 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorldOlympiad: Can Your World Model Survive a Triathlon?
Jun 09, 2026We introduce WorldOlympiad, a benchmark for diagnosing video-based world models across physical faithfulness, geometric consistency, and interaction fidelity. While existing benchmarks often focus on visual quality, semantic alignment, or short-term temporal coherence, they provide limited insight into whether generated videos obey physical rules, preserve coherent 3D structure, and sustain controllable interactions over long horizons. To address this gap, WorldOlympiad decomposes world-model evaluation into three complementary dimensions. The physical track uses object segmentation and MLLM-as-judge to assess whether generated videos follow interpretable rules in mechanics, thermal phenomena, and material properties. The geometry track reconstructs generated videos with Gaussian splatting and evaluates structural consistency, cross-view coherence, and camera-trajectory alignment. The interaction track assesses whether generated rollouts follow complex action prompts and maintain smooth, coherent transitions across consecutive video chunks. WorldOlympiad further covers three major downstream scenarios, including gaming, robotics, and general real-world videos, capturing diverse challenges from interactive control and embodied manipulation to open-domain motion and camera dynamics. Together, these tracks and scenarios form a scalable and interpretable evaluation suite that exposes failure modes beyond generic video quality. Experiments on state-of-the-art models reveal substantial gaps in physical reasoning, 3D consistency, and long-horizon interaction, underscoring the need for more structured evaluation protocols for generative world models.
ReCA: Multi-Shot Long Video Extrapolation via Recursive Context Allocation
May 26, 2026Minute-scale cinematic video generation is a central challenge for generative video models. Existing paradigms address only fragments of this challenge: single-shot extrapolation preserves an anchor but lacks cinematic structure, while multi-shot storytelling imposes structure yet remains free to invent its visual states rather than continue an observed one. We define Multi-Shot Video Extrapolation (MSVE), a task that extends an observed frame or clip into a sequence of cinematically structured shots while preserving anchor state and advancing narrative intent. This setting operates under the finite per-call generation budget of short-video models. We identify three coupled bottlenecks: (1) global planners over-specify unsupported details from full screenplays; (2) shot-level prompts dilute task-relevant state when carrying the complete story; and (3) temporal chaining turns generated frames into a lossy memory in which identity, scene, object, and action state decay. MSVE reveals that long-video failure is not merely a limitation of context length, but a failure of context allocation. We propose Recursive Context Allocation (ReCA), an inference-time framework that allocates context hierarchically across planning and generation. ReCA recursively decomposes MSVE into context-bounded subproblems, invokes frozen generators at leaf nodes, and propagates structured state updates across time. To evaluate this setting, we further propose MSVE-Bench and NB-Q, a source-grounded protocol with prompts purpose-built for 3 to 5 minute long-video generation, a regime not addressed by existing short-clip benchmarks. Compared to previous methods, ReCA improves average normalized score by 8 to 16 percent over the strongest competing controller and improves multi-shot consistency metrics by 28 to 43 percent. View the project page at https://reca.vmv.re.
MCIE: Multimodal LLM-Driven Complex Instruction Image Editing with Spatial Guidance
Feb 08, 2026Recent advances in instruction-based image editing have shown remarkable progress. However, existing methods remain limited to relatively simple editing operations, hindering real-world applications that require complex and compositional instructions. In this work, we address these limitations from the perspectives of architectural design, data, and evaluation protocols. Specifically, we identify two key challenges in current models: insufficient instruction compliance and background inconsistency. To this end, we propose MCIE-E1, a Multimodal Large Language Model-Driven Complex Instruction Image Editing method that integrates two key modules: a spatial-aware cross-attention module and a background-consistent cross-attention module. The former enhances instruction-following capability by explicitly aligning semantic instructions with spatial regions through spatial guidance during the denoising process, while the latter preserves features in unedited regions to maintain background consistency. To enable effective training, we construct a dedicated data pipeline to mitigate the scarcity of complex instruction-based image editing datasets, combining fine-grained automatic filtering via a powerful MLLM with rigorous human validation. Finally, to comprehensively evaluate complex instruction-based image editing, we introduce CIE-Bench, a new benchmark with two new evaluation metrics. Experimental results on CIE-Bench demonstrate that MCIE-E1 consistently outperforms previous state-of-the-art methods in both quantitative and qualitative assessments, achieving a 23.96% improvement in instruction compliance.
