 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranscriptomic Models for Immunotherapy Response Prediction Show Limited Cross-cohort Generalisability
Apr 07, 2026Immune checkpoint inhibitors (ICIs) have transformed cancer therapy; yet substantial proportion of patients exhibit intrinsic or acquired resistance, making accurate pre-treatment response prediction a critical unmet need. Transcriptomics-based biomarkers derived from bulk and single-cell RNA sequencing (scRNA-seq) offer a promising avenue for capturing tumour-immune interactions, yet the cross-cohort generalisability of existing prediction models remains unclear.We systematically benchmark nine state-of-the-art transcriptomic ICI response predictors, five bulk RNA-seq-based models (COMPASS, IRNet, NetBio, IKCScore, and TNBC-ICI) and four scRNA-seq-based models (PRECISE, DeepGeneX, Tres and scCURE), using publicly available independent datasets unseen during model development. Overall, predictive performance was modest: bulk RNA-seq models performed at or near chance level across most cohorts, while scRNA-seq models showed only marginal improvements. Pathway-level analyses revealed sparse and inconsistent biomarker signals across models. Although scRNA-seq-based predictors converged on immune-related programs such as allograft rejection, bulk RNA-seq-based models exhibited little reproducible overlap. PRECISE and NetBio identified the most coherent immune-related themes, whereas IRNet predominantly captured metabolic pathways weakly aligned with ICI biology. Together, these findings demonstrate the limited cross-cohort robustness and biological consistency of current transcriptomic ICI prediction models, underscoring the need for improved domain adaptation, standardised preprocessing, and biologically grounded model design.
Hierarchical Text-Guided Brain Tumor Segmentation via Sub-Region-Aware Prompts
Mar 22, 2026Brain tumor segmentation remains challenging because the three standard sub-regions, i.e., whole tumor (WT), tumor core (TC), and enhancing tumor (ET), often exhibit ambiguous visual boundaries. Integrating radiological description texts with imaging has shown promise. However, most multimodal approaches typically compress a report into a single global text embedding shared across all sub-regions, overlooking their distinct clinical characteristics. We propose TextCSP (text-modulated soft cascade architecture), a hierarchical text-guided framework that builds on the TextBraTS baseline with three novel components: (1) a text-modulated soft cascade decoder that predicts WT->TC->ET in a coarse-to-fine manner consistent with their anatomical containment hierarchy. (2) sub-region-aware prompt tuning, which uses learnable soft prompts with a LoRA-adapted BioBERT encoder to generate specialized text representations tailored for each sub-region; (3) text-semantic channel modulators that convert the aforementioned representations into channel-wise refinement signals, enabling the decoder to emphasize features aligned with clinically described patterns. Experiments on the TextBraTS dataset demonstrate consistent improvements across all sub-regions against state-of-the-art methods by 1.7% and 6% on the main metrics Dice and HD95.
PersoPilot: An Adaptive AI-Copilot for Transparent Contextualized Persona Classification and Personalized Response Generation
Feb 04, 2026Understanding and classifying user personas is critical for delivering effective personalization. While persona information offers valuable insights, its full potential is realized only when contextualized, linking user characteristics with situational context to enable more precise and meaningful service provision. Existing systems often treat persona and context as separate inputs, limiting their ability to generate nuanced, adaptive interactions. To address this gap, we present PersoPilot, an agentic AI-Copilot that integrates persona understanding with contextual analysis to support both end users and analysts. End users interact through a transparent, explainable chat interface, where they can express preferences in natural language, request recommendations, and receive information tailored to their immediate task. On the analyst side, PersoPilot delivers a transparent, reasoning-powered labeling assistant, integrated with an active learning-driven classification process that adapts over time with new labeled data. This feedback loop enables targeted service recommendations and adaptive personalization, bridging the gap between raw persona data and actionable, context-aware insights. As an adaptable framework, PersoPilot is applicable to a broad range of service personalization scenarios.
