 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACE: Attribution-Controlled Knowledge Editing for Multi-hop Factual Recall
Oct 09, 2025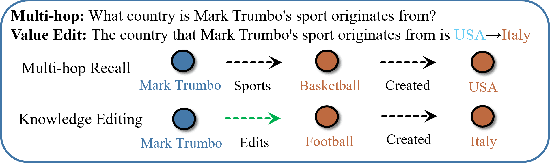

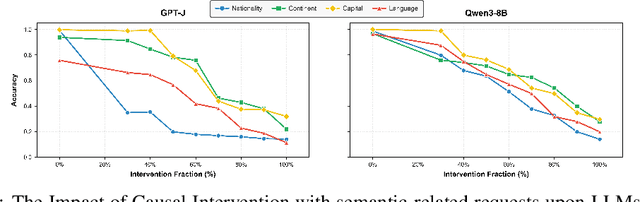
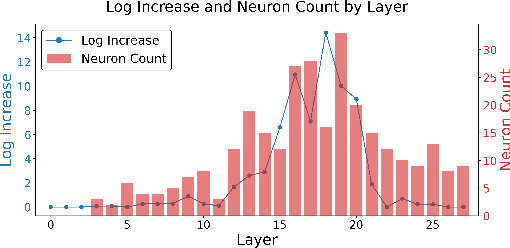
Large Language Models (LLMs) require efficient knowledge editing (KE) to update factual information, yet existing methods exhibit significant performance decay in multi-hop factual recall. This failure is particularly acute when edits involve intermediate implicit subjects within reasoning chains. Through causal analysis, we reveal that this limitation stems from an oversight of how chained knowledge is dynamically represented and utilized at the neuron level. We discover that during multi hop reasoning, implicit subjects function as query neurons, which sequentially activate corresponding value neurons across transformer layers to accumulate information toward the final answer, a dynamic prior KE work has overlooked. Guided by this insight, we propose ACE: Attribution-Controlled Knowledge Editing for Multi-hop Factual Recall, a framework that leverages neuron-level attribution to identify and edit these critical query-value (Q-V) pathways. ACE provides a mechanistically grounded solution for multi-hop KE, empirically outperforming state-of-the-art methods by 9.44% on GPT-J and 37.46% on Qwen3-8B. Our analysis further reveals more fine-grained activation patterns in Qwen3 and demonstrates that the semantic interpretability of value neurons is orchestrated by query-driven accumulation. These findings establish a new pathway for advancing KE capabilities based on the principled understanding of internal reasoning mechanisms.
LocalDyGS: Multi-view Global Dynamic Scene Modeling via Adaptive Local Implicit Feature Decoupling
Jul 03, 2025Due to the complex and highly dynamic motions in the real world, synthesizing dynamic videos from multi-view inputs for arbitrary viewpoints is challenging. Previous works based on neural radiance field or 3D Gaussian splatting are limited to modeling fine-scale motion, greatly restricting their application. In this paper, we introduce LocalDyGS, which consists of two parts to adapt our method to both large-scale and fine-scale motion scenes: 1) We decompose a complex dynamic scene into streamlined local spaces defined by seeds, enabling global modeling by capturing motion within each local space. 2) We decouple static and dynamic features for local space motion modeling. A static feature shared across time steps captures static information, while a dynamic residual field provides time-specific features. These are combined and decoded to generate Temporal Gaussians, modeling motion within each local space. As a result, we propose a novel dynamic scene reconstruction framework to model highly dynamic real-world scenes more realistically. Our method not only demonstrates competitive performance on various fine-scale datasets compared to state-of-the-art (SOTA) methods, but also represents the first attempt to model larger and more complex highly dynamic scenes. Project page: https://wujh2001.github.io/LocalDyGS/.
