 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoWorld: Geometric World Models
Feb 26, 2026Energy-based predictive world models provide a powerful approach for multi-step visual planning by reasoning over latent energy landscapes rather than generating pixels. However, existing approaches face two major challenges: (i) their latent representations are typically learned in Euclidean space, neglecting the underlying geometric and hierarchical structure among states, and (ii) they struggle with long-horizon prediction, which leads to rapid degradation across extended rollouts. To address these challenges, we introduce GeoWorld, a geometric world model that preserves geometric structure and hierarchical relations through a Hyperbolic JEPA, which maps latent representations from Euclidean space onto hyperbolic manifolds. We further introduce Geometric Reinforcement Learning for energy-based optimization, enabling stable multi-step planning in hyperbolic latent space. Extensive experiments on CrossTask and COIN demonstrate around 3% SR improvement in 3-step planning and 2% SR improvement in 4-step planning compared to the state-of-the-art V-JEPA 2. Project website: https://steve-zeyu-zhang.github.io/GeoWorld.
Conformal Point and the Calibrated Conic
Jan 16, 2026This gives some information about the conformal point and the calibrating conic, and their relationship one to the other. These concepts are useful for visualizing image geometry, and lead to intuitive ways to compute geometry, such as angles and directions in an image.
On the Reliability of Vision-Language Models Under Adversarial Frequency-Domain Perturbations
Jul 30, 2025Vision-Language Models (VLMs) are increasingly used as perceptual modules for visual content reasoning, including through captioning and DeepFake detection. In this work, we expose a critical vulnerability of VLMs when exposed to subtle, structured perturbations in the frequency domain. Specifically, we highlight how these feature transformations undermine authenticity/DeepFake detection and automated image captioning tasks. We design targeted image transformations, operating in the frequency domain to systematically adjust VLM outputs when exposed to frequency-perturbed real and synthetic images. We demonstrate that the perturbation injection method generalizes across five state-of-the-art VLMs which includes different-parameter Qwen2/2.5 and BLIP models. Experimenting across ten real and generated image datasets reveals that VLM judgments are sensitive to frequency-based cues and may not wholly align with semantic content. Crucially, we show that visually-imperceptible spatial frequency transformations expose the fragility of VLMs deployed for automated image captioning and authenticity detection tasks. Our findings under realistic, black-box constraints challenge the reliability of VLMs, underscoring the need for robust multimodal perception systems.
Probability Density Geodesics in Image Diffusion Latent Space
Apr 09, 2025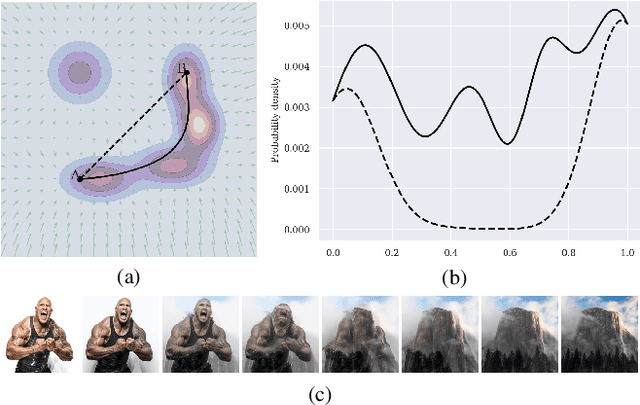
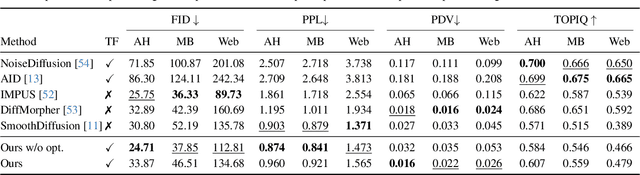
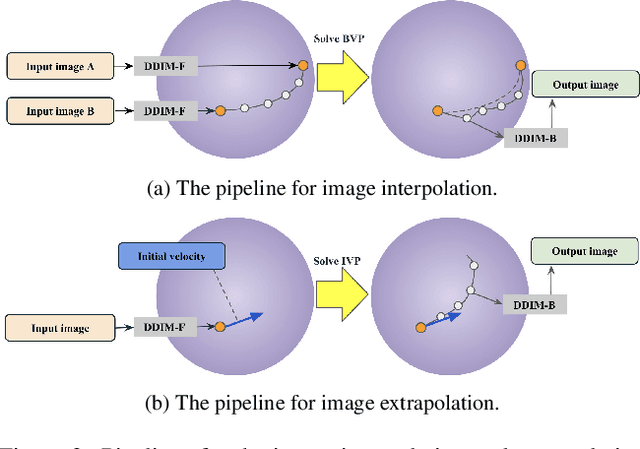
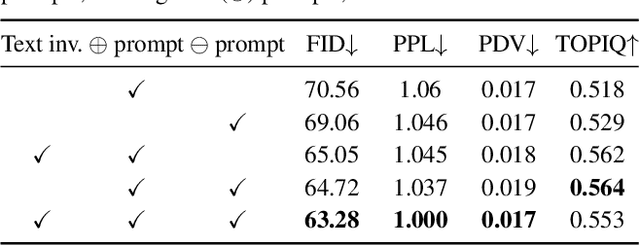
Diffusion models indirectly estimate the probability density over a data space, which can be used to study its structure. In this work, we show that geodesics can be computed in diffusion latent space, where the norm induced by the spatially-varying inner product is inversely proportional to the probability density. In this formulation, a path that traverses a high density (that is, probable) region of image latent space is shorter than the equivalent path through a low density region. We present algorithms for solving the associated initial and boundary value problems and show how to compute the probability density along the path and the geodesic distance between two points. Using these techniques, we analyze how closely video clips approximate geodesics in a pre-trained image diffusion space. Finally, we demonstrate how these techniques can be applied to training-free image sequence interpolation and extrapolation, given a pre-trained image diffusion model.
NF-SLAM: Effective, Normalizing Flow-supported Neural Field representations for object-level visual SLAM in automotive applications
Mar 14, 2025We propose a novel, vision-only object-level SLAM framework for automotive applications representing 3D shapes by implicit signed distance functions. Our key innovation consists of augmenting the standard neural representation by a normalizing flow network. As a result, achieving strong representation power on the specific class of road vehicles is made possible by compact networks with only 16-dimensional latent codes. Furthermore, the newly proposed architecture exhibits a significant performance improvement in the presence of only sparse and noisy data, which is demonstrated through comparative experiments on synthetic data. The module is embedded into the back-end of a stereo-vision based framework for joint, incremental shape optimization. The loss function is given by a combination of a sparse 3D point-based SDF loss, a sparse rendering loss, and a semantic mask-based silhouette-consistency term. We furthermore leverage semantic information to determine keypoint extraction density in the front-end. Finally, experimental results on real-world data reveal accurate and reliable performance comparable to alternative frameworks that make use of direct depth readings. The proposed method performs well with only sparse 3D points obtained from bundle adjustment, and eventually continues to deliver stable results even under exclusive use of the mask-consistency term.
Exploring Bias in over 100 Text-to-Image Generative Models
Mar 11, 2025