PersoDPO: Scalable Preference Optimization for Instruction-Adherent, Persona-Grounded Dialogue via Multi-LLM Evaluation
Feb 04, 2026Personalization and contextual coherence are two essential components in building effective persona-grounded dialogue systems. These aspects play a crucial role in enhancing user engagement and ensuring responses are more relevant and consistent with user identity. However, recent studies indicate that open-source large language models (LLMs) continue to struggle to generate responses that are both contextually grounded and aligned with persona cues, despite exhibiting strong general conversational abilities like fluency and naturalness. We present PersoDPO, a scalable preference optimisation framework that uses supervision signals from automatic evaluations of responses generated by both closed-source and open-source LLMs to fine-tune dialogue models. The framework integrates evaluation metrics targeting coherence and personalization, along with a length-format compliance feature to promote instruction adherence. These signals are combined to automatically construct high-quality preference pairs without manual annotation, enabling a scalable and reproducible training pipeline. Experiments on the FoCus dataset show that an open-source language model fine-tuned with the PersoDPO framework consistently outperforms strong open-source baselines and a standard Direct Preference Optimization (DPO) variant across multiple evaluation dimensions.
Multimodal Visual Surrogate Compression for Alzheimer's Disease Classification
Jan 29, 2026High-dimensional structural MRI (sMRI) images are widely used for Alzheimer's Disease (AD) diagnosis. Most existing methods for sMRI representation learning rely on 3D architectures (e.g., 3D CNNs), slice-wise feature extraction with late aggregation, or apply training-free feature extractions using 2D foundation models (e.g., DINO). However, these three paradigms suffer from high computational cost, loss of cross-slice relations, and limited ability to extract discriminative features, respectively. To address these challenges, we propose Multimodal Visual Surrogate Compression (MVSC). It learns to compress and adapt large 3D sMRI volumes into compact 2D features, termed as visual surrogates, which are better aligned with frozen 2D foundation models to extract powerful representations for final AD classification. MVSC has two key components: a Volume Context Encoder that captures global cross-slice context under textual guidance, and an Adaptive Slice Fusion module that aggregates slice-level information in a text-enhanced, patch-wise manner. Extensive experiments on three large-scale Alzheimer's disease benchmarks demonstrate our MVSC performs favourably on both binary and multi-class classification tasks compared against state-of-the-art methods.
MTP: Exploring Multimodal Urban Traffic Profiling with Modality Augmentation and Spectrum Fusion
Nov 17, 2025With rapid urbanization in the modern era, traffic signals from various sensors have been playing a significant role in monitoring the states of cities, which provides a strong foundation in ensuring safe travel, reducing traffic congestion and optimizing urban mobility. Most existing methods for traffic signal modeling often rely on the original data modality, i.e., numerical direct readings from the sensors in cities. However, this unimodal approach overlooks the semantic information existing in multimodal heterogeneous urban data in different perspectives, which hinders a comprehensive understanding of traffic signals and limits the accurate prediction of complex traffic dynamics. To address this problem, we propose a novel Multimodal framework, MTP, for urban Traffic Profiling, which learns multimodal features through numeric, visual, and textual perspectives. The three branches drive for a multimodal perspective of urban traffic signal learning in the frequency domain, while the frequency learning strategies delicately refine the information for extraction. Specifically, we first conduct the visual augmentation for the traffic signals, which transforms the original modality into frequency images and periodicity images for visual learning. Also, we augment descriptive texts for the traffic signals based on the specific topic, background information and item description for textual learning. To complement the numeric information, we utilize frequency multilayer perceptrons for learning on the original modality. We design a hierarchical contrastive learning on the three branches to fuse the spectrum of three modalities. Finally, extensive experiments on six real-world datasets demonstrate superior performance compared with the state-of-the-art approaches.