MLICv2: Enhanced Multi-Reference Entropy Modeling for Learned Image Compression
Apr 27, 2025Recent advancements in learned image compression (LIC) have yielded impressive performance gains. Notably, the learned image compression models with multi-reference entropy models (MLIC series) have significantly outperformed existing traditional image codecs such as the Versatile Video Coding (VVC) Intra. In this paper, we present MLICv2 and MLICv2$^+$, enhanced versions of the MLIC series, featuring improved transform techniques, entropy modeling, and instance adaptability. For better transform, we introduce a simple token mixing transform block inspired by the meta transformer architecture, addressing the performance degradation at high bit-rates observed in previous MLIC series while maintaining computational efficiency. To enhance entropy modeling, we propose a hyperprior-guided global correlation prediction, enabling the capture of global contexts in the initial slice of the latent representation. We also develop a channel reweighting module to dynamically prioritize important channels within each context. Additionally, advanced positional embedding for context modeling and selective compression with guided optimization are investigated. To boost instance adaptability, we employ stochastic Gumbel annealing to iteratively refine the latent representation according to the rate-distortion optimization of a specific input image. This approach further enhances performance without impacting decoding speed. Experimental results demonstrate that our MLICv2 and MLICv2$^+$ achieve state-of-the-art performance, reducing Bjontegaard-Delta rate (BD-rate) by 16.54%, 21.61%, 16.05% and 20.46%, 24.35%, 19.14% respectively, compared to VTM-17.0 Intra on the Kodak, Tecnick, CLIC Pro Val dataset, respectively.
L-LBVC: Long-Term Motion Estimation and Prediction for Learned Bi-Directional Video Compression
Apr 03, 2025Recently, learned video compression (LVC) has shown superior performance under low-delay configuration. However, the performance of learned bi-directional video compression (LBVC) still lags behind traditional bi-directional coding. The performance gap mainly arises from inaccurate long-term motion estimation and prediction of distant frames, especially in large motion scenes. To solve these two critical problems, this paper proposes a novel LBVC framework, namely L-LBVC. Firstly, we propose an adaptive motion estimation module that can handle both short-term and long-term motions. Specifically, we directly estimate the optical flows for adjacent frames and non-adjacent frames with small motions. For non-adjacent frames with large motions, we recursively accumulate local flows between adjacent frames to estimate long-term flows. Secondly, we propose an adaptive motion prediction module that can largely reduce the bit cost for motion coding. To improve the accuracy of long-term motion prediction, we adaptively downsample reference frames during testing to match the motion ranges observed during training. Experiments show that our L-LBVC significantly outperforms previous state-of-the-art LVC methods and even surpasses VVC (VTM) on some test datasets under random access configuration.
Enhancing 3D Gaussian Splatting Compression via Spatial Condition-based Prediction
Mar 30, 2025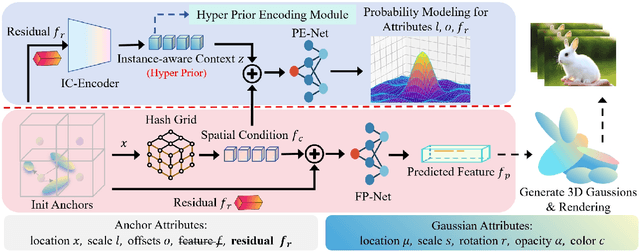
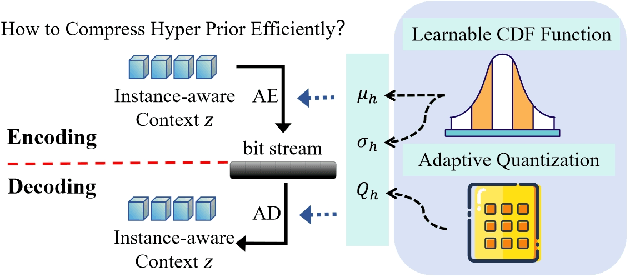

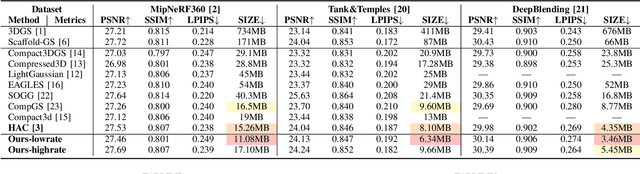
Recently, 3D Gaussian Spatting (3DGS) has gained widespread attention in Novel View Synthesis (NVS) due to the remarkable real-time rendering performance. However, the substantial cost of storage and transmission of vanilla 3DGS hinders its further application (hundreds of megabytes or even gigabytes for a single scene). Motivated by the achievements of prediction in video compression, we introduce the prediction technique into the anchor-based Gaussian representation to effectively reduce the bit rate. Specifically, we propose a spatial condition-based prediction module to utilize the grid-captured scene information for prediction, with a residual compensation strategy designed to learn the missing fine-grained information. Besides, to further compress the residual, we propose an instance-aware hyper prior, developing a structure-aware and instance-aware entropy model. Extensive experiments demonstrate the effectiveness of our prediction-based compression framework and each technical component. Even compared with SOTA compression method, our framework still achieves a bit rate savings of 24.42 percent. Code is to be released!
