 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCIT: Rethinking Class-incremental Semantic Segmentation with a Class Independent Transformation
Nov 05, 2024


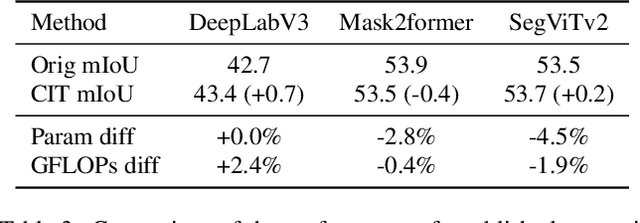
Class-incremental semantic segmentation (CSS) requires that a model learn to segment new classes without forgetting how to segment previous ones: this is typically achieved by distilling the current knowledge and incorporating the latest data. However, bypassing iterative distillation by directly transferring outputs of initial classes to the current learning task is not supported in existing class-specific CSS methods. Via Softmax, they enforce dependency between classes and adjust the output distribution at each learning step, resulting in a large probability distribution gap between initial and current tasks. We introduce a simple, yet effective Class Independent Transformation (CIT) that converts the outputs of existing semantic segmentation models into class-independent forms with negligible cost or performance loss. By utilizing class-independent predictions facilitated by CIT, we establish an accumulative distillation framework, ensuring equitable incorporation of all class information. We conduct extensive experiments on various segmentation architectures, including DeepLabV3, Mask2Former, and SegViTv2. Results from these experiments show minimal task forgetting across different datasets, with less than 5% for ADE20K in the most challenging 11 task configurations and less than 1% across all configurations for the PASCAL VOC 2012 dataset.
ESA: Annotation-Efficient Active Learning for Semantic Segmentation
Aug 24, 2024Active learning enhances annotation efficiency by selecting the most revealing samples for labeling, thereby reducing reliance on extensive human input. Previous methods in semantic segmentation have centered on individual pixels or small areas, neglecting the rich patterns in natural images and the power of advanced pre-trained models. To address these challenges, we propose three key contributions: Firstly, we introduce Entity-Superpixel Annotation (ESA), an innovative and efficient active learning strategy which utilizes a class-agnostic mask proposal network coupled with super-pixel grouping to capture local structural cues. Additionally, our method selects a subset of entities within each image of the target domain, prioritizing superpixels with high entropy to ensure comprehensive representation. Simultaneously, it focuses on a limited number of key entities, thereby optimizing for efficiency. By utilizing an annotator-friendly design that capitalizes on the inherent structure of images, our approach significantly outperforms existing pixel-based methods, achieving superior results with minimal queries, specifically reducing click cost by 98% and enhancing performance by 1.71%. For instance, our technique requires a mere 40 clicks for annotation, a stark contrast to the 5000 clicks demanded by conventional methods.
XLIP: Cross-modal Attention Masked Modelling for Medical Language-Image Pre-Training
Jul 28, 2024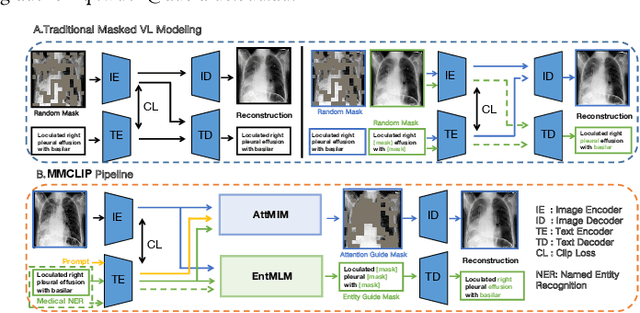
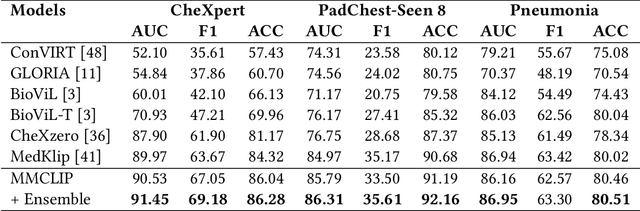
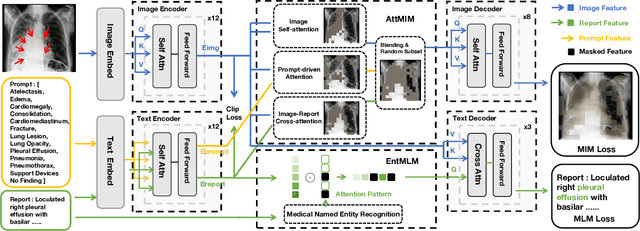

Vision-and-language pretraining (VLP) in the medical field utilizes contrastive learning on image-text pairs to achieve effective transfer across tasks. Yet, current VLP approaches with the masked modelling strategy face two challenges when applied to the medical domain. First, current models struggle to accurately reconstruct key pathological features due to the scarcity of medical data. Second, most methods only adopt either paired image-text or image-only data, failing to exploit the combination of both paired and unpaired data. To this end, this paper proposes a XLIP (Masked modelling for medical Language-Image Pre-training) framework to enhance pathological learning and feature learning via unpaired data. First, we introduce the attention-masked image modelling (AttMIM) and entity-driven masked language modelling module (EntMLM), which learns to reconstruct pathological visual and textual tokens via multi-modal feature interaction, thus improving medical-enhanced features. The AttMIM module masks a portion of the image features that are highly responsive to textual features. This allows XLIP to improve the reconstruction of highly similar image data in medicine efficiency. Second, our XLIP capitalizes unpaired data to enhance multimodal learning by introducing disease-kind prompts. The experimental results show that XLIP achieves SOTA for zero-shot and fine-tuning classification performance on five datasets. Our code will be available at https://github.com/White65534/XLIP
Decomposing Disease Descriptions for Enhanced Pathology Detection: A Multi-Aspect Vision-Language Matching Framework
Mar 12, 2024