CoV: Chain-of-View Prompting for Spatial Reasoning
Jan 08, 2026Embodied question answering (EQA) in 3D environments often requires collecting context that is distributed across multiple viewpoints and partially occluded. However, most recent vision--language models (VLMs) are constrained to a fixed and finite set of input views, which limits their ability to acquire question-relevant context at inference time and hinders complex spatial reasoning. We propose Chain-of-View (CoV) prompting, a training-free, test-time reasoning framework that transforms a VLM into an active viewpoint reasoner through a coarse-to-fine exploration process. CoV first employs a View Selection agent to filter redundant frames and identify question-aligned anchor views. It then performs fine-grained view adjustment by interleaving iterative reasoning with discrete camera actions, obtaining new observations from the underlying 3D scene representation until sufficient context is gathered or a step budget is reached. We evaluate CoV on OpenEQA across four mainstream VLMs and obtain an average +11.56\% improvement in LLM-Match, with a maximum gain of +13.62\% on Qwen3-VL-Flash. CoV further exhibits test-time scaling: increasing the minimum action budget yields an additional +2.51\% average improvement, peaking at +3.73\% on Gemini-2.5-Flash. On ScanQA and SQA3D, CoV delivers strong performance (e.g., 116 CIDEr / 31.9 EM@1 on ScanQA and 51.1 EM@1 on SQA3D). Overall, these results suggest that question-aligned view selection coupled with open-view search is an effective, model-agnostic strategy for improving spatial reasoning in 3D EQA without additional training.
NextFlow: Unified Sequential Modeling Activates Multimodal Understanding and Generation
Jan 05, 2026We present NextFlow, a unified decoder-only autoregressive transformer trained on 6 trillion interleaved text-image discrete tokens. By leveraging a unified vision representation within a unified autoregressive architecture, NextFlow natively activates multimodal understanding and generation capabilities, unlocking abilities of image editing, interleaved content and video generation. Motivated by the distinct nature of modalities - where text is strictly sequential and images are inherently hierarchical - we retain next-token prediction for text but adopt next-scale prediction for visual generation. This departs from traditional raster-scan methods, enabling the generation of 1024x1024 images in just 5 seconds - orders of magnitude faster than comparable AR models. We address the instabilities of multi-scale generation through a robust training recipe. Furthermore, we introduce a prefix-tuning strategy for reinforcement learning. Experiments demonstrate that NextFlow achieves state-of-the-art performance among unified models and rivals specialized diffusion baselines in visual quality.
OmniSparse: Training-Aware Fine-Grained Sparse Attention for Long-Video MLLMs
Nov 18, 2025Existing sparse attention methods primarily target inference-time acceleration by selecting critical tokens under predefined sparsity patterns. However, they often fail to bridge the training-inference gap and lack the capacity for fine-grained token selection across multiple dimensions such as queries, key-values (KV), and heads, leading to suboptimal performance and limited acceleration gains. In this paper, we introduce OmniSparse, a training-aware fine-grained sparse attention framework for long-video MLLMs, which operates in both training and inference with dynamic token budget allocation. Specifically, OmniSparse contains three adaptive and complementary mechanisms: (1) query selection via lazy-active classification, retaining active queries that capture broad semantic similarity while discarding most lazy ones that focus on limited local context and exhibit high functional redundancy; (2) KV selection with head-level dynamic budget allocation, where a shared budget is determined based on the flattest head and applied uniformly across all heads to ensure attention recall; and (3) KV cache slimming to reduce head-level redundancy by selectively fetching visual KV cache according to the head-level decoding query pattern. Experimental results show that OmniSparse matches the performance of full attention while achieving up to 2.7x speedup during prefill and 2.4x memory reduction during decoding.
FPSAttention: Training-Aware FP8 and Sparsity Co-Design for Fast Video Diffusion
Jun 06, 2025Diffusion generative models have become the standard for producing high-quality, coherent video content, yet their slow inference speeds and high computational demands hinder practical deployment. Although both quantization and sparsity can independently accelerate inference while maintaining generation quality, naively combining these techniques in existing training-free approaches leads to significant performance degradation due to the lack of joint optimization. We introduce FPSAttention, a novel training-aware co-design of FP8 quantization and sparsity for video generation, with a focus on the 3D bi-directional attention mechanism. Our approach features three key innovations: 1) A unified 3D tile-wise granularity that simultaneously supports both quantization and sparsity; 2) A denoising step-aware strategy that adapts to the noise schedule, addressing the strong correlation between quantization/sparsity errors and denoising steps; 3) A native, hardware-friendly kernel that leverages FlashAttention and is implemented with optimized Hopper architecture features for highly efficient execution. Trained on Wan2.1's 1.3B and 14B models and evaluated on the VBench benchmark, FPSAttention achieves a 7.09x kernel speedup for attention operations and a 4.96x end-to-end speedup for video generation compared to the BF16 baseline at 720p resolution-without sacrificing generation quality.
