 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaming Generative Synthetic Data for X-ray Prohibited Item Detection
Nov 19, 2025


Training prohibited item detection models requires a large amount of X-ray security images, but collecting and annotating these images is time-consuming and laborious. To address data insufficiency, X-ray security image synthesis methods composite images to scale up datasets. However, previous methods primarily follow a two-stage pipeline, where they implement labor-intensive foreground extraction in the first stage and then composite images in the second stage. Such a pipeline introduces inevitable extra labor cost and is not efficient. In this paper, we propose a one-stage X-ray security image synthesis pipeline (Xsyn) based on text-to-image generation, which incorporates two effective strategies to improve the usability of synthetic images. The Cross-Attention Refinement (CAR) strategy leverages the cross-attention map from the diffusion model to refine the bounding box annotation. The Background Occlusion Modeling (BOM) strategy explicitly models background occlusion in the latent space to enhance imaging complexity. To the best of our knowledge, compared with previous methods, Xsyn is the first to achieve high-quality X-ray security image synthesis without extra labor cost. Experiments demonstrate that our method outperforms all previous methods with 1.2% mAP improvement, and the synthetic images generated by our method are beneficial to improve prohibited item detection performance across various X-ray security datasets and detectors. Code is available at https://github.com/pILLOW-1/Xsyn/.
CDI3D: Cross-guided Dense-view Interpolation for 3D Reconstruction
Mar 11, 20253D object reconstruction from single-view image is a fundamental task in computer vision with wide-ranging applications. Recent advancements in Large Reconstruction Models (LRMs) have shown great promise in leveraging multi-view images generated by 2D diffusion models to extract 3D content. However, challenges remain as 2D diffusion models often struggle to produce dense images with strong multi-view consistency, and LRMs tend to amplify these inconsistencies during the 3D reconstruction process. Addressing these issues is critical for achieving high-quality and efficient 3D reconstruction. In this paper, we present CDI3D, a feed-forward framework designed for efficient, high-quality image-to-3D generation with view interpolation. To tackle the aforementioned challenges, we propose to integrate 2D diffusion-based view interpolation into the LRM pipeline to enhance the quality and consistency of the generated mesh. Specifically, our approach introduces a Dense View Interpolation (DVI) module, which synthesizes interpolated images between main views generated by the 2D diffusion model, effectively densifying the input views with better multi-view consistency. We also design a tilt camera pose trajectory to capture views with different elevations and perspectives. Subsequently, we employ a tri-plane-based mesh reconstruction strategy to extract robust tokens from these interpolated and original views, enabling the generation of high-quality 3D meshes with superior texture and geometry. Extensive experiments demonstrate that our method significantly outperforms previous state-of-the-art approaches across various benchmarks, producing 3D content with enhanced texture fidelity and geometric accuracy.
Pandora3D: A Comprehensive Framework for High-Quality 3D Shape and Texture Generation
Feb 21, 2025This report presents a comprehensive framework for generating high-quality 3D shapes and textures from diverse input prompts, including single images, multi-view images, and text descriptions. The framework consists of 3D shape generation and texture generation. (1). The 3D shape generation pipeline employs a Variational Autoencoder (VAE) to encode implicit 3D geometries into a latent space and a diffusion network to generate latents conditioned on input prompts, with modifications to enhance model capacity. An alternative Artist-Created Mesh (AM) generation approach is also explored, yielding promising results for simpler geometries. (2). Texture generation involves a multi-stage process starting with frontal images generation followed by multi-view images generation, RGB-to-PBR texture conversion, and high-resolution multi-view texture refinement. A consistency scheduler is plugged into every stage, to enforce pixel-wise consistency among multi-view textures during inference, ensuring seamless integration. The pipeline demonstrates effective handling of diverse input formats, leveraging advanced neural architectures and novel methodologies to produce high-quality 3D content. This report details the system architecture, experimental results, and potential future directions to improve and expand the framework. The source code and pretrained weights are released at: https://github.com/Tencent/Tencent-XR-3DGen.
MARS: Mesh AutoRegressive Model for 3D Shape Detailization
Feb 17, 2025