Modeling and Optimizing User Preferences in AI Copilots: A Comprehensive Survey and Taxonomy
May 28, 2025AI copilots, context-aware, AI-powered systems designed to assist users in tasks such as software development and content creation, are becoming integral to modern workflows. As these systems grow in capability and adoption, personalization has emerged as a cornerstone for ensuring usability, trust, and productivity. Central to this personalization is preference optimization: the ability of AI copilots to detect, interpret, and align with individual user preferences. While personalization techniques are well-established in domains like recommender systems and dialogue agents, their adaptation to interactive, real-time systems like AI copilots remains fragmented and underexplored. This survey addresses this gap by synthesizing research on how user preferences are captured, modeled, and refined within the design of AI copilots. We introduce a unified definition of AI copilots and propose a phase-based taxonomy of preference optimization strategies, structured around pre-interaction, mid-interaction, and post-interaction stages. We analyze techniques for acquiring preference signals, modeling user intent, and integrating feedback loops, highlighting both established approaches and recent innovations. By bridging insights from AI personalization, human-AI collaboration, and large language model adaptation, this survey provides a structured foundation for designing adaptive, preference-aware AI copilots. It offers a holistic view of the available preference resources, how they can be leveraged, and which technical approaches are most suited to each stage of system design.
Ratas framework: A comprehensive genai-based approach to rubric-based marking of real-world textual exams
May 27, 2025



Automated answer grading is a critical challenge in educational technology, with the potential to streamline assessment processes, ensure grading consistency, and provide timely feedback to students. However, existing approaches are often constrained to specific exam formats, lack interpretability in score assignment, and struggle with real-world applicability across diverse subjects and assessment types. To address these limitations, we introduce RATAS (Rubric Automated Tree-based Answer Scoring), a novel framework that leverages state-of-the-art generative AI models for rubric-based grading of textual responses. RATAS is designed to support a wide range of grading rubrics, enable subject-agnostic evaluation, and generate structured, explainable rationales for assigned scores. We formalize the automatic grading task through a mathematical framework tailored to rubric-based assessment and present an architecture capable of handling complex, real-world exam structures. To rigorously evaluate our approach, we construct a unique, contextualized dataset derived from real-world project-based courses, encompassing diverse response formats and varying levels of complexity. Empirical results demonstrate that RATAS achieves high reliability and accuracy in automated grading while providing interpretable feedback that enhances transparency for both students and nstructors.
FlowDubber: Movie Dubbing with LLM-based Semantic-aware Learning and Flow Matching based Voice Enhancing
May 02, 2025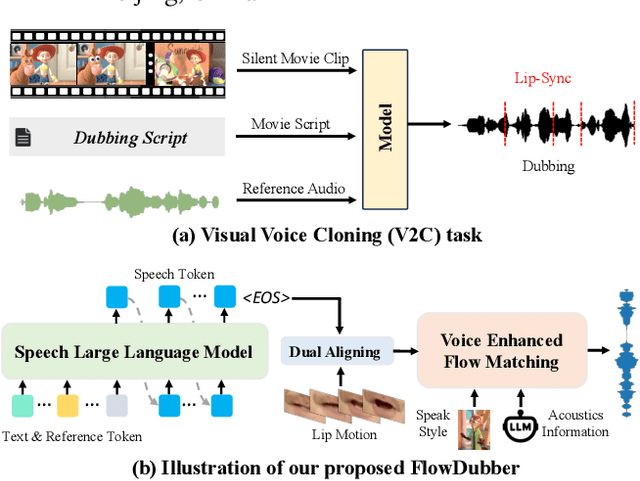
