 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoSyncDiT: Cognitive Synchronous Diffusion Transformer for Movie Dubbing
Apr 14, 2026Movie dubbing aims to synthesize speech that preserves the vocal identity of a reference audio while synchronizing with the lip movements in a target video. Existing methods fail to achieve precise lip-sync and lack naturalness due to explicit alignment at the duration level. While implicit alignment solutions have emerged, they remain susceptible to interference from the reference audio, triggering timbre and pronunciation degradation in in-the-wild scenarios. In this paper, we propose a novel flow matching-based movie dubbing framework driven by the Cognitive Synchronous Diffusion Transformer (CoSync-DiT), inspired by the cognitive process of professional actors. This architecture progressively guides the noise-to-speech generative trajectory by executing acoustic style adapting, fine-grained visual calibrating, and time-aware context aligning. Furthermore, we design the Joint Semantic and Alignment Regularization (JSAR) mechanism to simultaneously constrain frame-level temporal consistency on the contextual outputs and semantic consistency on the flow hidden states, ensuring robust alignment. Extensive experiments on both standard benchmarks and challenging in-the-wild dubbing benchmarks demonstrate that our method achieves the state-of-the-art performance across multiple metrics.
Hierarchical Text-Guided Brain Tumor Segmentation via Sub-Region-Aware Prompts
Mar 22, 2026Brain tumor segmentation remains challenging because the three standard sub-regions, i.e., whole tumor (WT), tumor core (TC), and enhancing tumor (ET), often exhibit ambiguous visual boundaries. Integrating radiological description texts with imaging has shown promise. However, most multimodal approaches typically compress a report into a single global text embedding shared across all sub-regions, overlooking their distinct clinical characteristics. We propose TextCSP (text-modulated soft cascade architecture), a hierarchical text-guided framework that builds on the TextBraTS baseline with three novel components: (1) a text-modulated soft cascade decoder that predicts WT->TC->ET in a coarse-to-fine manner consistent with their anatomical containment hierarchy. (2) sub-region-aware prompt tuning, which uses learnable soft prompts with a LoRA-adapted BioBERT encoder to generate specialized text representations tailored for each sub-region; (3) text-semantic channel modulators that convert the aforementioned representations into channel-wise refinement signals, enabling the decoder to emphasize features aligned with clinically described patterns. Experiments on the TextBraTS dataset demonstrate consistent improvements across all sub-regions against state-of-the-art methods by 1.7% and 6% on the main metrics Dice and HD95.
DGRNet: Disagreement-Guided Refinement for Uncertainty-Aware Brain Tumor Segmentation
Mar 22, 2026Accurate brain tumor segmentation from MRI scans is critical for diagnosis and treatment planning. Despite the strong performance of recent deep learning approaches, two fundamental limitations remain: (1) the lack of reliable uncertainty quantification in single-model predictions, which is essential for clinical deployment because the level of uncertainty may impact treatment decision-making, and (2) the under-utilization of rich information in radiology reports that can guide segmentation in ambiguous regions. In this paper, we propose the Disagreement-Guided Refinement Network (DGRNet), a novel framework that addresses both limitations through multi-view disagreement-based uncertainty estimation and text-conditioned refinement. DGRNet generates diverse predictions via four lightweight view-specific adapters attached to a shared encoder-decoder, enabling efficient uncertainty quantification within a single forward pass. Afterward, we build disagreement maps to identify regions of high segmentation uncertainty, which are then selectively refined according to clinical reports. Moreover, we introduce a diversity-preserving training strategy that combines pairwise similarity penalties and gradient isolation to prevent view collapse. The experimental results on the TextBraTS dataset show that DGRNet favorably improves state-of-the-art segmentation accuracy by 2.4% and 11% in main metrics Dice and HD95, respectively, while providing meaningful uncertainty estimates.
Question-guided Visual Compression with Memory Feedback for Long-Term Video Understanding
Mar 16, 2026In the context of long-term video understanding with large multimodal models, many frameworks have been proposed. Although transformer-based visual compressors and memory-augmented approaches are often used to process long videos, they usually compress each frame independently and therefore fail to achieve strong performance on tasks that require understanding complete events, such as temporal ordering tasks in MLVU and VNBench. This motivates us to rethink the conventional one-way scheme from perception to memory, and instead establish a feedbackdriven process in which past visual contexts stored in the context memory can benefit ongoing perception. To this end, we propose Question-guided Visual Compression with Memory Feedback (QViC-MF), a framework for long-term video understanding. At its core is a Question-guided Multimodal Selective Attention (QMSA), which learns to preserve visual information related to the given question from both the current clip and the past related frames from the memory. The compressor and memory feedback work iteratively for each clip of the entire video. This simple yet effective design yields large performance gains on longterm video understanding tasks. Extensive experiments show that our method achieves significant improvement over current state-of-the-art methods by 6.1% on MLVU test, 8.3% on LVBench, 18.3% on VNBench Long, and 3.7% on VideoMME Long. The code will be released publicly.