ZPressor: Bottleneck-Aware Compression for Scalable Feed-Forward 3DGS
May 29, 2025Feed-forward 3D Gaussian Splatting (3DGS) models have recently emerged as a promising solution for novel view synthesis, enabling one-pass inference without the need for per-scene 3DGS optimization. However, their scalability is fundamentally constrained by the limited capacity of their encoders, leading to degraded performance or excessive memory consumption as the number of input views increases. In this work, we analyze feed-forward 3DGS frameworks through the lens of the Information Bottleneck principle and introduce ZPressor, a lightweight architecture-agnostic module that enables efficient compression of multi-view inputs into a compact latent state $Z$ that retains essential scene information while discarding redundancy. Concretely, ZPressor enables existing feed-forward 3DGS models to scale to over 100 input views at 480P resolution on an 80GB GPU, by partitioning the views into anchor and support sets and using cross attention to compress the information from the support views into anchor views, forming the compressed latent state $Z$. We show that integrating ZPressor into several state-of-the-art feed-forward 3DGS models consistently improves performance under moderate input views and enhances robustness under dense view settings on two large-scale benchmarks DL3DV-10K and RealEstate10K. The video results, code and trained models are available on our project page: https://lhmd.top/zpressor.
KMM: Key Frame Mask Mamba for Extended Motion Generation
Nov 10, 2024Human motion generation is a cut-edge area of research in generative computer vision, with promising applications in video creation, game development, and robotic manipulation. The recent Mamba architecture shows promising results in efficiently modeling long and complex sequences, yet two significant challenges remain: Firstly, directly applying Mamba to extended motion generation is ineffective, as the limited capacity of the implicit memory leads to memory decay. Secondly, Mamba struggles with multimodal fusion compared to Transformers, and lack alignment with textual queries, often confusing directions (left or right) or omitting parts of longer text queries. To address these challenges, our paper presents three key contributions: Firstly, we introduce KMM, a novel architecture featuring Key frame Masking Modeling, designed to enhance Mamba's focus on key actions in motion segments. This approach addresses the memory decay problem and represents a pioneering method in customizing strategic frame-level masking in SSMs. Additionally, we designed a contrastive learning paradigm for addressing the multimodal fusion problem in Mamba and improving the motion-text alignment. Finally, we conducted extensive experiments on the go-to dataset, BABEL, achieving state-of-the-art performance with a reduction of more than 57% in FID and 70% parameters compared to previous state-of-the-art methods. See project website: https://steve-zeyu-zhang.github.io/KMM
CIT: Rethinking Class-incremental Semantic Segmentation with a Class Independent Transformation
Nov 05, 2024


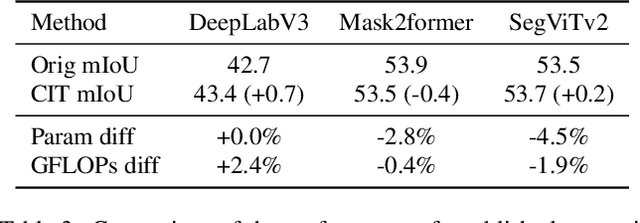
Class-incremental semantic segmentation (CSS) requires that a model learn to segment new classes without forgetting how to segment previous ones: this is typically achieved by distilling the current knowledge and incorporating the latest data. However, bypassing iterative distillation by directly transferring outputs of initial classes to the current learning task is not supported in existing class-specific CSS methods. Via Softmax, they enforce dependency between classes and adjust the output distribution at each learning step, resulting in a large probability distribution gap between initial and current tasks. We introduce a simple, yet effective Class Independent Transformation (CIT) that converts the outputs of existing semantic segmentation models into class-independent forms with negligible cost or performance loss. By utilizing class-independent predictions facilitated by CIT, we establish an accumulative distillation framework, ensuring equitable incorporation of all class information. We conduct extensive experiments on various segmentation architectures, including DeepLabV3, Mask2Former, and SegViTv2. Results from these experiments show minimal task forgetting across different datasets, with less than 5% for ADE20K in the most challenging 11 task configurations and less than 1% across all configurations for the PASCAL VOC 2012 dataset.