron (MLP) for decoding the signed distance values. A variational auto-encoder is employed to compress the tri-planes into the latent tri-plane space, on which the denoising diffusion process is performed. Diffusion applied to the latent representations allows for high-quality and diverse 3D scene generation. To expand a scene during generation, one needs only to append empty blocks to overlap with the current scene and extrapolate existing latent tri-planes to populate new blocks. The extrapolation is done by conditioning the generation process with the feature samples from the overlapping tri-planes during the denoising iterations. Latent tri-plane extrapolation produces semantically and geometrically meaningful transitions that harmoniously blend with the existing scene. A 2D layout conditioning mechanism is used to control the placement and arrangement of scene elements. Experimental results indicate that BlockFusion is capable of generating diverse, geometrically consistent and unbounded large 3D scenes with unprecedented high-quality shapes in both indoor and outdoor scenarios.
Rethinking Cross-Attention for Infrared and Visible Image Fusion
Jan 22, 2024The salient information of an infrared image and the abundant texture of a visible image can be fused to obtain a comprehensive image. As can be known, the current fusion methods based on Transformer techniques for infrared and visible (IV) images have exhibited promising performance. However, the attention mechanism of the previous Transformer-based methods was prone to extract common information from source images without considering the discrepancy information, which limited fusion performance. In this paper, by reevaluating the cross-attention mechanism, we propose an alternate Transformer fusion network (ATFuse) to fuse IV images. Our ATFuse consists of one discrepancy information injection module (DIIM) and two alternate common information injection modules (ACIIM). The DIIM is designed by modifying the vanilla cross-attention mechanism, which can promote the extraction of the discrepancy information of the source images. Meanwhile, the ACIIM is devised by alternately using the vanilla cross-attention mechanism, which can fully mine common information and integrate long dependencies. Moreover, the successful training of ATFuse is facilitated by a proposed segmented pixel loss function, which provides a good trade-off for texture detail and salient structure preservation. The qualitative and quantitative results on public datasets indicate our ATFFuse is effective and superior compared to other state-of-the-art methods.