Exploring the Temporal Consistency for Point-Level Weakly-Supervised Temporal Action Localization
Feb 05, 2026Point-supervised Temporal Action Localization (PTAL) adopts a lightly frame-annotated paradigm (\textit{i.e.}, labeling only a single frame per action instance) to train a model to effectively locate action instances within untrimmed videos. Most existing approaches design the task head of models with only a point-supervised snippet-level classification, without explicit modeling of understanding temporal relationships among frames of an action. However, understanding the temporal relationships of frames is crucial because it can help a model understand how an action is defined and therefore benefits localizing the full frames of an action. To this end, in this paper, we design a multi-task learning framework that fully utilizes point supervision to boost the model's temporal understanding capability for action localization. Specifically, we design three self-supervised temporal understanding tasks: (i) Action Completion, (ii) Action Order Understanding, and (iii) Action Regularity Understanding. These tasks help a model understand the temporal consistency of actions across videos. To the best of our knowledge, this is the first attempt to explicitly explore temporal consistency for point supervision action localization. Extensive experimental results on four benchmark datasets demonstrate the effectiveness of the proposed method compared to several state-of-the-art approaches.
Unlocking Prototype Potential: An Efficient Tuning Framework for Few-Shot Class-Incremental Learning
Feb 05, 2026Few-shot class-incremental learning (FSCIL) seeks to continuously learn new classes from very limited samples while preserving previously acquired knowledge. Traditional methods often utilize a frozen pre-trained feature extractor to generate static class prototypes, which suffer from the inherent representation bias of the backbone. While recent prompt-based tuning methods attempt to adapt the backbone via minimal parameter updates, given the constraint of extreme data scarcity, the model's capacity to assimilate novel information and substantively enhance its global discriminative power is inherently limited. In this paper, we propose a novel shift in perspective: freezing the feature extractor while fine-tuning the prototypes. We argue that the primary challenge in FSCIL is not feature acquisition, but rather the optimization of decision regions within a static, high-quality feature space. To this end, we introduce an efficient prototype fine-tuning framework that evolves static centroids into dynamic, learnable components. The framework employs a dual-calibration method consisting of class-specific and task-aware offsets. These components function synergistically to improve the discriminative capacity of prototypes for ongoing incremental classes. Extensive results demonstrate that our method attains superior performance across multiple benchmarks while requiring minimal learnable parameters.
Boosting Point-supervised Temporal Action Localization via Text Refinement and Alignment
Feb 01, 2026Recently, point-supervised temporal action localization has gained significant attention for its effective balance between labeling costs and localization accuracy. However, current methods only consider features from visual inputs, neglecting helpful semantic information from the text side. To address this issue, we propose a Text Refinement and Alignment (TRA) framework that effectively utilizes textual features from visual descriptions to complement the visual features as they are semantically rich. This is achieved by designing two new modules for the original point-supervised framework: a Point-based Text Refinement module (PTR) and a Point-based Multimodal Alignment module (PMA). Specifically, we first generate descriptions for video frames using a pre-trained multimodal model. Next, PTR refines the initial descriptions by leveraging point annotations together with multiple pre-trained models. PMA then projects all features into a unified semantic space and leverages a point-level multimodal feature contrastive learning to reduce the gap between visual and linguistic modalities. Last, the enhanced multi-modal features are fed into the action detector for precise localization. Extensive experimental results on five widely used benchmarks demonstrate the favorable performance of our proposed framework compared to several state-of-the-art methods. Moreover, our computational overhead analysis shows that the framework can run on a single 24 GB RTX 3090 GPU, indicating its practicality and scalability.
Multimodal Visual Surrogate Compression for Alzheimer's Disease Classification
Jan 29, 2026High-dimensional structural MRI (sMRI) images are widely used for Alzheimer's Disease (AD) diagnosis. Most existing methods for sMRI representation learning rely on 3D architectures (e.g., 3D CNNs), slice-wise feature extraction with late aggregation, or apply training-free feature extractions using 2D foundation models (e.g., DINO). However, these three paradigms suffer from high computational cost, loss of cross-slice relations, and limited ability to extract discriminative features, respectively. To address these challenges, we propose Multimodal Visual Surrogate Compression (MVSC). It learns to compress and adapt large 3D sMRI volumes into compact 2D features, termed as visual surrogates, which are better aligned with frozen 2D foundation models to extract powerful representations for final AD classification. MVSC has two key components: a Volume Context Encoder that captures global cross-slice context under textual guidance, and an Adaptive Slice Fusion module that aggregates slice-level information in a text-enhanced, patch-wise manner. Extensive experiments on three large-scale Alzheimer's disease benchmarks demonstrate our MVSC performs favourably on both binary and multi-class classification tasks compared against state-of-the-art methods.