Medical vision language pre-training (VLP) has emerged as a frontier of research, enabling zero-shot pathological recognition by comparing the query image with the textual descriptions for each disease. Due to the complex semantics of biomedical texts, current methods struggle to align medical images with key pathological findings in unstructured reports. This leads to the misalignment with the target disease's textual representation. In this paper, we introduce a novel VLP framework designed to dissect disease descriptions into their fundamental aspects, leveraging prior knowledge about the visual manifestations of pathologies. This is achieved by consulting a large language model and medical experts. Integrating a Transformer module, our approach aligns an input image with the diverse elements of a disease, generating aspect-centric image representations. By consolidating the matches from each aspect, we improve the compatibility between an image and its associated disease. Additionally, capitalizing on the aspect-oriented representations, we present a dual-head Transformer tailored to process known and unknown diseases, optimizing the comprehensive detection efficacy. Conducting experiments on seven downstream datasets, ours outperforms recent methods by up to 8.07% and 11.23% in AUC scores for seen and novel categories, respectively. Our code is released at \href{https://github.com/HieuPhan33/MAVL}{https://github.com/HieuPhan33/MAVL}.
Structure-Preserving Synthesis: MaskGAN for Unpaired MR-CT Translation
Aug 01, 2023



Medical image synthesis is a challenging task due to the scarcity of paired data. Several methods have applied CycleGAN to leverage unpaired data, but they often generate inaccurate mappings that shift the anatomy. This problem is further exacerbated when the images from the source and target modalities are heavily misaligned. Recently, current methods have aimed to address this issue by incorporating a supplementary segmentation network. Unfortunately, this strategy requires costly and time-consuming pixel-level annotations. To overcome this problem, this paper proposes MaskGAN, a novel and cost-effective framework that enforces structural consistency by utilizing automatically extracted coarse masks. Our approach employs a mask generator to outline anatomical structures and a content generator to synthesize CT contents that align with these structures. Extensive experiments demonstrate that MaskGAN outperforms state-of-the-art synthesis methods on a challenging pediatric dataset, where MR and CT scans are heavily misaligned due to rapid growth in children. Specifically, MaskGAN excels in preserving anatomical structures without the need for expert annotations. The code for this paper can be found at https://github.com/HieuPhan33/MaskGAN.
* Accepted to MICCAI 2023
BPKD: Boundary Privileged Knowledge Distillation For Semantic Segmentation
Jun 13, 2023Current approaches for knowledge distillation in semantic segmentation tend to adopt a holistic approach that treats all spatial locations equally. However, for dense prediction tasks, it is crucial to consider the knowledge representation for different spatial locations in a different manner. Furthermore, edge regions between adjacent categories are highly uncertain due to context information leakage, which is particularly pronounced for compact networks. To address this challenge, this paper proposes a novel approach called boundary-privileged knowledge distillation (BPKD). BPKD distills the knowledge of the teacher model's body and edges separately from the compact student model. Specifically, we employ two distinct loss functions: 1) Edge Loss, which aims to distinguish between ambiguous classes at the pixel level in edge regions. 2) Body Loss, which utilizes shape constraints and selectively attends to the inner-semantic regions. Our experiments demonstrate that the proposed BPKD method provides extensive refinements and aggregation for edge and body regions. Additionally, the method achieves state-of-the-art distillation performance for semantic segmentation on three popular benchmark datasets, highlighting its effectiveness and generalization ability. BPKD shows consistent improvements over various lightweight semantic segmentation structures. The code is available at \url{https://github.com/AkideLiu/BPKD}.
SegViTv2: Exploring Efficient and Continual Semantic Segmentation with Plain Vision Transformers
Jun 09, 2023We explore the capability of plain Vision Transformers (ViTs) for semantic segmentation using the encoder-decoder framework and introduce SegViTv2. In our work, we implement the decoder with the global attention mechanism inherent in ViT backbones and propose the lightweight Attention-to-Mask module that effectively converts the global attention map into semantic masks for high-quality segmentation results. Our decoder can outperform the most commonly-used decoder UpperNet in various ViT backbones while consuming only about 5\% of the computational cost. For the encoder, we address the concern of the relatively high computational cost in the ViT-based encoders and propose a Shrunk++ structure that incorporates edge-aware query-based down-sampling (EQD) and query-based up-sampling (QU) modules. The Shrunk++ structure reduces the computational cost of the encoder by up to $50\%$ while maintaining competitive performance. Furthermore, due to the flexibility of our ViT-based architecture, SegVit can be easily extended to semantic segmentation under the setting of continual learning, achieving nearly zero forgetting. Experiments show that our proposed SegViT outperforms recent segmentation methods on three popular benchmarks including ADE20k, COCO-Stuff-10k and PASCAL-Context datasets. The code is available through the following link: \url{https://github.com/zbwxp/SegVit}.