We investigate bias trends in text-to-image generative models over time, focusing on the increasing availability of models through open platforms like Hugging Face. While these platforms democratize AI, they also facilitate the spread of inherently biased models, often shaped by task-specific fine-tuning. Ensuring ethical and transparent AI deployment requires robust evaluation frameworks and quantifiable bias metrics. To this end, we assess bias across three key dimensions: (i) distribution bias, (ii) generative hallucination, and (iii) generative miss-rate. Analyzing over 100 models, we reveal how bias patterns evolve over time and across generative tasks. Our findings indicate that artistic and style-transferred models exhibit significant bias, whereas foundation models, benefiting from broader training distributions, are becoming progressively less biased. By identifying these systemic trends, we contribute a large-scale evaluation corpus to inform bias research and mitigation strategies, fostering more responsible AI development. Keywords: Bias, Ethical AI, Text-to-Image, Generative Models, Open-Source Models
Motion Anything: Any to Motion Generation
Mar 10, 2025Conditional motion generation has been extensively studied in computer vision, yet two critical challenges remain. First, while masked autoregressive methods have recently outperformed diffusion-based approaches, existing masking models lack a mechanism to prioritize dynamic frames and body parts based on given conditions. Second, existing methods for different conditioning modalities often fail to integrate multiple modalities effectively, limiting control and coherence in generated motion. To address these challenges, we propose Motion Anything, a multimodal motion generation framework that introduces an Attention-based Mask Modeling approach, enabling fine-grained spatial and temporal control over key frames and actions. Our model adaptively encodes multimodal conditions, including text and music, improving controllability. Additionally, we introduce Text-Motion-Dance (TMD), a new motion dataset consisting of 2,153 pairs of text, music, and dance, making it twice the size of AIST++, thereby filling a critical gap in the community. Extensive experiments demonstrate that Motion Anything surpasses state-of-the-art methods across multiple benchmarks, achieving a 15% improvement in FID on HumanML3D and showing consistent performance gains on AIST++ and TMD. See our project website https://steve-zeyu-zhang.github.io/MotionAnything
DoubleDiffusion: Combining Heat Diffusion with Denoising Diffusion for Generative Learning on 3D Meshes
Jan 06, 2025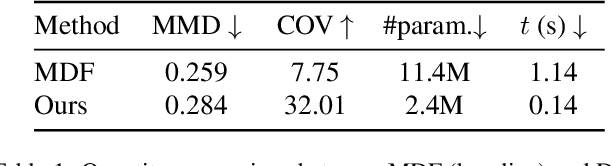