Visual Marker Search for Autonomous Drone Landing in Diverse Urban Environments
Jan 16, 2026Marker-based landing is widely used in drone delivery and return-to-base systems for its simplicity and reliability. However, most approaches assume idealized landing site visibility and sensor performance, limiting robustness in complex urban settings. We present a simulation-based evaluation suite on the AirSim platform with systematically varied urban layouts, lighting, and weather to replicate realistic operational diversity. Using onboard camera sensors (RGB for marker detection and depth for obstacle avoidance), we benchmark two heuristic coverage patterns and a reinforcement learning-based agent, analyzing how exploration strategy and scene complexity affect success rate, path efficiency, and robustness. Results underscore the need to evaluate marker-based autonomous landing under diverse, sensor-relevant conditions to guide the development of reliable aerial navigation systems.
Teaching Prompts to Coordinate: Hierarchical Layer-Grouped Prompt Tuning for Continual Learning
Nov 15, 2025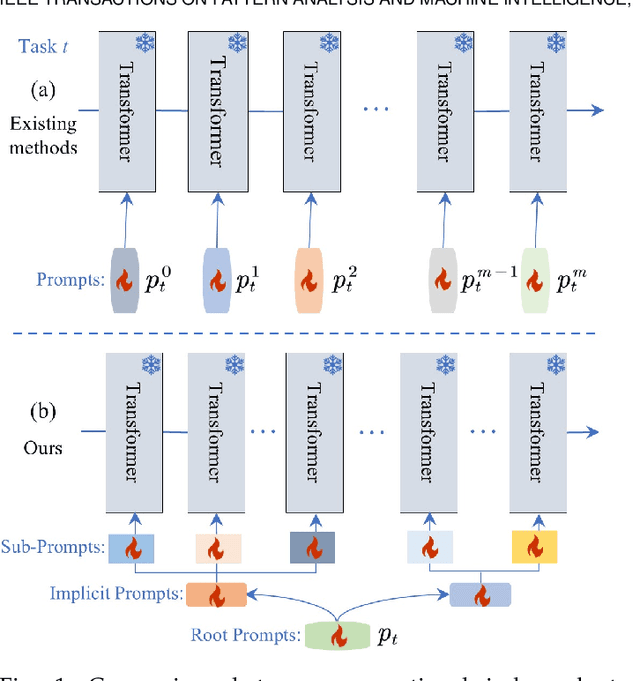
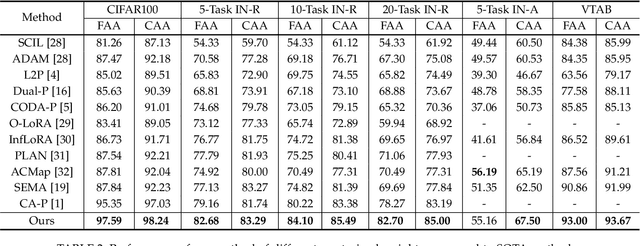
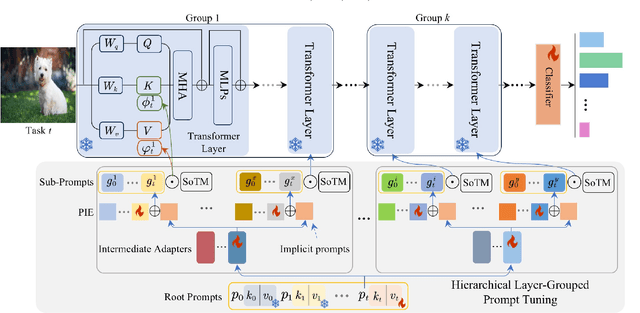
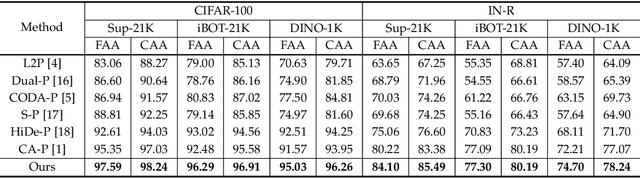
Prompt-based continual learning methods fine-tune only a small set of additional learnable parameters while keeping the pre-trained model's parameters frozen. It enables efficient adaptation to new tasks while mitigating the risk of catastrophic forgetting. These methods typically attach one independent task-specific prompt to each layer of pre-trained models to locally modulate its features, ensuring that the layer's representation aligns with the requirements of the new task. However, although introducing learnable prompts independently at each layer provides high flexibility for adapting to new tasks, this overly flexible tuning could make certain layers susceptible to unnecessary updates. As all prompts till the current task are added together as a final prompt for all seen tasks, the model may easily overwrite feature representations essential to previous tasks, which increases the risk of catastrophic forgetting. To address this issue, we propose a novel hierarchical layer-grouped prompt tuning method for continual learning. It improves model stability in two ways: (i) Layers in the same group share roughly the same prompts, which are adjusted by position encoding. This helps preserve the intrinsic feature relationships and propagation pathways of the pre-trained model within each group. (ii) It utilizes a single task-specific root prompt to learn to generate sub-prompts for each layer group. In this way, all sub-prompts are conditioned on the same root prompt, enhancing their synergy and reducing independence. Extensive experiments across four benchmarks demonstrate that our method achieves favorable performance compared with several state-of-the-art methods.