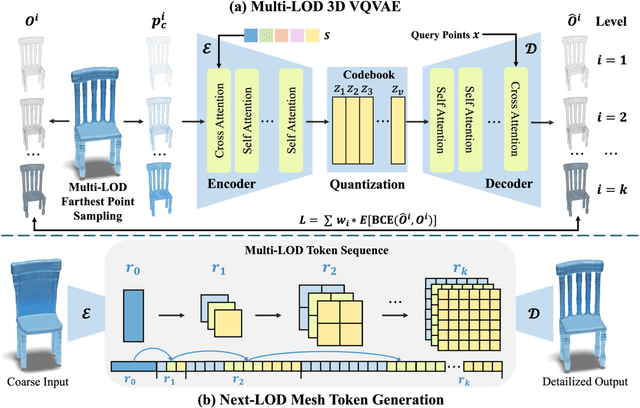

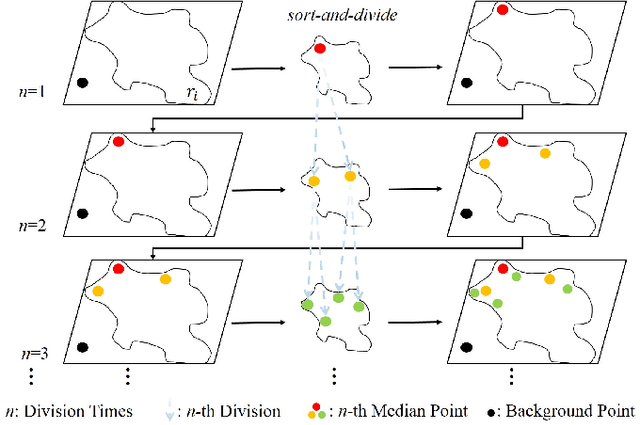
State-of-the-art methods for mesh detailization predominantly utilize Generative Adversarial Networks (GANs) to generate detailed meshes from coarse ones. These methods typically learn a specific style code for each category or similar categories without enforcing geometry supervision across different Levels of Detail (LODs). Consequently, such methods often fail to generalize across a broader range of categories and cannot ensure shape consistency throughout the detailization process. In this paper, we introduce MARS, a novel approach for 3D shape detailization. Our method capitalizes on a novel multi-LOD, multi-category mesh representation to learn shape-consistent mesh representations in latent space across different LODs. We further propose a mesh autoregressive model capable of generating such latent representations through next-LOD token prediction. This approach significantly enhances the realism of the generated shapes. Extensive experiments conducted on the challenging 3D Shape Detailization benchmark demonstrate that our proposed MARS model achieves state-of-the-art performance, surpassing existing methods in both qualitative and quantitative assessments. Notably, the model's capability to generate fine-grained details while preserving the overall shape integrity is particularly commendable.
BGM: Background Mixup for X-ray Prohibited Items Detection
Nov 30, 2024Prohibited item detection is crucial for ensuring public safety, yet current X-ray image-based detection methods often lack comprehensive data-driven exploration. This paper introduces a novel data augmentation approach tailored for prohibited item detection, leveraging unique characteristics inherent to X-ray imagery. Our method is motivated by observations of physical properties including: 1) X-ray Transmission Imagery: Unlike reflected light images, transmitted X-ray pixels represent composite information from multiple materials along the imaging path. 2) Material-based Pseudo-coloring: Pseudo-color rendering in X-ray images correlates directly with material properties, aiding in material distinction. Building on a novel perspective from physical properties, we propose a simple yet effective X-ray image augmentation technique, Background Mixup (BGM), for prohibited item detection in security screening contexts. The essence is the rich background simulation of X-ray images to induce the model to increase its attention to the foreground. The approach introduces 1) contour information of baggage and 2) variation of material information into the original image by Mixup at patch level. Background Mixup is plug-and-play, parameter-free, highly generalizable and provides an effective solution to the limitations of classical visual augmentations in non-reflected light imagery. When implemented with different high-performance detectors, our augmentation method consistently boosts performance across diverse X-ray datasets from various devices and environments. Extensive experimental results demonstrate that our approach surpasses strong baselines while maintaining similar training resources.
LAM3D: Large Image-Point-Cloud Alignment Model for 3D Reconstruction from Single Image
May 24, 2024
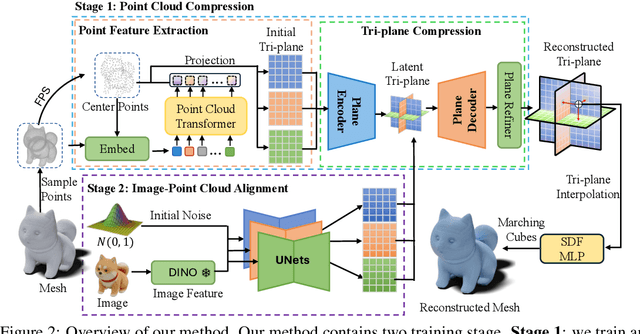