Towards Reliable Time Series Forecasting under Future Uncertainty: Ambiguity and Novelty Rejection Mechanisms
Mar 25, 2025In real-world time series forecasting, uncertainty and lack of reliable evaluation pose significant challenges. Notably, forecasting errors often arise from underfitting in-distribution data and failing to handle out-of-distribution inputs. To enhance model reliability, we introduce a dual rejection mechanism combining ambiguity and novelty rejection. Ambiguity rejection, using prediction error variance, allows the model to abstain under low confidence, assessed through historical error variance analysis without future ground truth. Novelty rejection, employing Variational Autoencoders and Mahalanobis distance, detects deviations from training data. This dual approach improves forecasting reliability in dynamic environments by reducing errors and adapting to data changes, advancing reliability in complex scenarios.
CDI3D: Cross-guided Dense-view Interpolation for 3D Reconstruction
Mar 11, 20253D object reconstruction from single-view image is a fundamental task in computer vision with wide-ranging applications. Recent advancements in Large Reconstruction Models (LRMs) have shown great promise in leveraging multi-view images generated by 2D diffusion models to extract 3D content. However, challenges remain as 2D diffusion models often struggle to produce dense images with strong multi-view consistency, and LRMs tend to amplify these inconsistencies during the 3D reconstruction process. Addressing these issues is critical for achieving high-quality and efficient 3D reconstruction. In this paper, we present CDI3D, a feed-forward framework designed for efficient, high-quality image-to-3D generation with view interpolation. To tackle the aforementioned challenges, we propose to integrate 2D diffusion-based view interpolation into the LRM pipeline to enhance the quality and consistency of the generated mesh. Specifically, our approach introduces a Dense View Interpolation (DVI) module, which synthesizes interpolated images between main views generated by the 2D diffusion model, effectively densifying the input views with better multi-view consistency. We also design a tilt camera pose trajectory to capture views with different elevations and perspectives. Subsequently, we employ a tri-plane-based mesh reconstruction strategy to extract robust tokens from these interpolated and original views, enabling the generation of high-quality 3D meshes with superior texture and geometry. Extensive experiments demonstrate that our method significantly outperforms previous state-of-the-art approaches across various benchmarks, producing 3D content with enhanced texture fidelity and geometric accuracy.