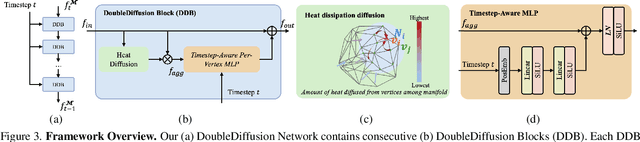

This paper proposes DoubleDiffusion, a novel framework that combines heat dissipation diffusion and denoising diffusion for direct generative learning on 3D mesh surfaces. Our approach addresses the challenges of generating continuous signal distributions residing on a curve manifold surface. Unlike previous methods that rely on unrolling 3D meshes into 2D or adopting field representations, DoubleDiffusion leverages the Laplacian-Beltrami operator to process features respecting the mesh structure. This combination enables effective geometry-aware signal diffusion across the underlying geometry. As shown in Fig.~\ref{fig:teaser}, we demonstrate that DoubleDiffusion has the ability to generate RGB signal distributions on complex 3D mesh surfaces and achieves per-category shape-conditioned texture generation across different shape geometry. Our work contributes a new direction in diffusion-based generative modeling on 3D surfaces, with potential applications in the field of 3D asset generation.
On the Fairness, Diversity and Reliability of Text-to-Image Generative Models
Nov 21, 2024



The widespread availability of multimodal generative models has sparked critical discussions on their fairness, reliability, and potential for misuse. While text-to-image models can produce high-fidelity, user-guided images, they also exhibit unpredictable behavior and vulnerabilities, which can be exploited to manipulate class or concept representations. To address this, we propose an evaluation framework designed to assess model reliability through their responses to globally- and locally-applied `semantic' perturbations in the embedding space, pinpointing inputs that trigger unreliable behavior. Our approach offers deeper insights into two essential aspects: (i) generative diversity, evaluating the breadth of visual representations for learned concepts, and (ii) generative fairness, examining how removing concepts from input prompts affects semantic guidance. Beyond these evaluations, our method lays the groundwork for detecting unreliable, bias-injected models and retrieval of bias provenance. We will release our code. Keywords: Fairness, Reliability, AI Ethics, Bias, Text-to-Image Models
Safety Without Semantic Disruptions: Editing-free Safe Image Generation via Context-preserving Dual Latent Reconstruction
Nov 21, 2024



Training multimodal generative models on large, uncurated datasets can result in users being exposed to harmful, unsafe and controversial or culturally-inappropriate outputs. While model editing has been proposed to remove or filter undesirable concepts in embedding and latent spaces, it can inadvertently damage learned manifolds, distorting concepts in close semantic proximity. We identify limitations in current model editing techniques, showing that even benign, proximal concepts may become misaligned. To address the need for safe content generation, we propose a modular, dynamic solution that leverages safety-context embeddings and a dual reconstruction process using tunable weighted summation in the latent space to generate safer images. Our method preserves global context without compromising the structural integrity of the learned manifolds. We achieve state-of-the-art results on safe image generation benchmarks, while offering controllable variation of model safety. We identify trade-offs between safety and censorship, which presents a necessary perspective in the development of ethical AI models. We will release our code. Keywords: Text-to-Image Models, Generative AI, Safety, Reliability, Model Editing