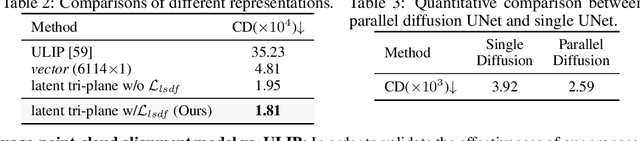
Large Reconstruction Models have made significant strides in the realm of automated 3D content generation from single or multiple input images. Despite their success, these models often produce 3D meshes with geometric inaccuracies, stemming from the inherent challenges of deducing 3D shapes solely from image data. In this work, we introduce a novel framework, the Large Image and Point Cloud Alignment Model (LAM3D), which utilizes 3D point cloud data to enhance the fidelity of generated 3D meshes. Our methodology begins with the development of a point-cloud-based network that effectively generates precise and meaningful latent tri-planes, laying the groundwork for accurate 3D mesh reconstruction. Building upon this, our Image-Point-Cloud Feature Alignment technique processes a single input image, aligning to the latent tri-planes to imbue image features with robust 3D information. This process not only enriches the image features but also facilitates the production of high-fidelity 3D meshes without the need for multi-view input, significantly reducing geometric distortions. Our approach achieves state-of-the-art high-fidelity 3D mesh reconstruction from a single image in just 6 seconds, and experiments on various datasets demonstrate its effectiveness.
NeuSDFusion: A Spatial-Aware Generative Model for 3D Shape Completion, Reconstruction, and Generation
Mar 27, 2024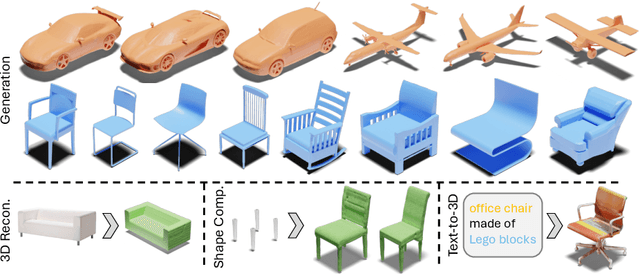
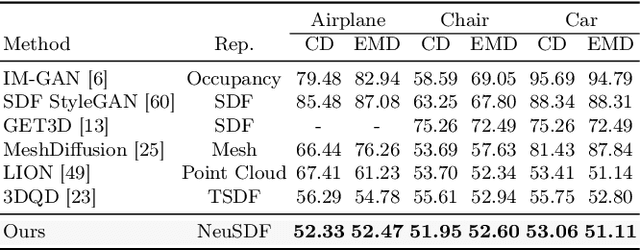