The Multi-Trip Time-Dependent Mix Vehicle Routing Problem for Hybrid Autonomous Shared Delivery Location and Traditional Door-to-Door Delivery Modes
Mar 07, 2025Rising labor costs and increasing logistical demands pose significant challenges to modern delivery systems. Automated Electric Vehicles (AEVs) could reduce reliance on delivery personnel and increase route flexibility, but their adoption is limited due to varying customer acceptance and integration complexities. Shared Distribution Locations (SDLs) offer an alternative to door-to-door (D2D) delivery by providing a wider delivery window and serving multiple community customers, thereby improving last-mile logistics through reduced delivery time, lower costs, and higher customer satisfaction.This paper introduces the Multi-Trip Time-Dependent Hybrid Vehicle Routing Problem (MTTD-MVRP), a challenging variant of the Vehicle Routing Problem (VRP) that combines Autonomous Electric Vehicles (AEVs) with conventional vehicles. The problem's complexity arises from factors such as time-dependent travel speeds, strict time windows, battery limitations, and driver labor constraints, while integrating both SDLs and D2D deliveries. To solve the MTTD-MVRP efficiently, we develop a tailored meta-heuristic based on Adaptive Large Neighborhood Search (ALNS) augmented with column generation (CG). This approach intensively explores the solution space using problem-specific operators and adaptively refines solutions, balancing high-quality outcomes with computational effort. Extensive experiments show that the proposed method delivers near-optimal solutions for large-scale instances within practical time limits.From a managerial perspective, our findings highlight the importance of integrating autonomous and human-driven vehicles in last-mile logistics. Decision-makers can leverage SDLs to reduce operational costs and carbon footprints while still accommodating customers who require or prefer D2D services.
Pandora3D: A Comprehensive Framework for High-Quality 3D Shape and Texture Generation
Feb 21, 2025This report presents a comprehensive framework for generating high-quality 3D shapes and textures from diverse input prompts, including single images, multi-view images, and text descriptions. The framework consists of 3D shape generation and texture generation. (1). The 3D shape generation pipeline employs a Variational Autoencoder (VAE) to encode implicit 3D geometries into a latent space and a diffusion network to generate latents conditioned on input prompts, with modifications to enhance model capacity. An alternative Artist-Created Mesh (AM) generation approach is also explored, yielding promising results for simpler geometries. (2). Texture generation involves a multi-stage process starting with frontal images generation followed by multi-view images generation, RGB-to-PBR texture conversion, and high-resolution multi-view texture refinement. A consistency scheduler is plugged into every stage, to enforce pixel-wise consistency among multi-view textures during inference, ensuring seamless integration. The pipeline demonstrates effective handling of diverse input formats, leveraging advanced neural architectures and novel methodologies to produce high-quality 3D content. This report details the system architecture, experimental results, and potential future directions to improve and expand the framework. The source code and pretrained weights are released at: https://github.com/Tencent/Tencent-XR-3DGen.
DoubleDiffusion: Combining Heat Diffusion with Denoising Diffusion for Generative Learning on 3D Meshes
Jan 06, 2025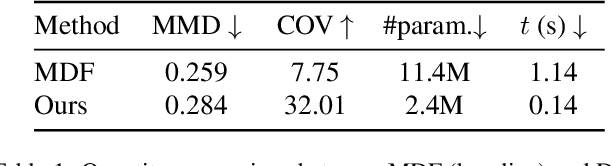

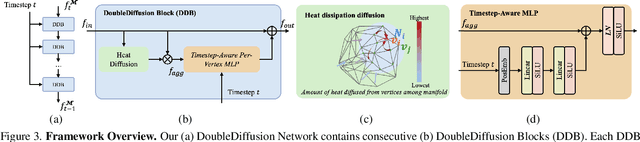

This paper proposes DoubleDiffusion, a novel framework that combines heat dissipation diffusion and denoising diffusion for direct generative learning on 3D mesh surfaces. Our approach addresses the challenges of generating continuous signal distributions residing on a curve manifold surface. Unlike previous methods that rely on unrolling 3D meshes into 2D or adopting field representations, DoubleDiffusion leverages the Laplacian-Beltrami operator to process features respecting the mesh structure. This combination enables effective geometry-aware signal diffusion across the underlying geometry. As shown in Fig.~\ref{fig:teaser}, we demonstrate that DoubleDiffusion has the ability to generate RGB signal distributions on complex 3D mesh surfaces and achieves per-category shape-conditioned texture generation across different shape geometry. Our work contributes a new direction in diffusion-based generative modeling on 3D surfaces, with potential applications in the field of 3D asset generation.