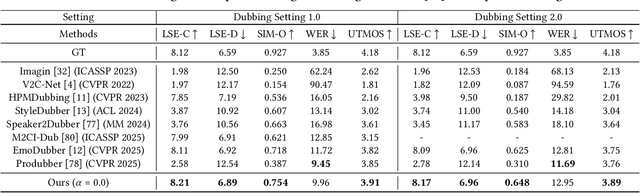
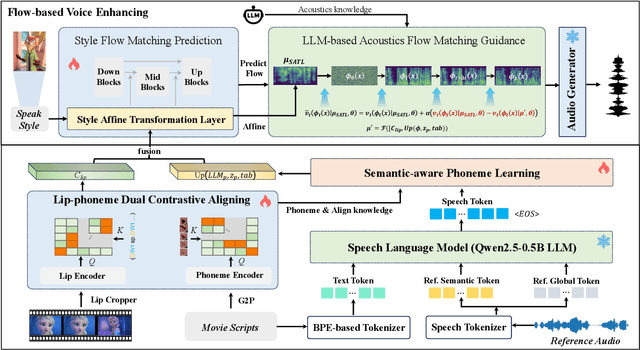
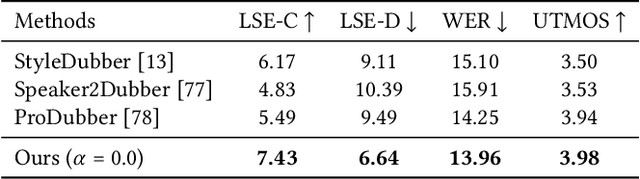
Movie Dubbing aims to convert scripts into speeches that align with the given movie clip in both temporal and emotional aspects while preserving the vocal timbre of a given brief reference audio. Existing methods focus primarily on reducing the word error rate while ignoring the importance of lip-sync and acoustic quality. To address these issues, we propose a large language model (LLM) based flow matching architecture for dubbing, named FlowDubber, which achieves high-quality audio-visual sync and pronunciation by incorporating a large speech language model and dual contrastive aligning while achieving better acoustic quality via the proposed voice-enhanced flow matching than previous works. First, we introduce Qwen2.5 as the backbone of LLM to learn the in-context sequence from movie scripts and reference audio. Then, the proposed semantic-aware learning focuses on capturing LLM semantic knowledge at the phoneme level. Next, dual contrastive aligning (DCA) boosts mutual alignment with lip movement, reducing ambiguities where similar phonemes might be confused. Finally, the proposed Flow-based Voice Enhancing (FVE) improves acoustic quality in two aspects, which introduces an LLM-based acoustics flow matching guidance to strengthen clarity and uses affine style prior to enhance identity when recovering noise into mel-spectrograms via gradient vector field prediction. Extensive experiments demonstrate that our method outperforms several state-of-the-art methods on two primary benchmarks. The demos are available at {\href{https://galaxycong.github.io/LLM-Flow-Dubber/}{\textcolor{red}{https://galaxycong.github.io/LLM-Flow-Dubber/}}}.
SDVPT: Semantic-Driven Visual Prompt Tuning for Open-World Object Counting
Apr 24, 2025
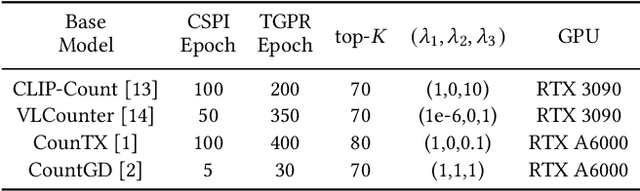

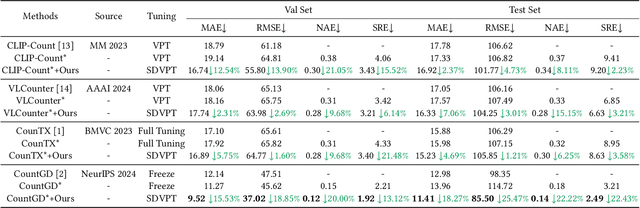
Open-world object counting leverages the robust text-image alignment of pre-trained vision-language models (VLMs) to enable counting of arbitrary categories in images specified by textual queries. However, widely adopted naive fine-tuning strategies concentrate exclusively on text-image consistency for categories contained in training, which leads to limited generalizability for unseen categories. In this work, we propose a plug-and-play Semantic-Driven Visual Prompt Tuning framework (SDVPT) that transfers knowledge from the training set to unseen categories with minimal overhead in parameters and inference time. First, we introduce a two-stage visual prompt learning strategy composed of Category-Specific Prompt Initialization (CSPI) and Topology-Guided Prompt Refinement (TGPR). The CSPI generates category-specific visual prompts, and then TGPR distills latent structural patterns from the VLM's text encoder to refine these prompts. During inference, we dynamically synthesize the visual prompts for unseen categories based on the semantic correlation between unseen and training categories, facilitating robust text-image alignment for unseen categories. Extensive experiments integrating SDVPT with all available open-world object counting models demonstrate its effectiveness and adaptability across three widely used datasets: FSC-147, CARPK, and PUCPR+.