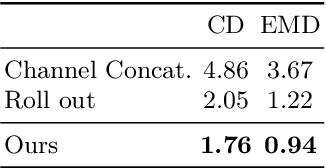
3D shape generation aims to produce innovative 3D content adhering to specific conditions and constraints. Existing methods often decompose 3D shapes into a sequence of localized components, treating each element in isolation without considering spatial consistency. As a result, these approaches exhibit limited versatility in 3D data representation and shape generation, hindering their ability to generate highly diverse 3D shapes that comply with the specified constraints. In this paper, we introduce a novel spatial-aware 3D shape generation framework that leverages 2D plane representations for enhanced 3D shape modeling. To ensure spatial coherence and reduce memory usage, we incorporate a hybrid shape representation technique that directly learns a continuous signed distance field representation of the 3D shape using orthogonal 2D planes. Additionally, we meticulously enforce spatial correspondences across distinct planes using a transformer-based autoencoder structure, promoting the preservation of spatial relationships in the generated 3D shapes. This yields an algorithm that consistently outperforms state-of-the-art 3D shape generation methods on various tasks, including unconditional shape generation, multi-modal shape completion, single-view reconstruction, and text-to-shape synthesis.
Frankenstein: Generating Semantic-Compositional 3D Scenes in One Tri-Plane
Mar 24, 2024



We present Frankenstein, a diffusion-based framework that can generate semantic-compositional 3D scenes in a single pass. Unlike existing methods that output a single, unified 3D shape, Frankenstein simultaneously generates multiple separated shapes, each corresponding to a semantically meaningful part. The 3D scene information is encoded in one single tri-plane tensor, from which multiple Singed Distance Function (SDF) fields can be decoded to represent the compositional shapes. During training, an auto-encoder compresses tri-planes into a latent space, and then the denoising diffusion process is employed to approximate the distribution of the compositional scenes. Frankenstein demonstrates promising results in generating room interiors as well as human avatars with automatically separated parts. The generated scenes facilitate many downstream applications, such as part-wise re-texturing, object rearrangement in the room or avatar cloth re-targeting.
BlockFusion: Expandable 3D Scene Generation using Latent Tri-plane Extrapolation
Jan 31, 2024



We present BlockFusion, a diffusion-based model that generates 3D scenes as unit blocks and seamlessly incorporates new blocks to extend the scene. BlockFusion is trained using datasets of 3D blocks that are randomly cropped from complete 3D scene meshes. Through per-block fitting, all training blocks are converted into the hybrid neural fields: with a tri-plane containing the geometry features, followed by a Multi-layer Perceptron (MLP) for decoding the signed distance values. A variational auto-encoder is employed to compress the tri-planes into the latent tri-plane space, on which the denoising diffusion process is performed. Diffusion applied to the latent representations allows for high-quality and diverse 3D scene generation. To expand a scene during generation, one needs only to append empty blocks to overlap with the current scene and extrapolate existing latent tri-planes to populate new blocks. The extrapolation is done by conditioning the generation process with the feature samples from the overlapping tri-planes during the denoising iterations. Latent tri-plane extrapolation produces semantically and geometrically meaningful transitions that harmoniously blend with the existing scene. A 2D layout conditioning mechanism is used to control the placement and arrangement of scene elements. Experimental results indicate that BlockFusion is capable of generating diverse, geometrically consistent and unbounded large 3D scenes with unprecedented high-quality shapes in both indoor and outdoor scenarios.
RGB-based Category-level Object Pose Estimation via Decoupled Metric Scale Recovery
Sep 19, 2023While showing promising results, recent RGB-D camera-based category-level object pose estimation methods have restricted applications due to the heavy reliance on depth sensors. RGB-only methods provide an alternative to this problem yet suffer from inherent scale ambiguity stemming from monocular observations. In this paper, we propose a novel pipeline that decouples the 6D pose and size estimation to mitigate the influence of imperfect scales on rigid transformations. Specifically, we leverage a pre-trained monocular estimator to extract local geometric information, mainly facilitating the search for inlier 2D-3D correspondence. Meanwhile, a separate branch is designed to directly recover the metric scale of the object based on category-level statistics. Finally, we advocate using the RANSAC-P$n$P algorithm to robustly solve for 6D object pose. Extensive experiments have been conducted on both synthetic and real datasets, demonstrating the superior performance of our method over previous state-of-the-art RGB-based approaches, especially in terms of rotation accuracy.